让机器人,凭借「与生俱来」的常识(而非死记硬背的训练),在完全陌生的环境中高效、智能地寻找目标。
正是当下最前沿的“零样本目标导航”(Zero-Shot ObjectNav,ZSON),为机器人赋予的能力。
然而,让机器学会“动脑筋”并非易事。早期系统常陷入两种窘境:要么严重依赖预训练模型提供的语义线索;要么效率低下且容易被视觉错觉所欺骗。
正是在这一背景下,两项惊艳的工作横空出世,分别从 “决策大脑” 和 “感知眼睛” 两个维度,突破了零样本导航的瓶颈!

左:ApexNav;右:VLFM

VLFM
第一篇是来自波士顿动力AI研究所,获得了ICRA24 best paper的经典工作——VLFM。它巧妙地利用视觉-语言模型(VLM),直接将眼前的RGB图像与“目标词”进行关联,生成一幅“语义价值地图”,清晰地标注出环境中哪些区域更“值得探索”。
其核心的“置信度加权融合”机制,让系统更信任视野中心的清晰观测,而淡化边缘模糊信息的影响,从而生成稳定准确的导航信号。
之前我们以VLFM为例,从0实现了VLN导航。相关部署教程可以阅读:【硬核教程】从0实现VLN导航:以波士顿动力VLFM为例,原理+代码全面解析「视觉-语言」模型,各位读者可以综合两篇文章一起阅读,分别从 原理&实现 角度,帮助大家对这篇经典工作有更深的认识和理解。
背景
(1)人类如何在未知的环境中导航?
人类通常依赖于认知的地图和内部知识的组合。这种内部知识通常是语义知识的积累,可以用来推断空间的布局,包括特定对象的位置和几何配置。
根据上下文,自然语言可以进一步增强这种先验语义知识。例如,我们知道厕所和淋浴通常在浴室里,通常位于卧室附近。
(2)开发类人导航的机器人
模仿人类推理过程的基础模型可能是无价的。因为zero-shot模型可以促进语义导航,而无需任何特定于任务的训练或微调。
zero-shot方法提供了提高可解释性的中间表示。LLM、VLM的卓越泛化性能为视野外场景信息的语义推理提供了独立于任务的解决方案。

(3)视觉语言边界地图(VLFM)的提出
这是一种zero-shot方法,用于目标驱动的语义导航到一个新环境中的一个看不见的物体。利用视觉语义线索会引导机器人朝着比贪婪的基于边界的探索更有效地探索环境的目标前进。
问题定义
这项语义导航任务鼓励机器人基于高级语义概念来理解和导航环境,例如它所在的房间类型或它看到的物体类型,而不是仅仅依赖几何线索。
机器人只能访问以自我为中心的RGB-D相机和里程计传感器,该传感器提供其当前的向前和水平距离以及相对于其起始姿势的方向。
动作空间由以下离散动作组成:前进(0.25m)、左转(30度)、右转(30度)、抬头(30度)、低头(30度)、停止。如果在500步或更少的步骤中,在目标对象的任何实例的1米内调用停止,则被定义为成功完成任务。
整体框架
三阶段框架结构:初始化、探索和目标导航。
初始化阶段,机器人原地旋转一整圈,以建立其边界和值地图,这对后续的探索阶段至关重要。
探索阶段,机器人不断更新边界和值地图,以创建边界航路点,并选择最有价值的航路点来定位指定的目标对象类别并导航到该类别。一旦它检测到一个目标对象实例,它就转换到目标导航阶段。
在目标导航阶段,机器人只是导航到检测到的目标物体上最近的点,并在足够接近时触发停止。

前沿航路点生成
(1)利用深度和里程计观测来构建2D障碍物地图。
(2)为了识别障碍位置,将当前深度图像转换为点云,过滤掉任何太短或太高而不能被认为是障碍的点,将这些点转换为全局框架,然后将它们投影到2D网格上。
(3)然后,识别分隔已探索和未探索区域的每个边界,将其中点设置为潜在的前沿航路点。
(4)当机器人探索该区域时,边界的数量和位置将会变化,直到整个环境都被探索完并且不再有边界存在。如果机器人在这一点上没有检测到目标对象,它将简单地触发STOP来结束。
价值地图生成
(1)先创建FOV锥形mask。
置信度通道专用于处理历史观测与当前观测的重叠区域。它为每个像素分配一个置信度得分,该得分取决于像素在FOV锥形mask(相机视野)中的位置:光轴中心最高(1),视野边缘最低(0);

(2)使用BLIP-2,计算当前RGB图像和文本提示之间的余弦相似性分数,以量化其在定位目标对象时的语义相关性;
(3)使用深度图像,更新mask以排除FOV中被障碍物遮挡的区域;
(4)使用加权平均来更新先前语义值和置信度得分;
(5)使用价值地图对每个前沿进行评估,选择价值最高的前沿作为下一个探索的前沿;
(6)目标检测:利用成熟的检测器和分割器,以确定目标对象上最接近机器人当前位置的点,该点然后被用作要导航到的目标航路点。

路径点导航
(1)初始化后,机器人总是由前沿航路点或目标航路点来导航,这取决于是否已经检测到目标物体。
(2)采用点目标导航(PointNav),出发点在于其速度和易用性,特别是当航路点位于可导航区域之外时(例如,当航路点在目标物体上时,该目标物体本身也可能在不同的障碍物上),因为目标的可导航性不影响策略或其观察。
实验
性能基准测试
在 Habitat 仿真器的三个标准数据集(Gibson, HM3D, MP3D)上,VLFM 在 ObjectNav 任务中的表现均超越了所有现有的零样本方法,并在部分数据集上优于需要任务特定训练的有监督方法。
零样本对比
VLFM 在 SPL 和 SR 两项指标上全面领先。例如,在 Gibson 上相比次优的零样本方法 SemUtil,SPL 绝对提升达 11.7%;在 HM3D 和 MP3D 上也分别领先 8.1% 和 3.3%。

与有监督方法对比:
在 Gibson 和 MP3D 上,VLFM 的 SPL 甚至超过了 SemExp、PONI 等需要大量任务特定训练的方法,确立了新的性能标杆。在 HM3D 上,其 SPL 也优于除 PIRLNav(使用了 7.7 万条人类演示数据)外的所有方法,凸显了其零样本泛化的强大能力。
局限性分析:
性能差异部分归因于数据集特性。VLFM 在处理需要跨楼层导航(如上下楼梯)的任务时会失败,这是因为其依赖于 2D 平面地图,无法处理高程变化。这在包含大量多层场景的 HM3D 和 MP3D 数据集中成为主要失败原因之一。


消融实验 (Ablation Studies)
研究重点评估了其核心创新——基于置信度加权的价值地图更新机制的有效性。实验对比了三种策略:直接覆盖(Replacement)、未加权平均(Unweighted avg.)和加权平均(Weighted avg.)。
结果显示,加权平均策略在三个数据集上均取得最佳性能,一致地提升了 SPL 和 SR。这证明其设计的置信度通道(强调视野中心观测、惩罚边缘观测)能更有效地融合多帧信息,生成更稳定、准确的价值地图,是提升导航效率的关键。

总结
VLFM 通过系统的实验证明,其提出的视觉-语言价值地图与基于置信度的融合机制共同作用,能够实现高效、鲁棒的零样本语义导航,在仿真环境中达到业内领先水平,并具备良好的现实世界部署能力。其局限性(如对平面导航的假设)为未来研究指明了方向。

ApexNav
第二篇是周博宇老师团队在RA-L上的VLN工作,创新地提出了“自适应探索策略”,让机器人能动态判断何时该“相信常识直奔主题”,何时又该“抛弃幻想全面探索”。
更聪明的是,它引入了“目标中心语义融合”机制,像人类一样“多看几眼再下结论”,通过多角度观测融合来有效过滤误检,极大提升了导航的可靠性。
周博宇老师相关内容探讨:周博宇 | 具身智能:一场需要谦逊与耐心的科学远征、独家|ICRA冠军导师、最佳论文获得者眼中“被低估但潜力巨大”的具身智能路径
同时,周博宇将作为组委会成员 & 控制规划与多机器人分论坛主席,出席第三届自主机器人技术研讨会(ARTS2025)!在这里,我们将进行更多「真问题」探讨!
早鸟优惠【最后5天】👇


期待与大家线下见~
我们继续将视线聚焦于这篇VLN工作。
背景
目标导航(ObjectNav)需要一个自主智能体在未知环境中导航到由其类别指定的目标对象。近年来随着LLM、VLM的发展,zeroshot ObjectNav (ZSON)逐渐成为主流。
目前的ZSON方法在效率和鲁棒性方面仍然面临挑战:
大多数方法严重依赖语义推理来探索和搜索:
但语义指导并不总是可用或可靠的。例如,在任务开始时,可能会面对一堵空白的墙,从而限制语义线索并阻碍有效的基于语义的导航。

一些方法依赖于单帧检测来识别目标:
而其他方法采用最大置信度融合来构建用于目标识别的语义图。然而,仅仅依靠单帧结果往往缺乏鲁棒性。最大置信度融合也与错误检测作斗争。在有遮挡或相似物体的混乱场景中,这些问题更加严重。
ApexNav通过从人类搜索对象的行为中汲取灵感来解决这些局限性。
当语义线索弱时,人类倾向于快速探索他们的周围环境;
当线索强时,人类倾向于将搜索集中在可能的目标区域;
当遇到潜在的类似目标的物体时,人类不会在不确定的情况下立即做出决定;
相反,他们收集额外的观察结果来积累证据并完善他们的判断。
整体框架
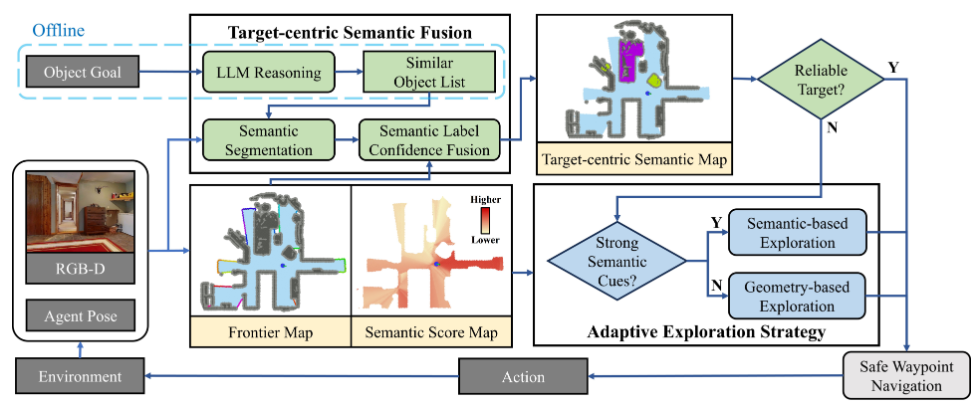
任务为ObjectNav任务:导航到未知环境中的指定对象。
机器人使用一个以自我为中心的RGB-D相机和一个里程计传感器来提供其相对于起点的位移和方向。要求机器人有效地导航到目标物体,最小化路径长度并在规定的成功距离内到达目标物体。
构建边界图和语义得分图
(1)边界图
Step1:在2D概率网格上构建边界地图,通过光线投射将每个单元标记为空闲、占用或未知;
Step2:深度图像被转换为点云,并使用半径离群点去除进行去噪;
Step3:边界被定义为与至少一个未知单元相邻的空闲单元;
Step4:逐步更新边界,并使用主成分分析对它们进行聚类,用每个聚类的中心来近似每个聚类,以简化计算。
(2)语义得分图
Step1:构建2D语义得分图来显示环境和目标对象之间的相关性,其中得分越高意味着相关性越强;
Step2:每个RGB图像和一个文本提示被输入到预先训练的VLM BLIP-2中,它使用图像-文本匹配输出余弦相似性得分;
Step3:基于房间关联物体(如卧室的床)构建提示,提升BLIP-2的远距离早期识别能力。房间名由LLM推断,无关物体(如植物)仅提物体本身;
Step4:语义置信度按视角加权投影至网格,光轴附近权重高,随角偏移衰减;
Step5:多帧语义融合采用置信度加权平均更新网格得分,置信度更新强调高确信预测。
自适应探索策略
(1)模式切换标准
基于语义得分图给每个边界分配一个得分,并计算均值和标准差;高均值代表语义相关度高,高标准差代表相关性不均匀,不够可靠。
如果满足均值和标准差的阈值,则切换到基于语义的探索,优先考虑高分前沿以有效定位目标;否则,默认为基于几何的探索,以扩大覆盖范围并收集更多的环境信息。
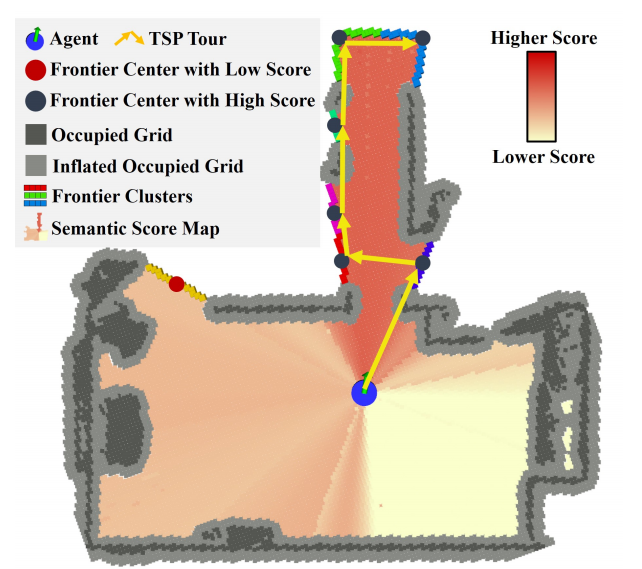
(2)基于语义探索
总是选择得分最高的边界会导致振荡和低效的回溯,尤其是当得分相似时。
为了解决这个问题,本文选择了一个高得分前沿的子集,并解决了一个旅行推销员问题(TSP),以规划一个最佳的访问序列。
这种方法平衡了语义相关性和全局路径效率,减少了冗余并增强了探索一致性。
(3)基于几何探索
当前沿语义得分高度一致时,系统切换到基于几何的探索,以快速获取新信息并扩大覆盖范围;最近边界策略通常优于基于TSP的策略。虽然这个结果是出乎意料的,因为TSP通常在全覆盖任务中更有效。
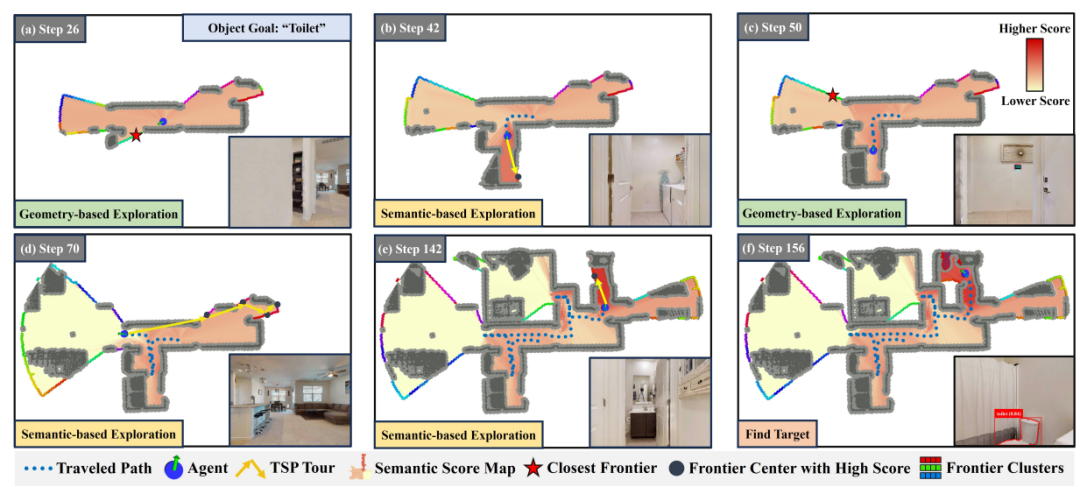
但进一步的分析表明,ObjectNav专注于定位目标,而不是穷举全覆盖。在这种情况下,贪婪策略更符合任务目标,引导我们采用它进行基于几何的探索。
以目标为中心的语义融合
(1)使用LLM的对象推理
利用具有思维链提示的LLM的推理能力来识别容易被误分类为目标的对象。考虑到检测器性能会受到对象大小的影响——小对象通常产生低置信度。只有当融合的置信度超过阈值时,对象才被视为可靠的目标。
然后导航到该对象这个过程产生一个综合对象列表,包括目标和类似的对象,指导后续的决策。
(2)目标检测与分割
所有待检测物体的RGB图像和文本描述由检测器处理。Mobile-SAM 使用检测到的对象实例的边界框对其进行分割,并且从深度图中提取它们对应的点云。DBSCAN用于消除噪声。

语义标签置信度融合
(1)融合单元与结构:
为降低计算开销并与目标级任务对齐,该方法以物体簇为基本融合单元,而非像素或网格。每个物体簇可存储多个候选标签的信息(如点云、置信度、累积观测点数),从而保留多义性。
(2)增量式融合:
对于当前帧的检测结果,将其与地图中已有的相交物体簇进行融合。若不存在,则创建新簇。融合时,以检测体积(即点云点数)作为权重,对置信度进行加权平均。这使得观测面积更大的、更可靠的检测结果在融合中占据更高权重。
(3)处理缺失检测(置信度惩罚):
为解决误检问题,该方法引入关键创新:对当前视野内应出现却未检测到的物体簇标签进行置信度惩罚。具体而言,将这些标签的本次检测置信度设为零并进行融合,从而主动降低其总体置信度,有效抑制偶发的假阳性检测。
(4)最佳标签选择:
融合后,每个物体簇会包含多个标签的融合结果。最终选择 置信度 × 观测点数 最高的标签作为该物体的最佳匹配标签,从而同时权衡了置信度的可靠性和观测的充分性。
安全路径导航与执行
在底层控制中,为确保智能体移动的安全性与效率,该方法并未简单跟踪最短路径,而是设计了一个代价函数来评估和选择动作:
(1)效率代价:鼓励智能体朝向局部目标点移动,并惩罚远离该点的动作。
(2)安全代价:通过构建局部ESDF地图,采样评估动作路径上各点与最近障碍物的距离,对过于接近障碍物的不安全动作施加高额惩罚。

最终,选择总代价最低的动作作为下一步执行指令。在无需离散动作的真实世界应用中,该方法采用轨迹优化算法(MINCO)来生成安全且连续的时空轨迹。
实验
性能对比
ApexNav在零样本对象导航任务中全面超越了现有方法。在HM3Dv1和HM3Dv2数据集上,其成功率和路径效率指标均达到最优,显示出优异的泛化能力。在结构更复杂的MP3D数据集上,其路径效率也为最高,证明了方法在复杂环境中的实用性。

失败分析
分析表明,任务失败主要源于三类原因:

(1)错误检测:视觉模型的误检和误融合是导致智能体在错误位置停止的主要原因;
(2)环境复杂性:大规模场景易导致步数耗尽,而多层场景则因当前系统缺乏跨楼层探索能力而失败;
(3)目标特性:小尺寸或外观模糊的目标较易漏检。
消融实验
(1)探索策略:实验证明,自适应切换策略(根据语义分布动态选择语义或几何探索模式)是关键,其性能显著优于任何单一的固定探索策略。
(2)语义融合:目标中心融合机制是性能提升的另一核心。消融实验表明,移除相似物体检测、多帧融合或观测惩罚机制均会导致性能显著下降,验证了该模块在提升鲁棒性、减少误检方面的不可或缺性。
综上,实验结果表明,ApexNav通过其自适应探索和目标语义融合机制,在导航效率和可靠性方面实现了显著提升,为零样本物体导航建立了新的强基线。

总结
ApexNav与VLFM这两项工作共同将零样本目标导航推向了新的高度。它们并非简单的迭代,而是从决策范式与感知融合两个核心维度进行的深度革新:
ApexNav赋予了机器人动态权衡“探索”与“利用”的智能决策大脑;
而VLFM则为其装上了能够从像素中直接提取语义信号的敏锐眼睛。
它们的成功印证了一个重要趋势:真正强大的具身智能,并非依赖于海量的任务特定训练,而是源于对通用基础模型(LLM、VLM)所蕴含的世界常识进行高效、精巧的空间化运用。
无论是Spot机器狗在真实办公楼中的流畅探索,还是在三大仿真数据集上全面超越有监督模型的性能表现,都强有力地宣告了零样本导航时代的到来。
展望未来,尽管在跨楼层导航、小物体检测等长尾问题上仍存挑战,但ApexNav与VLFM已为我们清晰地勾勒出了通往通用导航的路径——
一个融合了语义理解、空间推理与安全运动、能在未知世界中真正为我们所用的人工智能伙伴。
编辑|无意
审编|具身君
Ref
1. VLFM: Vision-Language Frontier Maps for Zero-Shot Semantic Navigation
2. ApexNav: An Adaptive Exploration Strategy for Zero-Shot Object Navigation with Target-centric Semantic Fusion
工作投稿|商务合作|转载
:SL13126828869(微信号)
>>自主机器人技术研讨会早鸟报名【倒计时 5 天】<<

为促进自主机器人领域一线青年学者和工程师的交流,推动学术界与企业界的深度交融与产学研合作,中国自动化学会主办了自主机器人技术研讨会(Autonomous Robotic Technology Seminar,简称ARTS)。
基于前两届大会的成功经验和广泛影响,第三届ARTS将继续深化技术交流与创新,定于2025年10月18日-19日在杭州举办。我们诚挚邀请您参加,并欢迎您对大会组织提供宝贵意见和建议!


【具身宝典】具身智能主流技术方案是什么?搞模仿学习,还是强化学习?|看完还不懂具身智能中的「语义地图」,我吃了!|你真的了解无监督强化学习吗?3 篇标志性文章解读具身智能的“第一性原理”|解析|具身智能:大模型如何让机器人实现“从冰箱里拿一瓶可乐”?|盘点 | 5年VLA进化之路,45篇代表性工作!它凭什么成为具身智能「新范式」?动态避障技术解析!聊一聊具身智能体如何在复杂环境中实现避障
【技术深度】具身智能30年权力转移:谁杀死了PID?大模型正在吃掉传统控制论的午餐……|全面盘点:机器人在未知环境探索的3大技术路线,优缺点对比、应用案例!|照搬=最佳实践?分享真正的 VLA 微调高手,“常用”的3大具身智能VLA模型!机器人开源=复现地狱?这2大核武器级方案解决机器人通用性难题,破解“形态诅咒”!|视觉-语言-导航(VLN)技术梳理:算法框架、学习范式、四大实践|盘点:17个具身智能领域核心【数据集】,涵盖从单一到复合的 7 大常见任务类别||90%机器人项目栽在本地化?【盘点】3种经典部署路径,破解长距自主任务瓶颈!|VLA模型的「核心引擎」:盘点5类核心动作Token,如何驱动机器人精准操作? | 深度综述|200+ paper带你看懂:VLM如何将VLA推上机器人技术操作之巅!
【先锋观点】周博宇 | 具身智能:一场需要谦逊与耐心的科学远征|许华哲:具身智能需要从ImageNet做起吗?|独家|ICRA冠军导师、最佳论文获得者眼中“被低估但潜力巨大”的具身智能路径|独家解读 | 从OpenAI姚顺雨观点切入:强化学习终于泛化,具身智能将不只是“感知动作”
【非开源代码复现】非开源代码复现 | 首个能抓取不同轻薄纸类的触觉灵巧手-臂系统PP-Tac(RSS 2025)|独家复现实录|全球首个「窗口级」VLN系统:实现空中无人机最后一公里配送|不碰真机也不仿真?(伪代码)伯克利最新:仅用一部手机,生成大规模高质量机器人训练数据!
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文