

智东西9月10日消息,今日上午,阿布扎比穆罕默德·本·扎耶德人工智能大学(MBZUAI)联合AI创企G42推出的新低成本推理模型K2-Think,相关论文已arXiv预印本平台发表,昨天下午模型在Hugging Face、GitHub上开源。
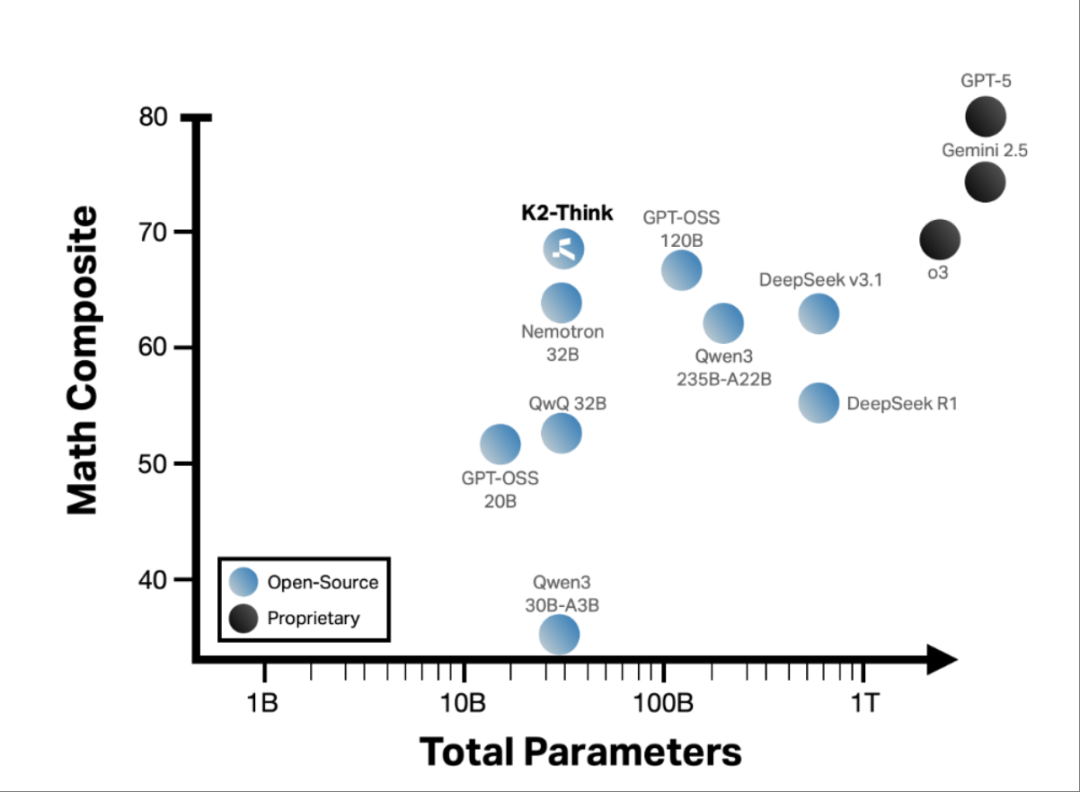
K2-Think有320亿个参数,基于阿里巴巴的开源模型Qwen 2.5构建,性能超过参数规模是其20倍的OpenAI和DeepSeek旗舰推理模型。
值得一提的是,研究人员将K2-Think部署在Cerebras晶圆级芯片WSE系统,WSE每秒可交付约2000个token,相比在NVIDIA H100/H200 GPU等常规部署环境中观测到的标称每秒200个token,性能提升了10倍。


Hugging Face地址:
https://huggingface.co/LLM360/K2-Think
GitHub地址:
https://github.com/MBZUAI-IFM/K2-Think-SFT
https://github.com/MBZUAI-IFM/K2-Think-Inference
https://www.k2think.ai/
MBZUAI校长兼首席AI研究员Eric Xing在接受外媒WIRED采访时透露,K2-Think是使用数千个GPU开发的,最终的训练过程涉及200到300块芯片。
K2-Think并非一个完整的大语言模型,是专门用于推理的模型,能够通过模拟推理方式来回答复杂问题,而不是快速综合信息来提供信息输出,Xing提到,他们在未来几个月将K2-Think整合到一个完整的大模型中。
在复杂数学领域,K2-Think在AIME 2024、AIME 2025、HMMT 2025 和 Omni-MATH-HARD四个基准测试中的平均得分为67.99分,超过规模更大的DeepSeek V3.1 671B、GPT-OSS 120B模型。

编程能力上,K2-Think在开源代码能力基准LiveCodeBench上获得63.97分,超越了规模相近的同类模型GPT-OSS 20B、Qwen3-30B-A3B。
在用于评估大模型将复杂科学问题转化为可执行代码能力的SciCode基准测试中,K2-Think获得39.2分排名第二,与第一名的Qwen3 235BA22B仅有0.1分之差。
在科学推理方面,模型在GPQA-Diamond基准测试中的表现为71.08,表现优于除OpenReasoning-Nemotron-32B、GPT-OSS 120B之外的大多数开源模型。
在监督微调阶段,K2-Think使用思维链对基础模型进行监督微调。研究人员采用了现有的AM-Thinking-v1-Distilled数据集,该数据集由CoT推理痕迹和指令/响应对组成,提示来自数学推理、代码生成、科学推理、指令遵循和一般聊天等任务。他们评估发现,SFT模型在各个采样预算下均优于基础模型。

在可验证奖励强化学习阶段,可验证奖励强化学习通过直接优化模型生成的正确性,降低了基于人类反馈强化学习(RLHF)基于偏好对齐的复杂性和成本。因此研究人员使用了Guru数据集,该数据集包含数学、编程、科学、逻辑、模拟和表格六个领域任务、近92000个可验证问题。
在测试时间改进阶段,为了进一步提升模型性能,研究人员开发了测试时框架,为训练后的推理模型提供结构化输入,包括推理前的Agent规划,即“先计划后思考”,以及使用Best-of-N采样的测试时扩展。

▲模型从输入到最终响应的信息流
第四阶段是部署,在具有挑战性的数学证明或多步骤编码问题中,一个典型复杂推理任务一般会生成32000个token的响应。在NVIDIA H100上,这可以在不到3分钟的时间内完成,在WSE上,同样32000个token的生成任务只需16秒。
这是因为GPU必须在每个token生成时不断将权重从高带宽内存传输到GPU核心,而WSE将所有模型权重存储在海量片上内存中,充分利用每秒25PB的片上内存带宽,比最新NVIDIA B200 GPU提供的0.008PB/s高出3000多倍。
K2-Think模型的性能证明,320亿参数规模的模型经过后期训练,能够生成较长的推理思路链,并结合相对较少的测试时间计算,可以实现小模型与参数数量级更大的模型相媲美的能力。












