
本文由清华大学、上海人工智能实验室、上海交通大学等机构联合完成。第一作者为上海 AI Lab 博士生樊钰辰,研究方向是 Agent 以及强化学习;通讯作者为清华大学周伯文教授。
此前的 Agentic Search RL 任务大多采用真实搜索引擎,导致训练效率低,速度慢,稳定性差。ZeroSearch 探索利用另一个模型提供信息的训练方法,取得了较好的表现。然而,模型依赖自身世界知识能够达到的上限,以及如何有效利用自身世界知识,降低幻觉仍然是一个值得探究的问题。为研究这些问题,本文引入 SSRL。
SSRL 利用结构化的 prompt 和 format reward,有效地提取出了模型中的 world knowledge,在各个 benchmark 上取得了更好的效果,有效地降低了模型的幻觉。本文接着探索训练 agent 是否需要真实环境的参与,并发现在接入真实搜索引擎后,经过 SSRL 训练的模型可以取得更好的效果,体现了 Sim2Real 的有效性。
SSRL 所有训练数据,训练细节,以及训练模型均已开源。

Github链接: https://github.com/TsinghuaC3I/SSRL
论文链接:https://arxiv.org/abs/2508.10874
一句话总结
本研究探索 SSRL,通过大语言模型 (LLM) 内部世界知识的利用,可以显著提升 Search Agent 的训练效率和稳定性。实验证明,该方法在多种基准测试中优于传统基于外部搜索引擎的方法,同时首次在 LLM 智能体领域实现了从模拟到真实 (Sim2Real) 的有效迁移。
一、动机
当前 RL 训练 Search Agent 主要有两种方式:
1. 全真实搜索 (Full-Real Search):直接调用商业搜索引擎 API 或检索增强生成 (RAG) 本地知识库
2. 半真实搜索 (Semi-Real Search):使用辅助 LLM 模拟搜索引擎行为
问题:
高昂成本:商业 API 调用费用昂贵,本地知识库加重 GPU 负担,且和真实场景存在差距
训练效率低下:多轮工具调用导致 rollout 效率降低
训练不稳定性:外部信息引入导致模型容易崩溃
非端到端训练:半真实搜索仍需额外微调步骤
综上所述,目前的 Search Agent 训练非常昂贵,耗时,且不稳定。
如何能够降低训练成本与训练时间,同时能够稳定地训练 Search Agent 呢?
面对这些问题,我们首先进行了对于 LLM 依赖自身世界知识所能达到的效果的上限的探究。我们利用 structured prompt 诱发 LLM 自发地利用世界知识,并且通过 pass@k 证明了其极高的上限。受此启发,我们尝试用 RL 进一步强化模型利用自身世界知识的能力,探索 SSRL 的效果。在此基础上,我们首次在 LLM Agent 领域提出 Sim2Real,并验证 SSRL 训练的模型在真实场景的泛化性。
二、观察:LLM 利用世界知识的上限
对应 Agentic Search 任务 Pass@K 上限很高
此前已经有研究证明 LLM 通过重复采样的方式可以在数学和代码取得极高的通过率,然而对于 LLM 利用自身世界知识回答 Search QA 类问题的上限还有待研究。我们首先使用一个 formatted instruction 来显式地利用模型内部知识(Self-Search)。

我们在大量的模型(包括 Qwen2.5,Qwen3,Llama3.1,Llama3.2)上进行了大量采样,实验结果显示,仅依赖模型内部知识,就可以在所有的 benchmark 上获得明显的效果提升,如 Llama-3.1-8B-Instruct 在 Bamboogle 上 pass@64 达到了 76% 的正确率,在 BrowseComp 上 pass@256 达到了 10% 的正确率。同时我们发现在这类任务上 Llama 系列效果远超 Qwen 系列,这和 math 上的结论恰恰相反。

Thinking 越多效果不一定越好
受启发于 Long-CoT LRM 的惊人表现,我们探究了 Long-CoT 对知识类的问题是否会有更好的表现。我们进行了三种 setting 的检验:
对于 reasoning model,我们对是否使用 thinking mode 进行了对比实验。
对于 sampling strategy,我们对比了是否使用 multi-turn generation 以及 reflection-based generation。
实验结果显示,过多的 thinking,或者 multi-turn 的生成在给定相同 token budget 的情况下未必可以取得更好的效果,这也和之前的 reasoning 工作中的结论相左。


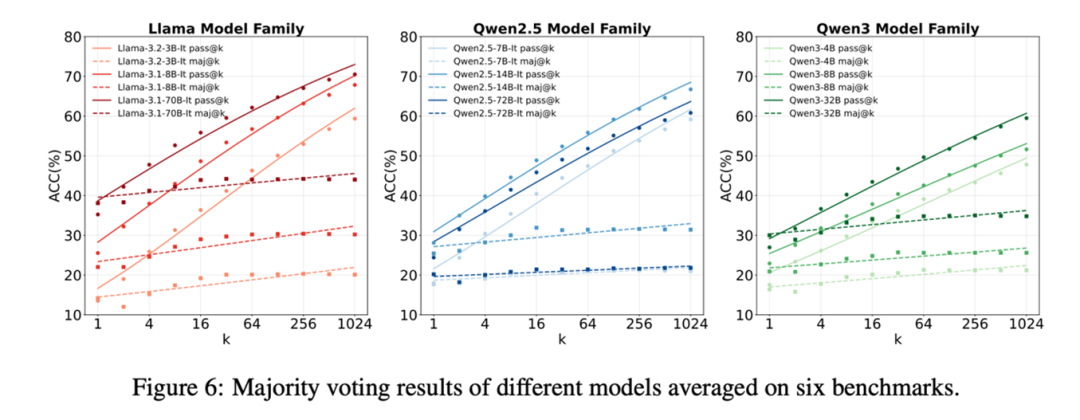
Pass@K 上限很高,但 Maj@N 达到上限很难
证明了 Self-Search 具有极高的上限后,我们尝试使用 Majority Voting 的方法进行投票选择。实验结果显示,仅仅依赖答案进行投票的方式无法逼近模型能力的上限,并且在增加参与 majority voting 的采样数量时,效果也不会获得进一步的提升。如何逼近 self-search 的 upper-bound 仍然是一个问题。
三、SSRL:自搜索强化学习
训练目标优化
标准的搜索 RL Search Agent 目标函数为:

由于 R(检索信息)来自策略本身,优化目标方程可以简化为一个标准的 GRPO 优化目标:

关键技术设计
1. 信息掩码(Information Masking)
和之前的 Search RL 工作一样,我们在训练时屏蔽 <information> 标签内的 token,从而强制模型基于查询和推理生成答案,而非简单复制。
2. 复合奖励函数
由于我们没有人为地干预模型的生成过程,因此需要一个 format reward 去规范模型的格式化输出,以更好地利用内部知识。同时,我们采用 outcome reward 防止 reward hacking,确保奖励的有效性。

实验结果
我们在 Llama 系列和 Qwen2. 5 系列上进行了训练,实验结果如下:
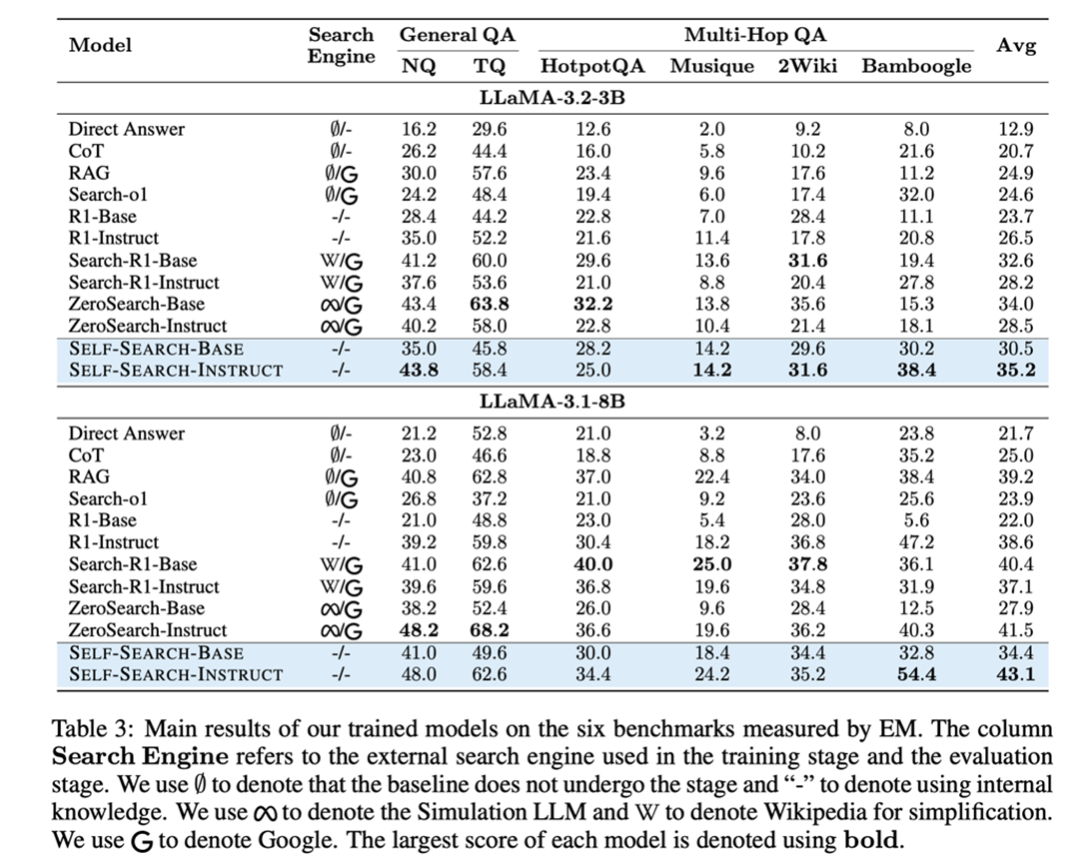
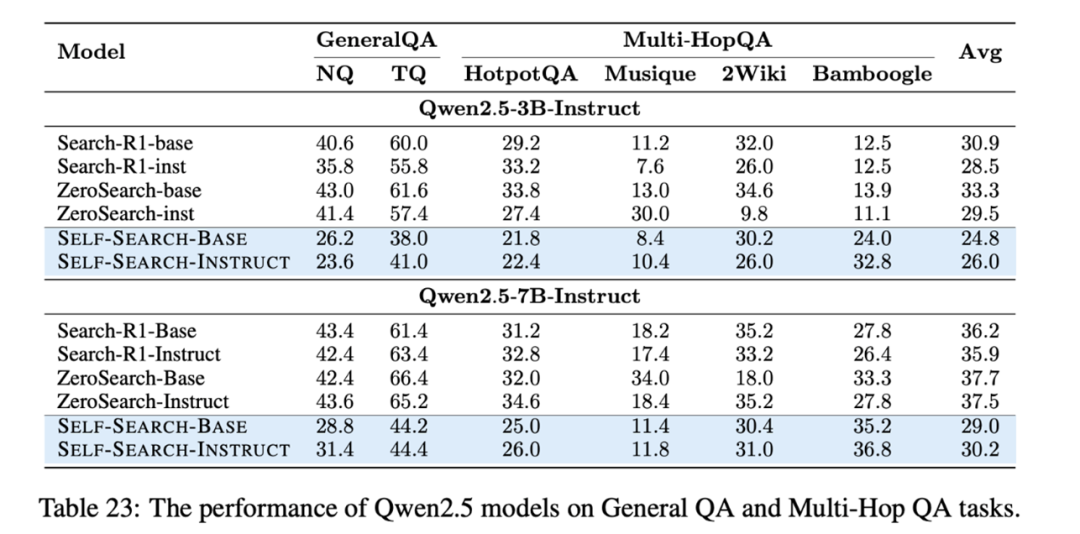
可以看到:
利用 SSRL 训练后的 Llama 系列模型比 Search-R1 和 ZeroSearch 这种依赖外部引擎训练的模型可以取得更好的效果,然而在 Qwen 系列上,效果还有一定的差距。
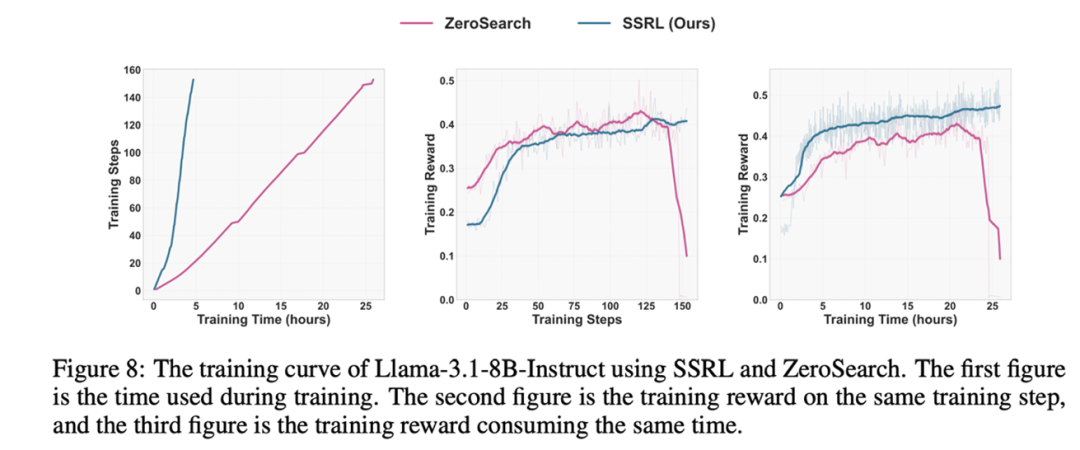
使用 SSRL 训练效率可以提升约 5.6 倍,并且在训练过程中,Training reward 持续增长,在训练 2000 多步时也并未观察到 collapse 现象。
相比于 Base model,Instruct model 表现出更好的能力,我们将其归因为 SFT 阶段的大量信息注入。
四、Sim2Real Generalization
由于 Search 任务是和真实世界高度相关的,因此能够结合真实搜索去实时地解决问题也是非常重要的。在这个工作中,我们探究了 SSRL 训练的模型是否具有在真实世界搜索并推理的能力,我们称为 Sim2Real。
替换 Self-Searched Knowledge 为 Online-Searched Information
首先我们进行实验,将前 K 个 Self-Searched Knowledge 用在线搜索获得的结果进行替换,我们发现
Sim2Real 会获得一定程度的效果提升,这显示了适当引入外部知识可以辅助模型思考。
随着 K 的增加,Sim2Real 的效果不会持续增长,这也显示了模型内部知识的一定优越性,即高度压缩性和灵活性,对于同样的一个问题,模型 self-search 的知识可能更加贴合。


结合 Self-Generated Knowledge 和 Real-world Knowledge
此前我们已经证明了,真实世界的知识和模型生成的知识都各有其优越性,如何有机地在 SSRL 的背景下利用他们也是一个值得考虑的问题。我们首次提出 entropy-guided search,我们首先提取出 search content,如果呈现熵增趋势,表明模型具有不确定性,我们应当寻求外部工具的帮助,如果熵减,则使用模型生成的知识。实验结果如下:

实验结果显示,Search 次数相比于之前减少了 20%-42%,而实验效果可以取得一个 comparable 的表现,但这只是一个初步的尝试,更精细的结合方法仍是一个问题。
五、SSRL 和 TTRL 的结合
我们尝试 SSRL 和 TTRL 相结合,证明 SSRL 的泛化性和有效性。可以发现,当使用 TTRL 时,相比于 GRPO-based SSRL,我们可以取得更好的效果,甚至可以获得 67% 的效果提升。

甚至在最为困难的 BrowseComp 上,我们仍然能够获得稳定的增长。然而我们观察到,使用 TTRL 时,模型会变得过于 confident,模型塌缩到每个问题只会搜索一次,且模型会学会一个捷径,即先指出最后的答案,再通过 search 去 verify。此外,TTRL 也非常容易崩溃,Training reward 会极速下降到 0。


© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










