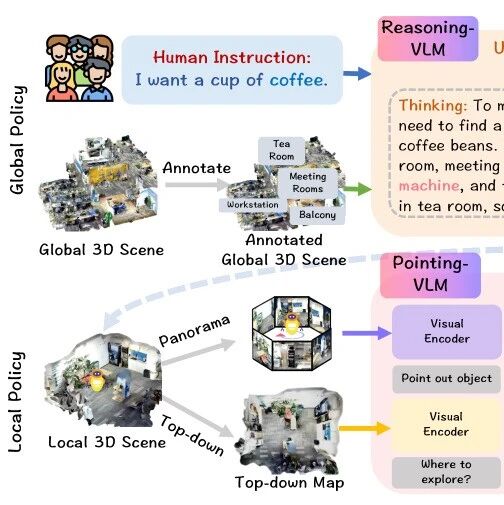
智猩猩Robot整理
导航是机器人领域的核心任务,导航系统通常以语言指令和视觉观测作为输入,并据此执行规划轨迹。近年来该领域已取得显著进展,并在四足机器人和人形机器人等不同具身本体上得到验证。
但现有的导航模型的动作空间往往仍被简化为离散选项并以端到端方式预测。这导致它们只能从有限空间中选择短期动作步骤,同时存在推理速度慢和导航行为碎片化的问题。
为此,上海人工智能实验室开源首个端到端双系统导航大模型InternVLA·N1。该模型基于『书生』具身全栈引擎Intern-Robotics构建,实现了高层远距离目标空间推理规划和底层敏捷执行的双系统解耦。

论文标题:《InternVLA·N1: An Open Dual-System Vision-Language Navigation Foundation Model with Learned Latent Plans》
技术报告:https://internrobotics.github.io/internvla-n1.github.io/static/pdfs/InternVLA_N1.pdf
项目主页:https://internrobotics.github.io/internvla-n1.github.io/
开源代码:
https://github.com/InternRobotics/InternNav
1
核心贡献
论文主要贡献有三点:
1. 端到端双系统导航大模型架构:以最远可见像素目标点作为导航大模型双系统初始化训练的中间媒介,在联调阶段免除人为先验,引入可学习隐式规划表征,异步联调和推理实现双系统联合优化和紧密协同。
2. Intern-Robotics 开源全栈引擎底层支持:基于桃源仿真引擎和多源场景资产,以基于传统优化策略的轨迹合成和自动化拆分标注管线为核心构建起数据引擎,形成目前场景最丰富的大规模导航数据集InternData N1;构建训测工具链 InternNav 全流程支撑双系统不同阶段迭代需求,涵盖传统评测 Habitat VLN-CE R2R/RxR 和基于 Isaac Sim 物理仿真评测 VLN-PE 等。
3. 纯仿真训练,60Hz 异步推理真机零样本泛化:InternVLA·N1 在大模型空间推理规划(R2R-CE/RxR-CE)、泛化执行避障(ClutteredEnv/InternScenes-100)、端到端全系统执行(VLN-PE-Flash/VLN-PE)等6个主流基准上领先;通过端到端从数据合成到真机部署的协同优化,仅使用合成数据训练,真实场景部署即可实现 60Hz “跨楼宇长距离”听令行走和密集障碍物间敏捷避障的丝滑融合。

2
端到端双系统架构
视觉语言导航是具身智能体基础能力之一。受限于基准的设置和有限的模型方法尝试,当前大部分工作采用大模型直接预测离散的动作空间(向前,左转15°,右转15°,停止),忽略了大模型的长程推理规划能力,同时限制了导航模型的移动能力和执行效率。
基于这种设置,双系统大模型的训练共分两个阶段:(1)预训练阶段:多模态大模型(系统2)给定转向/移动到目标像素的规划拆解真值进行监督微调,导航扩散策略(系统1)给定目标像素和轨迹真值学习避障执行到目标点的移动能力;(2)联合微调阶段:固定多模态大模型,在系统2 输入侧插入 learnable queries,让系统 2 除了可以输出显式的语言和目标外,额外生成 latent plans 作为 goal condition 传至系统 1,以端到端的语言指令输入-轨迹输出作为监督微调连接层和系统1,实现更优的双系统协作。为了实现异步执行的最优效果,系统1可以给定同一个时刻的 latent plans 和不同时刻的观测学习不同时刻的执行策略,由此实现训练和推理时的一致性。值得一提的是,这种范式还可以进一步延伸通过增加一个世界模型作为预测式解码器进行视频生成预训练,利用海量的、无需人为先验引入标注的真实视频数据可扩展地训练得到更好的 latent plans(实验发现可提升双系统联调效率50%),使得模型可以更好更快地适应动态环境,并实现真实环境的泛化。

图2:InternVLA·N1 的端到端双系统架构。
3
构建大规模多元场景导航数据集
导航大模型的训练离不开高质量多元化的场景数据和可扩展的数据飞轮。因此,团队广泛收集了开源的场景数据集构造了目前场景最多元的大规模导航数据集InternData-N1,涵盖了 HM3D、3D-Front、Gibson、HSSD、Matterport3D、Replica 等主流场景数据,以自动化可扩展的数据管线构建了包含超过 5000 万帧第一视角图像、4839公里导航里程的大规模数据集。另外,面向不同阶段和系统的训练需求,团队进一步推出了 VLN-CE 和 VLN-N1 两个数据子集。
其中VLN-CE 子集面向HM3D 相应的 benchmark,基于自建轨迹合成管线进行了相应的轨迹数据优化,并面向目标像素的标注进行了片段切分和自动化标注,主要用于系统2的预训练和双系统联调;另一方面VLN-N1 子集基于多元的场景数据,主打场景的多元性,轨迹合成也充分加入视角、光照的随机化增强,通过大模型的自动化指令标注、改写和筛选管线构造了一批更多元化的轨迹数据,主要用于系统1的预训练和双系统联调泛化性的加强。
VLN-N1 的数据合成共分成三个阶段:(1)轨迹数据渲染合成:基于场景资产、全局地图和本体信息,通过传统运控方法设置规则合成相应的轨迹数据;(2)语料标注和改写:通过大模型对轨迹视频进行语言描述,形成初版指令,再根据需求微调和改写语言指令;(3)数据筛选:通过轨迹中涉及有意义语义信息/物体数量进行打分,分三档滤除分数为0的数据,最终筛选了23%的低质量数据。经验证,筛选掉数据并未影响模型性能的同时,显著降低了训练成本;同时,多元场景使得模型性能以可扩展的方式持续提升。

图3:InternData·N1中的VLN-N1子集的数据构造流程。

图4:InternData·N1中的VLN-N1子集的数据分布统计。
4
实验
具备基础的数据并训练出导航大模型后,一套系统的评测基准和真机部署方案才能最终实现模型的高效迭代和落地应用。由此,面向双系统的评测,一方面团队在传统R2R 和 RxR 基准上实现了双系统方案和端到端离散预测+最短路径执行的直接比较,方便有一个相对直观的性能比较结果;另一方面,面向连续轨迹控制以及和物理世界更加一致的评测需求,构造了一套基于Isaac Sim 物理仿真的评测机制。
仿真测试
基于Isaac Sim 物理仿真的评测机制,具体包括面向系统1各种目标的视觉导航评测基准(杂乱环境 ClutteredEnv 和桃源场景 InternScenes-100),面向整体系统考虑本体运动的基准 VLN-PE,提供了更多元场景和更全面的系统评测方法,进一步加速模型的有效迭代。

图5:InternVLA·N1 双系统在传统 VLN-CE 和物理仿真评测 VLN-PE 中的推理示例。对应语言指令分别为“离开浴室进入卧室,从卧室出去到走廊,在楼梯上面等待”、“经过厨房从右边进入房间,路过桌子和椅子停在沙发前”。

图6:系统1在物理仿真评测(InternScenes-100)中的推理示例,从左到右依次为推理第一视角、目标达到的第一视角图像、实时推理轨迹。
真机实验
在真机部署方面,以宇树机器狗Go2 为例,首先在视觉传感器方面采用 Intel Realsense D455 以实现移动过程中较优的图像清晰度,进一步对齐高度(0.6米)和朝向(斜向下15°)以保证和仿真评测效果的相对一致性;在机器人本体控制和模型推理方面,InternVLA·N1 输出的轨迹通过定位信息转换到世界坐标系并通过 MPC 控制器进行跟踪,模型方面通过系统2在多轮对话时的 KV-cache 机制优化和系统1的 TensorRT 部署,分别可在单卡 RTX 4090 上实现 2Hz 和 30Hz 的实际推理速度,进而通过异步机制可实现综合推理速度近60Hz,再通过200Hz 的控制器跟踪轨迹,由此也可看出双系统推理机制在敏捷反应上相比纯系统2大模型的显著优越性。这一推理效率可通过模型结构等方式进一步优化,配合端侧芯片以实现更优的部署应用体验。


图7:真机测试比较示例:InternVLA·N1 能以更丝滑的推理过程和更快的执行速度,在长程导航任务中完成敏捷避开障碍物的同时更好地完成指令跟随。
END
智猩猩矩阵号各专所长,点击名片关注