核心看点: 华为在光互连与网络优化上再次加码,旨在构筑超越英伟达的节点与集群级系统性优势。
单芯片性能层面,即将推出的 Ascend 950 将追平 Hopper,960 对标 Blackwell,而更长远的 970 则以挑战 Rubin+ 的性能为目标。
芯片层面:加速追赶
到 2026 年第一季度,华为将率先出货下一代 Ascend 950PR。这款芯片的计算裸片似乎采用了单片设计,而非将两块裸片拼接在一起的多芯片模块方案。

其目标明确:在不依赖双芯封装的前提下,实现媲美 H100 的强大算力。
950PR 专为预填充和推荐系统等场景设计,这些场景需要巨大的内存容量,但对速度的要求相对宽松。为此,华为推出了自研的类 HBM 内存技术 HiBL 1.0。
相比之下,英伟达针对预填充场景优化的 Rubin CPX 要到 2026 年末才能问世,且采用的是 GDDR 技术,与 HiBL 并非同类。
紧接着,在 2026 年第四季度,为解码与训练任务打造的 950DT 将会上市。它采用与 950PR 相同的计算裸片,但匹配了 HiZQ 1.0 高带宽内存。
HiZQ 的规格参数几乎与 HBM3e 一致,但其物理尺寸可能并非标准件。它通过采用华为自研的逻辑裸片作为基础,实现了更高的速度,并简化了计算裸片上的控制器设计。
Ascend 960 大概率是 950DT 的芯粒版本,这与 Blackwell 之于 Hopper 的升级路径相似。其计算核心与内存容量将直接翻倍,而内存带宽的增幅甚至会略超两倍。
Ascend 970 仍处在规划阶段,但华为对其寄予厚望,计划将核心指标再次翻倍,以维持对英伟达的强大竞争力。
系统层面:开启超越
在系统构建的视角上,华为已经用“超级节点”这个概念,取代了传统的“节点”。
因为华为的雄心不再是简单地集成 384 颗芯片,而是通过高速光互连和定制化的网络协议,将 8192 颗芯片融合成一个整体。
这种设计使整个系统如同一台超级计算机般协同工作,尽管其内部扩展性能或许无法完全达到 NVLink 的水平。
即便如此,在华为 UnifiedBus 2.0 技术的加持下,这种纵向扩展架构的可靠性与网络效率,将远超英伟达目前采用的“纵向扩展+横向扩展”混合模式。
华为宣称,其 8000 卡规模超级节点的有效算力利用率高达 95%。
考虑到华为在光通信与网络技术领域深厚的积累,这一目标并非遥不可及。通过掌控从硬件到协议的全栈技术,华为能够以定制化的方案实现极致的系统性能。
通过光互连,华为巧妙地避开了类似 Blackwell 或 Rubin 那样,依赖 CoWoS 封装技术进行复杂芯间互联的路线。
这意味着,当英伟达还在通过芯粒技术和更高密度的电路板设计,在单个机柜里堆叠更多算力时,华为已经转向了将更多机柜高效连接成一个巨型系统的全新赛道。
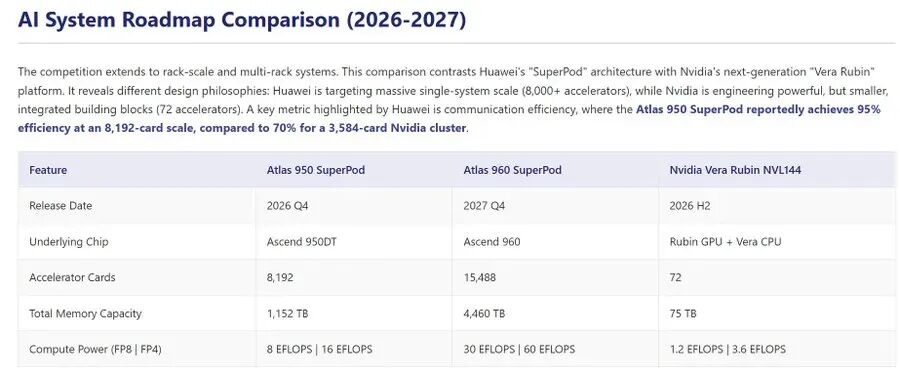
一个 Atlas 950 超级节点包含 128 个计算机柜和 32 个网络机柜,总计 160 个机柜,占地 1000 平方米。
而一个 Atlas 960 超级节点则由 176 个计算机柜和 44 个网络机柜组成,总规模达到 220 个机柜,占地面积 2200 平方米。
与英伟达同样计划在明年下半年推出的 NVL144 相比,Atlas 950 超级节点在规模上是其 56.8 倍,总算力是其 6.7 倍。
其内存容量高达 1152TB,是前者的 15 倍;互联带宽更是达到了 16.3PB/s,是其 62 倍之多。
即便是面对英伟达规划于 2027 年的 NVL576,Atlas 950 超级节点在所有关键指标上依然保持着全面的领先优势。

相较于华为上一代的 Atlas 900 超级节点,Atlas 950 的训练性能提升了 17 倍,达到 491 万 TPS。
通过新增对 FP4 数据格式的支持,其推理性能更是实现了高达 26.5 倍的飞跃,达到 1960 万 TPS。
Atlas 960 超级节点则将这一系统优势推向了新的高度。其总算力、内存容量和互联带宽,均在 Atlas 950 的基础上再次翻倍。
具体而言,FP8 总算力将达到 30 EFLOPS,FP4 总算力达到 60 EFLOPS;内存总容量高达 4,460 TB,互联总带宽达到 34 PB/s。
对比 Atlas 950,Atlas 960 在大模型训练和推理性能上将分别再提升 3 倍和 4 倍以上,达到 1590 万 TPS 和 8050 万 TPS 的惊人水平。
集群层面:构建全球最强算力
拥有如此强大的超级节点作为基石,构建巨型计算集群便成为水到渠成的事情。
Atlas 950 超级集群由 64 个 Atlas 950 超级节点互联而成,将超过 10,000 个机柜中的 52 万余颗 Ascend 950DT 芯片,整合成一个总算力高达 524 EFLOPS 的庞然大物。
它将与 Atlas 950 超级节点同步,于 2026 年第四季度正式推出。
在集群网络技术上,华为同时支持 UBoE 和 RoCE 两种协议。UBoE 允许客户利用现有的以太网交换机,而其性能相比传统 RoCE 具有更低延迟和更高可靠性的优势。
因此,UBoE 是华为官方更为推荐的组网方案。
这就是华为的 Atlas 950 超级集群。它的规模是当前世界最大集群 xAI Colossus 的 2.5 倍,算力是其 1.3 倍,是无可争议的全球最强算力集群。
无论是面对当前千亿参数的主流大模型,还是未来万亿乃至百万亿参数的下一代模型,这个集群都能提供稳定、高效的算力支持,成为人工智能创新的坚实底座。
与此对应,华为将在 2027 年第四季度推出 Atlas 960 超级集群,将集群规模正式带入百万卡时代。
届时,其 FP8 总算力将达到 2 ZFLOPS,FP4 总算力达到 4 ZFLOPS。借助 UBoE 网络的持续优化,其性能与可靠性将再创新高。
通过 Atlas 960 超级集群,华为将继续赋能客户,共同探索智能世界的全新疆域。
总结:华为的真实位置
抛开具体数字,回到问题的本质:华为与英伟达的差距到底有多大?
从单颗芯片的功耗、性能、面积和成本综合来看,950DT 的水平已经十分接近 Hopper 和 Blackwell。
在内存技术上,华为通过自研标准走在了前面,但其 DRAM 颗粒的工艺水平略有滞后。
在网络技术上,凭借多年的深厚积累和全栈垂直整合能力,华为已经大幅领先于英伟达。
最后,也是最关键的一点:新的昇腾芯片开始支持 SIMT,以改善对 CUDA 的兼容性。
综合所有因素,华为正成为英伟达在商业 AI 芯片领域最不容忽视的竞争对手。
其超过 8000 卡规模的系统级网络技术已经打磨了一年有余,一旦 iDUV 光刻技术问题得到解决,前沿大模型在昇腾芯片上进行训练将指日可待。
950 芯片对华为意义非凡,它是继 2019 年设计的 910 系列之后,第一款为大语言模型时代全新打造的 AI 芯片。
在未来几个季度里,市场将如何接纳这款经过重新架构和全面优化的产品,无疑是整个行业最值得关注的焦点。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!










