如您有工作需要分享,欢迎联系:aigc_to_future
作者:Bonan Li等
解读:AI生成未来

论文链接:https://arxiv.org/pdf/2506.15563

亮点直击
首次对现有反向引导方法进行了理论分析。基于该理论洞见,提出了面向布局生成图像(Layout-to-Image)的先进方法WinWinLay,在控制精度与真实感质量上实现显著突破。 提出新型非局部注意力能量函数,在保持物体自然结构的同时,使模型更严格遵循空间约束。 开发了基于朗之万动力学的自适应更新方案,在保持效率的前提下,彻底消除布局指令与真实视觉效果之间的权衡问题。 WinWinLay在控制性与生成质量上的卓越表现,从而推动L2I生成技术的实际应用落地。
总结速览
解决的问题
布局控制不精确:现有基于预训练文本到图像(T2I)扩散模型的布局到图像(L2I)方法存在物体定位偏差,无法均匀覆盖指定区域,导致生成结果与布局指令不一致。 图像质量下降:传统反向传播更新规则会偏离预训练模型的分布,导致生成图像出现不真实伪影(out-of-distribution artifacts),在控制强度与视觉保真度之间存在权衡。
提出的方案
非局部注意力能量函数(Non-local Attention Energy Function): 通过理论分析指出传统注意力能量函数存在空间分布偏差,提出非局部注意力先验重新分配注意力分数,使物体更均匀对齐布局。 引入衰减调度(decaying schedule),逐步降低先验强度,避免不规则形状物体(如椰子树)被强制约束为刚性框状。 基于朗之万动力学的自适应更新(Adaptive Update): 设计一种结合布局约束和预训练模型分布的双向更新策略,通过朗之万动力学平衡两者方向。 采用自适应权重策略动态调整不同采样步骤中的更新方向,避免复杂超参数搜索。
应用的技术
非局部注意力机制:重新分配跨注意力分数,消除空间偏差。 朗之万动力学(Langevin dynamics):在梯度更新中引入随机性,确保生成结果既符合布局约束又保持预训练模型的分布特性。 衰减调度:动态调整先验强度,适应不同去噪步骤的需求。
达到的效果
精准布局控制:物体能够均匀分布在指定区域内,显著提升空间对齐精度。 高视觉保真度:生成的图像保持真实感,避免伪影和失真,优于当前训练免费(training-free)的SOTA方法。 效率与泛化性:无需额外训练或数据,直接利用预训练T2I模型实现高质量L2I生成。
方法
WinWinLay,一种免训练的布局到图像生成框架。首先详细阐述非局部注意力能量函数,用于增强布局约束;随后探讨自适应更新,以消除控制与质量之间的权衡。
非局部注意力能量函数
注意力能量函数是广泛用于引导注意力重分配的损失项,但常导致物体仅占据边界框的局部区域,阻碍精确控制。为此,引入非局部注意力先验,促使注意力在指定位置平滑分布。
注意力能量函数回顾
根据注意力能量函数,可将公式(2)直观改写为公式(4)的形式:
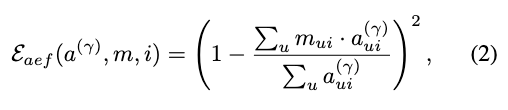
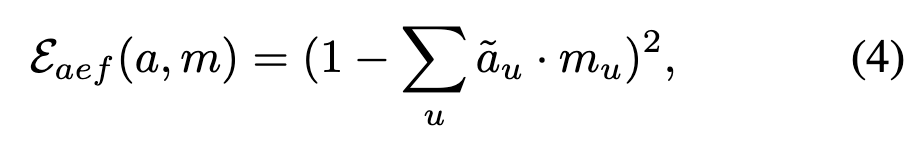
其中, 表示注意力图中第个 patch 的注意力值的归一化结果。为简化表述,此处省略了主体和交叉注意力层的标记。
给定,因此有,进而得到以下等式:
最小化等价于最大化。当取得最大值时,的支撑集必然包含于的支撑集内。基于这一观察,首先注意到注意力能量函数的最优解并不唯一。实际上,只要的支撑集完全包含于内,即可达到最大值。
然而,这种非唯一性可能导致的支撑集集中在的局部区域,从而损害对空间布局的有效控制。同时注意到,使得掩膜区域内的所有patch在优化过程中获得相同的梯度幅值。这导致初始值较大的patch在优化过程中占据显著优势,从而加剧局部化效应(见下图2)。为验证这一观点,首先考虑以下简单但普适的优化目标:
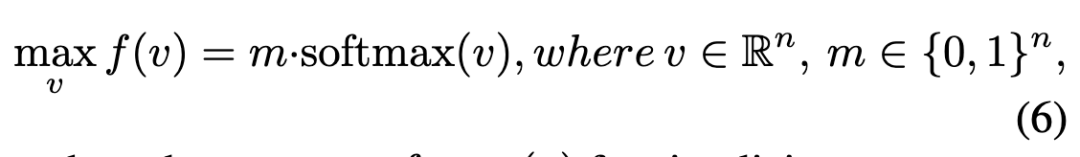

定理4.1
假设在优化过程的某一步中,存在且。经过步长的单次梯度更新后,更新后的值、满足且。
证明
首先,关于的雅可比矩阵可计算如下:
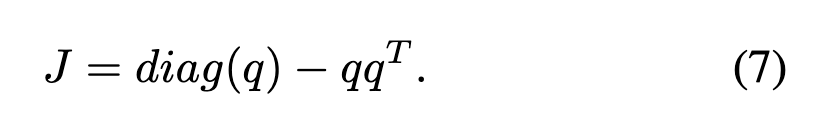
根据链式法则,的梯度可表示为:
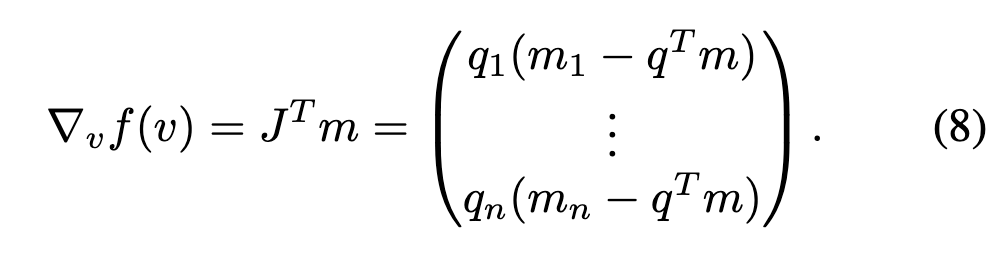
然后, 和 的更新公式为:
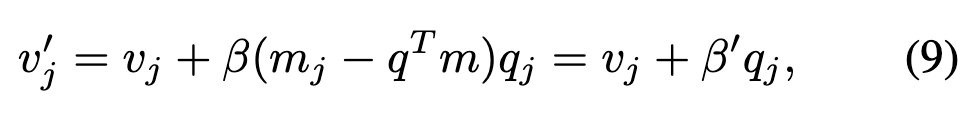
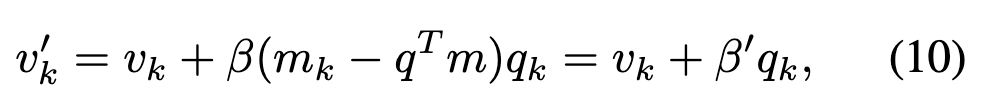
将上述公式联立可得:

通过上述问题分析可得出结论:在优化过程中,掩膜区域内初始值较大的patch会放大其相对优势,从而抑制其他区域的增长。这意味着能量函数重分配的注意力图存在隐式偏差,倾向于初始值较大的区域,因此难以均匀覆盖整个边界框。
非局部注意力先验
为此,我们引入一种简单有效的非局部注意力先验来促进全局注意力响应。与直观设想的均匀约束不同,该先验促使物体靠近边界框中心放置,同时鼓励最大程度覆盖整个区域。具体而言,给定边界框(宽度,高度)及其中心点,掩膜区域内点到中心的归一化距离计算为:
相应地,构建先验分布,其中用于控制分布的方差。该设计确保离中心越远的点被赋予越小的概率值。随后,通过最大化注意力分布与先验在内的KL散度来缓解局部偏差:
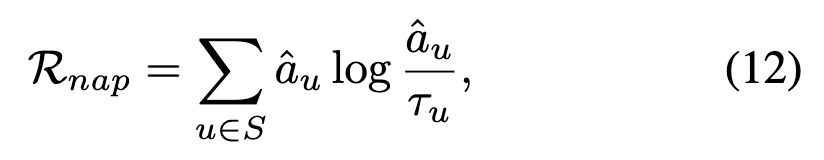
其中,表示注意力值。
总损失函数非局部注意力能量函数定义为所有主体和层上与的总和:
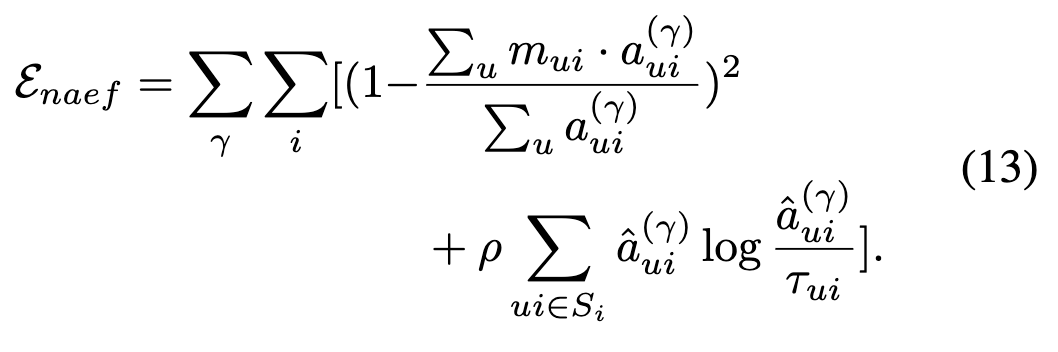
为适应现实场景中物体的不规则形状,本文引入了一个超参数ρ,该参数随去噪时间步长线性递减,使物体能够适应自然结构。与现有研究类似,仅对中间层及首个上采样层中与对应令牌相关的交叉注意力进行重新分配。
自适应更新
尽管反向传播更新方法简单,但难以平衡布局约束与图像质量。因此,本文提出基于朗之万动力学和自适应分布构建的自适应更新方法,持续提升输出质量。
反向传播更新回顾
给定时间步的隐特征,预训练扩散模型的条件概率生成初始估计。随后,梯度更新步骤通过最小化非局部注意力能量函数(替换以保持描述一致)优化隐变量:
其中。然而,这种更新方式未充分考虑隐变量分布的约束,导致生成控制与输出质量之间的权衡:
梯度更新不足时,优化不充分,布局控制效果差; 梯度更新过强时,可能显著偏离初始估计,降低似然,进而影响后续去噪步骤的图像质量(下图3可视化结果验证该结论)。

朗之万动力学更新
为消除这一权衡,本文提出在更新过程中同时考虑注意力重分配和。对于注意力重分配函数,其对应的吉布斯分布可构造为,其中是控制分布形状的超参数。给定时间步,本文的最终目标是从中采样。根据贝叶斯定理,得到:

则的得分函数可推导为:
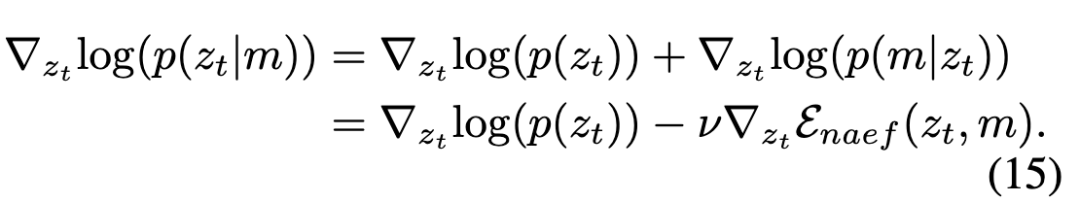
其中,表示无条件的得分函数,由预训练扩散模型近似得到。根据(Song & Ermon, 2019)的研究,可以使用朗之万动力学从任何已知得分函数的分布中进行采样。具体来说,给定步长和初始值,朗之万动力学的迭代更新过程如下:

其中 且 。当 且 时, 的分布将收敛于 。需要注意的是,对于步长 和有限的 ,可以通过 Metropolis-Hastings 方法对采样过程进行校正,将其转化为严格的 MCMC 采样过程。然而,在实际应用中,为了方便通常会省略这一校正步骤。此处与 (Song et al., 2021b) 类似,确定步长 ,其中 是信噪比。
自适应分布构建。尽管 Langevin 动力学有效缓解了权衡问题,但引入分布的超参数 会降低生成效率。根据公式 (15), 调节了 在得分函数 中的权重。
直观上,较大的 会导致更陡峭的分布,此时优化过程更侧重于最小化非局部注意力能量函数,从而加快收敛速度(更小的 ),但需要更大的步长 来加速 的优化过程,这会增加 Langevin 动力学的误差,进而降低图像质量。反之,较小的 会产生更平坦的分布,优先保持图像质量,这会减慢优化过程(更大的 ),需要更小的 ,但导致更多迭代次数,降低采样效率。因此,选择合适的 对于平衡图像质量和生成效率至关重要。
本文提出将公式 (16) 视为多任务优化问题来探索最优的 ,其中一个任务是最小化注意力能量,另一个任务是最大化分布概率。受 Nash-MTL启发,将这两个任务的梯度组合建模为讨价还价博弈,求解纳什讨价还价解。设 表示 个任务的梯度,最优梯度组合系数 满足 ,其中 是以梯度 为列的矩阵。Nash-MTL 使用优化来近似求解 ,发现当 时,该方程有一个简单的解析解:
推论 4.2。给定 和 ,如果 ,则有 。
证明。根据 ,得到:
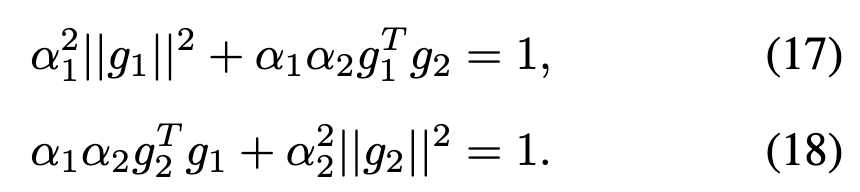
通过从方程 (17) 减去方程 (18):

可以推导出结论为 。
基于上述证明,提出自适应更新规则,将 形式化为每次迭代的自适应参数。
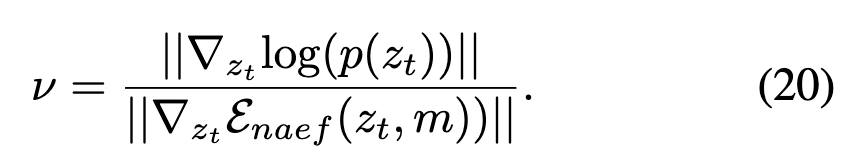
这一设计使我们能够以可忽略的成本有效缓解权衡问题,使其更适用于实际应用。
实验
本节首先介绍实验设置,随后进行定性和定量实验,将本文的方法与之前最先进的布局到图像生成(Layout-to-Image)方法进行比较。此外,我们还进行了消融实验,以验证所提方法的有效性。
实验设置
评估基准。与先前工作类似,本文在 COCO2014和 Flickr30K数据集上对 WinWinLay 进行定量评估。在性能评估方面,采用 YOLOv7进行目标检测,并使用 AP等指标衡量方法在准确定位和生成物体方面的有效性。此外,利用 CLIP-s定量评估图像-文本兼容性,从而衡量合成图像的语义准确性。同时还采用 FID、PickScore和 ImageReward等优势指标评估图像质量。在此,将文本模板设置为“A photo of [prompt]”以获得更真实的结果。
实现细节
本文采用基于 LAION-5B 预训练的 Stable Diffusion 1.5 作为基础文本到图像生成模型。在生成过程中,使用 DDIM 采样器进行 50 步采样,并将引导尺度设置为 7.5。由于布局约束通常在去噪的早期阶段生效,仅在初始 10 步内施加布局约束。非局部注意力先验的超参数 的最大值和最小值分别设置为 5 和 0。对于自适应更新,Langevin 动力学的步数 设为 4,信噪比 设为 0.06。实验表明,这些参数在大多数情况下表现良好,证明了 WinWinLay 的泛化能力。本文也指出,通过定制化设置(例如更大的 或更多的 Langevin 动力学迭代)可能获得更好的结果。
与 SOTA 方法的比较
本文将 WinWinLay 与四种代表性的最先进方法进行比较:Layout-Control、AttRe、R&B和 CSG,以展示其优势。所有方法均基于官方代码实现。
定量比较。如下表 1 所示,首先在测试数据集上对生成图像进行定量评估。与 Layout-Control 和 AttRe 相比,CSG 在物体放置准确性上表现出显著提升。然而,实验中发现其对梯度强度高度敏感,更高的准确性往往导致图像质量严重下降,尤其是在生成大量物体时。相比之下,本文的方法在多个数据集和评估指标上均表现优异,展现了更稳健的改进。

通过用户研究评估人类对生成结果的偏好。研究分为两部分:可控性和质量。在第一项研究中,参与者需选择最符合给定布局的图像;第二项研究则要求识别外观最真实的图像。为确保清晰性和可重复性,我们在类 Mechanical Turk 平台“问卷星”上开展研究。150 名参与者评估了 50 对图像,每项研究收集 7500 份反馈。图像与布局提示并排显示,问题和图像位置均随机排列以避免偏差。如表 1 所示,27.7% 的生成结果在两个指标上均被评为最优,证明了 WinWinLay 的显著优势。
定性比较。为更直观地展示模型性能,在包含 3-5 个物体的手工数据集上进行实验。为公平比较,每种方法在相同随机种子下生成 10 张图像,并根据 AP50 选取最优结果展示。下图 4 中每组展示 2 张图像,结论如下:(i) 本文的方法能够将目标物体精准放置在给定区域内,同时完整填充边界框且不破坏物体自然结构,相比现有方法有显著提升。而其他方法常无法严格遵循布局(如第 1 行),或导致物体部分区域坍缩(如第 4 行);(ii) WinWinLay 成功消除了控制与质量之间的权衡,在附加布局约束下仍保持基础模型的生成能力。现有工作则过度关注布局贴合而牺牲物体真实性(如第 3 行)。此外,相同提示和空间约束下生成的多组结果证明了 WinWinLay 的鲁棒性,进一步推动了布局到图像生成在实际应用中的进展。

消融实验
所提策略的效果。为验证方法的有效性,在基线模型上逐步引入非局部注意力能量函数(Non-local Attention Energy Function)和自适应更新(Adaptive Update),并观察性能变化。如下图5所示,非局部注意力能量函数显著增强了对布局的控制能力,同时确保所有目标物体的准确呈现;而自适应更新不仅提升了空间定位精度,还改善了整体图像质量(例如"长颈鹿"的生成更真实)。表2的定量结果与视觉观察一致:非局部注意力能量函数使AP和AP50大幅提升,自适应更新则进一步优化了空间定位并提高图像质量。

非局部注意力先验的超参数。传统注意力能量函数常面临注意力坍缩到局部区域的问题。为此引入非局部注意力先验,约束注意力聚焦于边界框中心并逐步扩展至覆盖整个区域。其中作为超参数控制先验强度。如下图6所示,随着逐渐增大,图像中物体逐渐对齐边界框边缘,实现更精确的布局控制。但当过大时,可能导致物体在框内出现不自然排布(如方形画布上的"兔子")。实验发现时通常取得最优结果,故所有实验均采用该设定。

自适应更新的超参数。自适应参数对方法效果具有关键影响。前面分析了不同对效率和性能的作用,并提出自适应策略以降低调参复杂度。为验证其有效性,我们为设置不同量级系数,并通过网格搜索确定最优步长的信噪比和更新步数。如图7所示,较大的通常需要更大步长和更少迭代,但会显著降低精度和质量;而较小的对性能影响较小,但会大幅增加生成时间。

结论
本文提出WinWinLay——一种无需训练的布局到图像生成框架,在布局精度和视觉保真度上取得显著提升。针对现有方法的局限,WinWinLay包含两个创新组件:(1) 非局部注意力能量函数,确保注意力在指定布局内均匀分布的同时保持物体自然结构;(2) 自适应更新,利用Langevin动力学平衡布局控制与图像质量。标准基准测试表明,WinWinLay在可控性和真实感上均超越现有方法,为L2I任务提供了高效鲁棒的解决方案。
影响声明
本研究提出的免训练布局控制图像生成方法在增强可控性的同时保留了基础模型的生成能力,但与其他生成技术类似,可能被滥用制造虚假信息,这凸显未来需针对布局引导生成涉及的伦理风险开展研究。
参考文献
[1] Control and Realism: Best of Both Worlds in Layout-to-Image without Training
致谢
如果您觉得这篇文章对你有帮助或启发,请不吝点赞、在看、转发,让更多人受益。同时,欢迎给个星标⭐,以便第一时间收到我的最新推送。每一个互动都是对我最大的鼓励。让我们携手并进,共同探索未知,见证一个充满希望和伟大的未来!
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!