点击下方卡片,关注“具身智能之心”公众号
作者丨Galaxea Team
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。

核心贡献总览
Galaxea开放世界数据集是一个在真实人类生活与工作环境中记录的大规模、多样化机器人行为集合。所有演示数据均采用统一的机器人实体进行采集,并配有精确的子任务级语言标注,以同时支持训练与评估。基于此数据集,提出G0双系统框架:通过视觉语言模型(VLM)进行多模态规划,并与视觉-语言-动作模型(VLA)协同实现细粒度执行。G0采用三阶段课程训练:跨实体预训练、单实体预训练和任务特定后训练。通过涵盖桌面操作、少样本学习和长程移动操作的综合基准测试,方法展现出显著有效性。特别值得注意的是,单实体预训练阶段与Galaxea开放世界数据集的结合对实现强劲性能具有关键作用。本工作聚焦机器人视觉-语言-动作(VLA)模型的落地痛点——大规模高质量开放世界机器人数据稀缺与模型泛化能力不足,提出两大核心成果:
Galaxea Open-World Dataset:首个在真实人类生活/工作场景中采集的大规模机器人行为数据集,解决现有数据集场景单一、本体不一致、标注粗糙的问题; G0双系统框架:耦合“慢思考”的视觉-语言模型(G0-VLM)与“快执行”的VLA模型(G0-VLA),通过三阶段训练策略实现复杂任务的规划与精准执行,在桌面操作、少样本学习、长程移动操作等基准测试中表现优异。
Galaxea Open-World Dataset
该数据集是G0模型性能的基础,核心设计围绕“真实场景适配”与“模型训练友好性”展开,关键特征如下:
数据采集基础
统一机器人本体:所有数据通过Galaxea R1 Lite移动双臂机器人采集(Figure 2a),该机器人具备23个自由度(双臂各6DoF、躯干3DoF、全向底盘6DoF),搭载头部立体RGB相机(场景全局感知)与手腕RGB-D相机(精细操作感知),负载能力达5kg,可在狭窄空间灵活移动;

真实场景覆盖:在11个物理站点的50个独特场景中采集(Figure 2b),涵盖住宅、零售、餐饮、办公四大核心场景(Figure 3a),避免现有数据集“实验室受控环境”的局限;

数据规模与标注:总计500小时数据、10万条演示轨迹,覆盖150类任务、1600种物体、58种操作技能(如拾取-放置、全身协同操作),并以2Hz频率标注细分子任务指令,实现“视觉-语言-动作”的精准对齐。
数据多样性特征
数据集通过多维度多样性保证模型泛化能力,关键统计可见Figure 3-5:
场景与物体分布:住宅场景占比最高(50.8%),其次是办公场景(33.2%)(Figure 3a);物体覆盖家电、日用品、家具、食品等10余大类(Figure 3b),对unsafe/难重复操作的物体(如食物)采用高保真复制品; 任务属性:任务时长呈“中等为主、长尾分布”(Figure 4a),既包含短时间精细操作,也包含长程复杂任务(如整理床铺);任务复杂度(子任务数量)差异显著(Figure 4b),从单步动作到多步协同操作均有覆盖;

行为模式:操作中“仅手臂”“躯干+手臂”“全身协同”的动作占比均衡(Figure 5a),技能分布呈长尾特征(Figure 5b),既包含高频基础动作(拾取),也包含特殊技能(如打开冰箱、倾倒水壶)。

与现有数据集的差异
相较于BridgeData V2、Open-X-Embodiment等主流数据集,该数据集的核心优势在于:
单一本体一致性:避免多本体数据导致的动作空间混乱,让模型专注学习“感知-动作”映射; 细分子任务标注:不同于现有数据集的“任务级标注”,子任务级标注(如“打开洗衣机门→放入脏衣服→关闭门”,Figure 6)为VLA模型提供更精准的语言-动作对齐信号;

完全开放世界场景:数据采集无预设脚本,还原人类真实生活中的任务场景(如杂乱桌面整理、日常做饭),解决“实验室数据与真实环境脱节”的 domain gap 问题。
G0双系统框架与训练策略
G0的核心设计灵感来自Kahneman的“双系统理论”:System 2(慢思考)负责规划,System 1(快执行)负责反应,两者异步运行(G0-VLM以15Hz规划,G0-VLA以200Hz控制),平衡“规划合理性”与“执行实时性”(Figure 1)。

双系统分工
G0-VLM(System 2:慢思考):接收人类高层指令(如“帮我整理床铺”),结合场景视觉观察,将其分解为可执行的子任务序列(如“走向床铺→抬起躯干抓被子→向后倾斜躯干→抚平被子”),并传递给G0-VLA; G0-VLA(System 1:快执行):接收G0-VLM的子任务指令、实时视觉观察(3路相机)与机器人本体状态(关节角度、位置等),生成连续动作序列(动作块),实现闭环控制。
G0-VLA的三阶段训练策略
为兼顾“通用知识”与“特定本体适配”,设计递进式训练流程(Figure 7),每个阶段目标与方法明确:

阶段1:跨本体预训练(获取通用世界知识)
目标:让模型学习机器人操作的通用规律(如“拾取物体需先闭合夹爪”),而非特定机器人的运动特性; 数据:混合1000小时Open-X-Embodiment(OXE)数据、500小时Galaxea数据集(仅用任务级描述)、200小时内部未标注数据; 训练方式:仅训练VLM组件,采用FAST分词器将连续动作转换为离散token,以自回归交叉熵损失训练VLM预测下一个动作token,公式如下:

其中为离散动作token序列,为视觉观察,为语言指令,为本体状态;VLM基于PaLiGemma初始化,包含SigLIP视觉编码器与Transformer语言解码器。
阶段2:单一本体预训练(适配目标机器人)
目标:让模型掌握Galaxea R1 Lite的运动学、动力学特性,提升动作精度与语言-动作对齐能力; 数据:使用Galaxea数据集的完整标注数据(含子任务指令、动作轨迹); 训练方式:在阶段1 VLM基础上新增“动作专家”模块,以流匹配损失(flow-matching loss)训练连续动作生成,目标函数与损失函数如下:
目标函数(最大化动作条件概率):
流匹配损失(最小化预测流与目标流的差异):
其中为带噪声的插值动作,为模型预测流,为动作轨迹导出的目标流。
阶段3:任务特定后训练(精修复杂技能)
目标:针对特定复杂任务(如微波炉操作、积木堆叠)优化模型性能; 数据:每个任务仅用最多100条高质量轨迹,避免过拟合; 训练方式:沿用阶段2的流匹配损失,仅微调动作专家与VLM的顶层参数。
G0-VLM的训练
G0-VLM基于开源Qwen2.5-VL初始化,通过“标注数据+合成指令”进行指令微调:
数据构建:从Galaxea数据集中采样 episodes,优先选择“子任务结束时刻”“夹爪状态变化”等关键帧,输入1秒间隔的历史视觉观察与动作,形成包含“任务名称-历史观察-子任务指令”的数据集; 合成人类指令:用DeepSeek-R1推理LLM,基于的任务名称、子任务序列,生成人类风格的高层指令(如“我想坐下,能帮我拉开椅子吗?”)与机器人回应(如“我正在处理!”),增强模型的人机交互适配性。
实验评估与关键发现
实验围绕“数据集有效性”与“G0模型性能”展开,设计四大基准任务(桌面整理、微波炉操作、整理床铺、积木堆叠,Figure 8),核心发现如下:

G0-VLA的性能评估
针对“预训练如何影响VLA性能”的核心问题,设计多组对比实验:
预训练权重的影响

对比5种模型配置(G0-Scratch:无预训练;G0-Stage1:仅跨本体预训练;G0-Stage2-200h/400h:仅单一本体预训练;G0-Full:Stage1+Stage2-400h;π0:基线模型),关键结论:
G0-Full表现最优:平均任务进度得分最高,尤其在“拾取-放置”类任务(桌面整理、微波炉操作)中优势显著,说明跨本体预训练的通用知识与单一本体预训练的适配知识可互补; 单一本体预训练不可或缺:G0-Stage2(200h/400h)在语言跟随、动作一致性、全身控制(整理床铺)上表现优于G0-Stage1,而G0-Stage1甚至弱于部分无预训练模型,说明跨本体数据与目标机器人的本体差距过大会导致知识负迁移; 数据量正向相关:G0-Stage2-400h性能优于200h,验证数据集规模对模型精度的提升作用。
少样本迁移能力
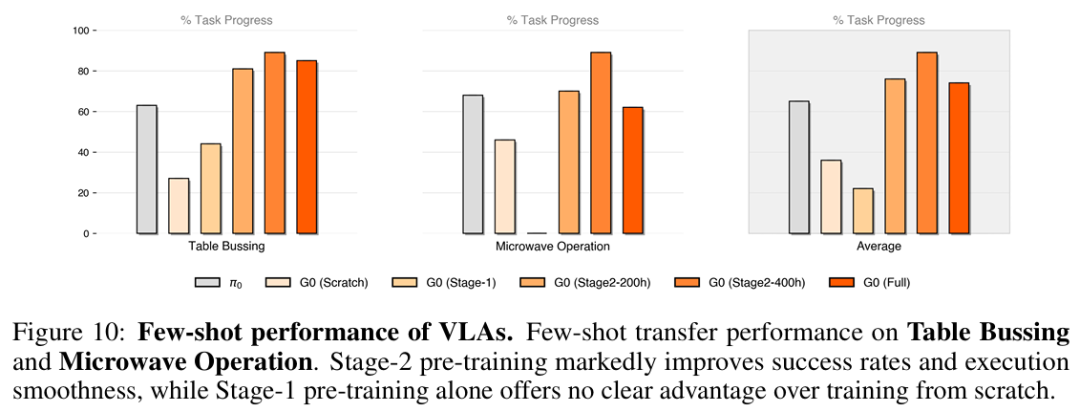
用仅20条轨迹微调模型(少样本场景),发现:
G0-Stage2系列模型迁移效果最好:任务进度得分显著高于G0-Scratch与G0-Stage1,且动作更平滑稳定; 跨本体预训练无优势:G0-Stage1在少样本场景下与G0-Scratch差异极小,说明跨本体知识无法快速适配特定机器人,而单一本体预训练的“感知-动作”映射可高效迁移。
本体特定动作的适配性

以“整理床铺”(需全身协同,依赖特定机器人的躯干/底盘控制)为长程任务,分析单技能进度得分:
G0-Stage2显著提升本体控制能力:在“走向床铺”“躯干抬起抓被子”等技能上得分远超G0-Stage1与π0,甚至优于G0-Scratch; 跨本体预训练有害:G0-Stage1在底盘控制、躯干倾斜等技能上表现差于G0-Scratch,原因是OXE数据集的机器人本体与Galaxea R1 Lite差异大,导致学到的动作模式与目标机器人冲突。
G0-VLM的性能评估

对比G0-VLM与主流VLM(Gemini-2.5-pro、Qwen2.5-VL-7B/32B/72B)的“指令准确率”(生成的子任务是否可被VLA执行),关键结论:
G0-VLM准确率领先50%以上:在整理床铺上准确率达78.2%,桌面整理达83.3%,远超基线模型; 领域微调是关键:未微调的通用VLM(如Qwen2.5-VL-72B)在机器人任务中准确率低,说明通用视觉-语言理解需结合机器人任务数据微调,才能生成可执行的子任务指令。
参考
[1]Galaxea Open-World Dataset and G0Dual-System VLA Model











