

从2D丝滑过渡至3D
机器人能在 2D 场景完成简单识别,却难应对 3D 堆叠、杂乱环境导航?
能规划出逻辑通顺的任务步骤,却因忽略机械臂可达范围、物体摆放空间等,在真实场景中 “寸步难行”?
这是当前多数模型,忽视真实机器人物理约束时,所面临的核心瓶颈!
这篇来自华为诺亚方舟实验室的工作OmniEVA,正瞄准这两大痛点 —— 以 Task-Adaptive 3D 接地机制动态调控 3D 融合,用实体感知推理框架融入物理约束。

为什么需要OmniEVA?
OmniEVA 的设计初衷,是针对具身智能中最常见的两大困境:
几何适配性缺口、具身约束缺口。
前者让模型在二维和三维任务之间徘徊,无法兼顾视觉语义和空间理解;后者则让推理结果脱离现实,机器人明明规划出了“合理”的方案,却因超出机械臂的工作空间或忽视物体遮挡而根本无法执行。
研究团队认为,想要让大模型真正落地到机器人身上,必须同时解决:何时需要三维与执行是否真的可行,这两大核心问题。
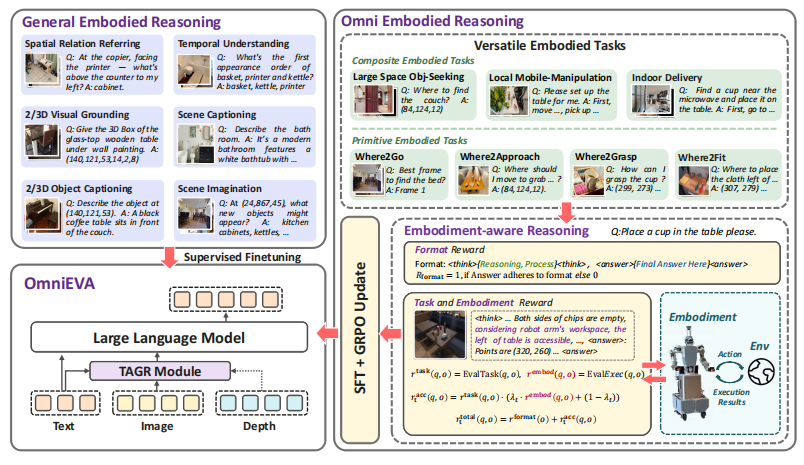
为此,论文提出了 OmniEVA 框架:

▲图1|OmniEVA 的模型结构。左图展示了 OmniEVA 的整体架构,其核心在于一种新颖的任务自适应门控路由器,能够动态引入三维位置嵌入。中图展示了门控路由器模块的具体实现方式。右图给出了该门控路由器在不同任务中激活状态的示例©️【深蓝具身智能】编译
一方面,它通过任务自适应三维 Grounding(TAGR)机制,在需要空间推理时动态注入三维位置先验,而在仅依赖视觉语义时则保持轻量,从而避免冗余计算与性能牺牲;
另一方面,它引入 具身感知推理,在规划过程中显式考虑任务目标与机器人本体的物理约束,确保推理出的计划既聪明又可执行。
接下来,本解读将依次展开:
(1)深入解析 OmniEVA 的方法设计,看看 TAGR 如何决定“要不要加三维”,以及具身感知推理如何将物理限制融入决策;
(2)总结实验结果与图表发现,观察它在问答、描述、指令执行等任务上的表现;

OmniEVA 的核心设计
任务自适应三维 Grounding(TAGR)
(1)模块作用与位置
TAGR 是整套框架里连接“任务需求”和“场景空间复杂度”的动态路由器,用来有选择地注入三维位置信息(3D positional encoding)。
它不把 3D 信息“一刀切”地加到所有任务上,而是按需打开或关闭。
(2)Patch 级三维位置编码(Patch-Level 3D PE)
编码过程如下:
先用相机参数把每一帧深度图投影到世界坐标系,得到每个像素对应的三维坐标;
与视觉编码器的图像 patch 划分对齐:把三维坐标也按同样的 patch 网格切分;
对每个patch 内的三维坐标求平均,得到“patch 级”的三维位置;
再将这些三维位置转换为与视觉 token 维度一致的向量,作为patch 级三维位置编码;
对多帧输入重复上述流程,最终得到与图像特征对齐、可与视觉流融合的 3D 位置特征。

(3)基于门控的动态 3D 注入(Gated Routing)
TAGR 的决策来自两类条件:
① 任务条件:把指令文本编码成一个任务向量,用来表达“这次任务到底需不需要三维推理”;
② 场景条件:把视觉特征在空间和时间上做全局聚合,得到一个“场景复杂度”的描述。
将任务向量与场景向量拼接后,送入一个轻量的感知-决策模块,输出一个二元门控信号:
① 门开:在视觉流里注入显式三维空间线索;
② 门关:只用二维视觉信息,不额外引入 3D。
这个门控可以理解成一种“专家混合(MoE)”的开关:
① “纯视觉专家”:仅用原始视觉 token;
② “融合专家”:用“视觉 token + 3D 位置编码”的混合表示。
最终输出的混合视觉表示与文本 token 一起送入大语言模型,生成响应。
(4)预训练
TAGR 先在“带深度感知”的数据上做预训练,目标是把输出对齐到标注答案。为了让门控稳定且可解释,训练时加入一个对门控分布的正则(以均衡先验为参照),防止门长期偏向某一状态。
预训练完成后,TAGR 参数被冻结,后续训练阶段不再改动。

专为具身任务设计的训练框架 (Embodiment-Aware Training Strategy)
为把“感知—推理—执行”统一到多样的具身任务里,论文提出了一个两阶段训练范式:
先打好“具身推理”底座,再通过“任务 & 具身约束”的强化微调,让模型学会生成可执行的计划。
▲图3|OmniEVA 的训练范式。该方法采用两阶段级联方式逐步提升具身智能:第一阶段侧重构建广泛的推理基础,第二阶段将其落实到物理现实中,最终实现跨越多种真实场景的稳健任务执行©️【深蓝具身智能】编译
(1)全监督的具身推理微调
阶段目标
先建立一个稳健的“推理骨干”,让模型具备跨模态、跨时空的理解与推理能力。
数据构成包含两部分内容:
① 通用具身推理数据
覆盖 2D 图像、视频序列、3D 环境等多模态输入;任务包含空间关系指代、时间推理、视觉定位、场景描述、想象式补全等;
目的:强化时空推理与多模态理解的综合能力。
② 自建具身任务数据
在现有基准(如 Where2Place、PACO-LVIS)之外,拓展到导航、操作、复合任务;
重点考查:可供性预测、抓取可行性、主动探索等;
每个任务都带链式思考(CoT)标注,包括任务分解与决策理由,作为“热启动”,帮助模型内化结构化规划策略,为下一阶段的“具身优化”打好基础。

▲图4|训练数据集的构成©️【深蓝具身智能】编译
(2)任务和部署感知强化微调
很多方法只追求“语义对不对”,忽略了“能不能执行”。TE-GRPO 的目标,是让模型输出既任务对齐、又物理可行的计划。
奖励构成(在原有“思考—回答”的格式奖励之外,新增两类关键反馈)
① 任务一致性奖励:评估回答是否满足任务语义要求,不涉及物理约束;例如指点任务里,指向是否落在目标区域内。
② 具身可行性奖励:评估计划在机器人约束下能否执行;例如是否满足运动学与可达性、是否被环境阻挡等(在模拟器内验证)。
二者分别对应两种优化目标:
前者更贴近离线评测的语义表现;后者直指真实执行的成功率。
(3)渐进式具身课程(Curriculum)
训练中采用从易到难的调度:早期更关注“语义正确”;随着训练推进,逐步提高“具身可行”的权重;
促使模型从“会说对”过渡到“会做对”,加速收敛并让策略更贴近现实约束。
(4)优化细节(概念化说明)
采用带截断更新与分布约束的策略优化范式(类似具有剪切项与 KL 正则的稳定更新),避免策略一步跳太大导致训练不稳;
每轮会对同一提示生成多份候选,按综合优势更新策略;
通过这套“任务+具身”的强化微调流水线,模型从“感知理解”逐步进化到“物理落地执行”,在多样真实场景中形成更可靠的规划与表现。

实验解析
评测设置与研究问题
本章围绕三件事评估方法有效性:
(1)动态三维 Grounding 是否增强多模态推理?机制如何起作用?
(2)具身感知推理是否在需要真实执行的任务上提高成功率?如何适配物理约束?
(3)能否通过组合原子能力,完成长时序任务?
具身推理基准(2D / 3D)
2D 输入的具身推理基准(四个):Where2Place、VSI-bench、PACO-LVIS、RoboRefit。
覆盖静态图像与动态视频,考查空间/时间理解与多模态推理。
原子能力到下游任务的桥接评测(四个):
① Where2Go:从多视角中选择下一最佳视角,在部分可观测环境里定位目标(贴近大空间目标搜寻)。

② Where2Fit:在桌面上预测可放置的二维点集合,需考虑位置、尺寸、碰撞等约束(对应 Mobile Placement-Easy)。

③ Where2Approach:识别不被椅子遮挡的可接近桌面空位,兼顾遮挡、底盘/机械臂约束(对应 Mobile Placement-Hard)。

④ Where2Grasp:按颜色、大小、位置、类别识别目标,强调以物体为中心的识别(对应 Mobile Pickup)。

3D 输入的具身推理基准(四个):SQA3D、ScanQA、Scan2Cap、ScanRefer。
覆盖3D问答、场景描述与3D视觉定位,检验模型在富几何结构场景中的推理能力。
模拟器中的端到端评测
在一个 3000m² 办公环境上构建三类逐级难度评测(8类核心场景、95个常见物品类别):
(1)Large-Space Object Seeking:
目标导航,评估在大空间中定位给定目标的能力。
(2)Local Mobile Manipulation:
30+ 场景,底盘位姿多样、物体类型/大小/位置多样。
Mobile Pickup:在多样桌面/场景中抓取目标。
Mobile Placement:分 Easy/Hard:
Easy:只需根据桌面占用情况确定放置点(同 Where2Fit 设置)。
Hard:需先确定底盘最优位姿,同时受桌面物品与周围椅子等环境约束(同 Where2Approach 设置)。
评估包含导航至目标位姿、规划安全放置轨迹与完成率。

(3)End-to-End Delivery:
在整层办公室中完成端到端物品递送;指标为整体成功率与平均完成时长。
动态三维 Grounding:跨多模态基准的验证
(1)对比基线
硬编码 3D:所有任务一律注入3D特征(常见于既有3D LLM路线)。
无 3D:完全视作传统2D MLLM。
结果:方法在 4 个任务中有 3 个领先,平均提升 1.22%;说明“按需注入三维”优于“始终/从不注入三维”,能在需要空间推理时发挥作用,而在不需要时避免额外负担,如图5所示。

▲图5|对于TAGR模块的消融实验©️【深蓝具身智能】编译
(2)TAGR 何时被激活?
词触发统计
几何属性词(如 shape/square/rectangular)与空间动词(throwing/go/away)激活概率高;计数或泛化询问(many/nine)激活低——语言信号在一定程度上显式提示是否需要3D推理。

▲图6|单词激活分析:不同提示类型的激活概率©️【深蓝具身智能】编译
定性案例:
案例一:问“桌子形状”为何,若出现“正方形/长方形”的歧义,3D门控激活概率更高(如 0.73);
案例二:圆桌场景,二维线索足够时,激活概率较低(如 0.52);
右侧两例为计数/颜色识别时门控不激活,体现 TAGR 能在不需要3D时自动省略。

▲图7|训练数据集的构成©️【深蓝具身智能】编译
(3)与 SOTA 模型在 2D/3D 基准上的对比
2D 四基准:
在仅 8B 参数规模下,OmniEVA 全部达成 SOTA,平均 +10.45 超过上一代 SOTA(Robobrain-32B),并显著优于更大规模的 GPT-4o、Gemini-2.5-Pro 等。

▲图8|对比实验定量结果©️【深蓝具身智能】编译
3D 四基准:
在 SQA3D / ScanQA / Scan2Cap 上分别领先(+2.3 / +0.3 / +8.5);
在 ScanRefer(3D grounding)上总体略逊,但在纯文本 I/O的同等设置下达到 55.8,显著超过此前最佳 44.4(Spatial-3D-LLM),显示了端到端推理的稳健性与泛化能力。
导航下游:
预测 3D 子目标引导探索,SR/SPL 均超越 UniNavid,其中 SPL +5.4;

▲图9|对比实验定量结果©️【深蓝具身智能】编译
具身感知推理:从语义正确到可执行
(1)原子能力与下游任务上的量化结果
原子能力:
Where2Approach+28.95%;
Where2Fit+34.28%。
下游任务:
Mobile Placement:Easy +43%,Hard +50%。

▲图9|TE-GRPO方法在局部移动操作任务中的消融结果©️【深蓝具身智能】编译
(2)边界观察(抓取相关)
当低层抓取策略存在瓶颈时,r_embod 的作用会被掣肘:Where2Grasp 基准提升 +26.59%,但 Mobile Pickup 只有 +18.7%(靠 r_task),而仅靠 r_embod时无显著增益。
这表明:即使具身可行性信号到位,底层控制策略的泛化能力仍是最终能否成功执行的关键约束。
(3)对具身约束的适配过程

▲图10|OmniEVA在实施例感知约束下的推理过程©️【深蓝具身智能】编译
推理轨迹:
先做任务级分析(场景理解、常识性空间分析、文本定位可放置区域),再引入物理约束(可达性、工作空间边界)过滤候选,输出满足任务且可执行的放置区域。
对比:
未用 TE-GRPO 的模型也能识别桌面空位(任务层面可行),但常给出超出机械臂范围或执行效率较差的位置;
使用 TE-GRPO 的 OmniEVA 则更稳定地选择可达、可执行的区域。
长时序任务的组合与编排
在模拟器的 End-to-End Delivery 上验证:要求跨整层办公室完成端到端递送,评估整体成功率与平均完成时长;
通过将 Where2Go / Where2Approach / Where2Fit / Where2Grasp 等原子能力按需组合与排序,模型展现出面向真实流程的长时序执行能力。

总结
OmniEVA 通过任务自适应的三维 Grounding(TAGR),在确实需要空间/遮挡/几何推理时才按需注入 3D 位置信息;用具身感知的强化微调(TE-GRPO),把任务目标与机器人可达性、工作空间等物理约束写进训练与推理回路。
更重要的是,论文也给出了边界:
当底层抓取策略泛化不足时,具身约束奖励的收益会被削弱。
这为下一步的落地路线给出清晰指向——补齐低层技能的稳健性与泛化,继续打通从视觉语言理解到可执行控制的闭环。
面向实际应用,OmniEVA 的按需 3D 与具身约束范式,为“长时序、多约束、端到端”的机器人任务提供了一条可复制的工程路径。
各位读者觉得把这套思路接到自己的平台上,最先要补的短板会是哪一环:数据、算力,还是低层策略?
编辑|阿豹
审编|具身君
Ref
论文题目:Embodied Versatile PlAnner via Task-Adaptive3D-Grounded and Embodiment-aware Reasoning
论文地址:https://arxiv.org/pdf/2509.09332
项目地址:https://omnieva.github.io/
工作投稿|商务合作|转载
:SL13126828869(微信号)
>>>现在成为星友,特享99元/年<<<


【具身宝典】具身智能主流技术方案是什么?搞模仿学习,还是强化学习?|看完还不懂具身智能中的「语义地图」,我吃了!|你真的了解无监督强化学习吗?3 篇标志性文章解读具身智能的“第一性原理”|解析|具身智能:大模型如何让机器人实现“从冰箱里拿一瓶可乐”?|盘点 | 5年VLA进化之路,45篇代表性工作!它凭什么成为具身智能「新范式」?动态避障技术解析!聊一聊具身智能体如何在复杂环境中实现避障
【技术深度】具身智能30年权力转移:谁杀死了PID?大模型正在吃掉传统控制论的午餐……|全面盘点:机器人在未知环境探索的3大技术路线,优缺点对比、应用案例!|照搬=最佳实践?分享真正的 VLA 微调高手,“常用”的3大具身智能VLA模型!机器人开源=复现地狱?这2大核武器级方案解决机器人通用性难题,破解“形态诅咒”!|视觉-语言-导航(VLN)技术梳理:算法框架、学习范式、四大实践|盘点:17个具身智能领域核心【数据集】,涵盖从单一到复合的 7 大常见任务类别||90%机器人项目栽在本地化?【盘点】3种经典部署路径,破解长距自主任务瓶颈!|VLA模型的「核心引擎」:盘点5类核心动作Token,如何驱动机器人精准操作?
【先锋观点】周博宇 | 具身智能:一场需要谦逊与耐心的科学远征|许华哲:具身智能需要从ImageNet做起吗?|独家|ICRA冠军导师、最佳论文获得者眼中“被低估但潜力巨大”的具身智能路径|独家解读 | 从OpenAI姚顺雨观点切入:强化学习终于泛化,具身智能将不只是“感知动作”
【非开源代码复现】非开源代码复现 | 首个能抓取不同轻薄纸类的触觉灵巧手-臂系统PP-Tac(RSS 2025)|独家复现实录|全球首个「窗口级」VLN系统:实现空中无人机最后一公里配送|不碰真机也不仿真?(伪代码)伯克利最新:仅用一部手机,生成大规模高质量机器人训练数据!
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文










