
今天要为大家解析一个令人兴奋的开源项目——宇树科技(Unitree Robotics)在2025年开源的UnifoLM-WMA-0(统一世界模型-动作架构)
一、什么是世界模型?为什么它如此重要?
在深入解析UnifoLM-WMA-0之前,我们先来理解一个核心概念:世界模型。
想象一下,你要伸手去拿桌上的水杯。在行动之前,你的大脑会“模拟”这个动作:手应该怎么移动,会不会碰到其他东西,杯子会不会被打翻……
这种“模拟”能力就是世界模型的核心:
在大脑里构建一个“世界的复制品”,它让你能够预测动作的结果,从而做出更明智的决策。
对机器人来说,世界模型就是让它具备这种“想象未来”的能力。传统的机器人控制依赖于预先编程的规则或大量的试错训练,但这种方式在复杂多变的环境中显得力不从心。
世界模型通过学习和模拟环境的动态变化,让机器人能够预测自身动作的后果,从而更智能地规划行为。
UnifoLM-WMA-0的突破在于
它将世界模型 + 动作策略紧密结合,同时支持决策和仿真两种模式,适用于多种机器人平台和任务。
二、解析:UnifoLM-WMA-0的核心创新
1. 统一的世界模型-动作架构
传统的机器人学习,通常是“感知 → 决策 → 执行”,各模块之间割裂。
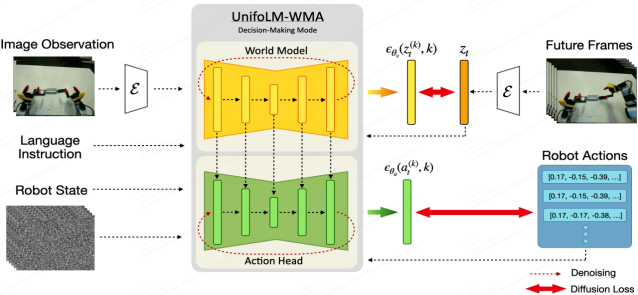
UnifoLM-WMA-0 把“世界模型”和“动作生成”结合在一起,形成闭环。世界模型不仅预测未来的环境视频,还通过“动作头”直接输出动作策略。这意味着机器人在做决策时,能够考虑到对未来环境的预判,从而做出更优的选择。
2. 双模式运行:决策与仿真
决策模式:基于当前观测(如图像、语言指令)预测未来的物理交互信息,辅助生成动作策略。
仿真模式:世界模型直接作为模拟引擎,根据给定的机器人动作生成高度逼真的环境反馈视频,模拟交互过程。
这一点类似于生成式对抗网络中的前向建模,但侧重物理交互,可视化为真实机器人“想象”未来场景。
3. 跨平台通用性
UnifoLM-WMA-0是专为通用机器人学习设计的,可以适配多种形态的机器人,包括机械臂、四足机器人、人形机器人等。
它通过在多场景数据集上训练,能够处理不同任务(如堆积物体、抓取定位、清理收纳等)的视觉与动作信息。
4. 开源与实机验证
宇树科技不仅开源了训练和推理代码、模型权重,还提供了详细的示例。
在真机演示中,UnifoLM-WMA-0已经成功应用于机械臂堆积积木、双臂协作收纳物品等任务,预测结果与实际操作高度吻合。
模型
模型 | 描述 | 链接 |
UnifoLM-WMA-0Base | 在 Open-X 数据集微调后的模型 | HuggingFace |
UnifoLM-WMA-0Dual | 在五个宇树科技开源数据集上,决策和仿真双模式,联合微调后的模型 | HuggingFace |
三、框架解读:UnifoLM-WMA-0 怎么运作?
UnifoLM-WMA-0的整体架构围绕世界模型模块和动作策略模块展开,支持多模态输入(图像、状态、语言指令),输出包括未来视频帧和动作信号。具体来说,它可以分为以下几个部分:
1. 世界模型模块(World Model)
这是系统的核心,用于模拟物理交互。类似于条件视频生成网络,能够接受环境图像、机器人状态/动作信息和语言指令,预测未来的视频帧。
在决策模式下,世界模型对当前场景进行编码,然后迭代解码生成未来帧,同时将关键信息反馈给策略网络。
2. 动作策略模块
包括一个轻量的动作头或策略网络,用于生成机器人动作序列。
在决策模式中,动作头连接到世界模型的隐状态或预测输出,基于预测的未来信息生成动作信号。
不仅能预测 8 步或 16 步动作,还能处理更长时间的任务(比如十几秒的连续操作)。
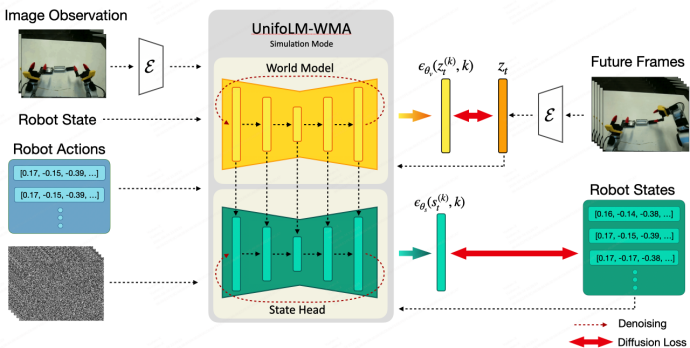
3. 仿真模块
在仿真模式下,系统将已执行的动作序列作为输入,通过世界模型生成环境反馈视频。
例如,给定一段机械臂的取放动作,模型可以输出预测的场景变化视频。
下图展示了仿真模式架构:输入包括当前图像、机器人状态和一系列未来动作,世界模型生成未来帧和状态(右上未来视频及蓝色状态头),模拟出动作执行后的效果。

图片原自unitree官网
4. 输入输出形式
输入:当前环境图像(RGB视频帧)、机器人状态信息(关节角度、末端位置等,以 HDF5 文件保存)、语言指令。
输出:未来环境图像序列、机器人动作(决策模式)或状态(仿真模式)。
团队规范了数据格式:在训练数据中,所有视频文件存放在 videos/ 目录下,而机器人状态和动作以 .h5 文件形式存储在 transitions/ 目录,配合一个 CSV 文件对齐帧和状态
四、结构与运行流程
UnifoLM-WMA-0的开源代码在GitHub上发布(仓库名:unifolm-world-model-action)
代码架构
unifolm-world-model-action/ ├── assets/ # 媒体资源(训练过程或结果图像、GIF 演示等) ├── configs/ # 配置文件(训练/推理的参数设置) │ ├── train/ # 训练相关的 YAML/JSON 配置(模型参数、数据路径等) │ └── inference/ # 推理相关配置(使用哪种模式、数据路径等) ├── examples/ # 示例输入与提示(如交互式仿真的示例 prompts) ├── external/ # 外部依赖库(例如集成的第三方代码包) ├── prepare_data/ # 数据预处理脚本(格式转换、数据切分等) ├── scripts/ # 运行脚本(训练、评估、仿真模式推理等) └── src/ └── unitree_worldmodel/ # 核心 Python 包:世界模型和策略实现 ├── data/ # 数据加载、变换和 DataLoader ├── models/ # 模型定义(网络架构、骨干) ├── modules/ # 自定义模块(如世界模型类、UNet、Transformer 结构) └── utils/ # 工具函数(日志、指标计算等) |
数据准备
训练数据需要遵循特定格式,包括视频目录(MP4文件)和状态目录(HDF5文件),以及一个CSV文件对齐图像与状态。例如:
target_dir/ ├── videos/ # 视频文件 ├── transitions/ # 状态和动作数据(HDF5格式) └── dataset1_name.csv # 对齐表格 |
训练脚本与流程
项目中主要的训练脚本位于 scripts/train.sh
训练分为三个步骤:
1. 视频模型微调(Fine-tuning):在Open-X数据集上微调视频生成模型,使其适配机器人场景。
2. 决策模式训练(Policy Training):在目标任务数据上训练世界模型,优化预测未来视频和动作的能力。
3. 仿真模式训练:在同一数据上训练世界模型的仿真模式,使其更准确地还原环境反馈。
configs/train/config.yaml 中可以设置pretrained_checkpoint(加载第一步模型)
decision_making_only(是否只训练决策模式)等参数。
完成配置后,执行 bash scripts/train.sh 即可启动训练。
训练过程中,模型会同时优化视频生成损失和动作预测损失(即行为克隆风格的监督信号),最终得到可用于推理的检查点模型。
推理和仿真
项目提供了交互式仿真模式推理脚本(scripts/run_world_model_interaction.sh
使用时需要准备一个 prompt 目录,里面放置示例图片和对应的机器人状态/指令
格式可参考 examples/world_model_interaction_prompts
然后在配置文件 configs/inference/world_model_interaction.yaml 中指定 pretrained_checkpoint、data_dir 等。
运行该脚本即可看到世界模型生成的未来视频结果。该过程演示如何将模型作为“虚拟沙盘”让机器人进行模拟试验。
核心代码模块
src/unitree_worldmodel/models/:定义网络结构(如视频生成的UNet/Diffusion架构)。
src/unitree_worldmodel/modules/:包含世界模型总体结构的封装类。
src/unitree_worldmodel/data/:实现数据加载和处理的PyTorch Dataset和DataLoader。
五、模型技术细节:架构与训练
UnifoLM-WMA-0的世界模型基于扩散模型(Diffusion Model)生成视频序列,类似于DynamiCrafter等工作中使用的技术。训练时,模型输入当前视觉观测和文本指令/动作信息,生成未来连续视频帧。
训练目标与损失
视频生成:使用扩散模型的去噪损失,使生成的帧序列与真实视频匹配。
动作预测:通过行为克隆式的回归损失(如均方误差)拟合真实动作序列。
输入输出示例
决策模式:输入当前图像、文本指令(如“抓起摄像机”)和机器人状态;输出未来视频帧和动作序列。
仿真模式:输入当前图像和动作序列;输出模拟执行结果的未来视频和新状态。
六、对比分析:与其它主流世界模型
1. DreamerV3
Dreamer系列基于强化学习,通过学习隐空间动态实现策略优化,但主要面向游戏和模拟环境,不直接生成像素级视频。UnifoLM-WMA-0则注重真实机器人任务的视觉预测能力。
2. GENIE2(DeepMind)
GENIE2专注于生成虚拟游戏环境,而UnifoLM-WMA-0直接处理真实视频和物理场景,强调物理交互的现实性。
3. RT-2(Google)
RT-2利用大规模视觉-语言预训练模型生成动作序列,但不具备显式的环境仿真模块。UnifoLM-WMA-0则通过视频预测和仿真模式,提供了更全面的环境交互能力。
七、应用意义与场景
UnifoLM-WMA-0 的意义不仅在学术,更在于它打开了机器人落地的想象力。
1. 通用机器人学习
传统机器人每换一个场景或任务都要重新写规则或训练。而 UnifoLM-WMA-0通过世界模型,能让机器人能快速适应新任务。
2. 仿真加速
现实收集数据太贵 → 世界模型自带仿真引擎,可以生成高质量合成数据。
3. 决策优化
机器人能“未卜先知”,减少试错成本。
比如:搬运 fragile 物品时,可以先预测“是不是会掉”。
4. 多机器人形态支持
不仅四足机器人,双足、人形、机械臂都能用。
这意味着一个统一架构能支持不同机器人平台。
现实应用场景
家庭服务:帮忙收拾、分类物品。
灾难救援:预测路径是否会坍塌,选择安全路线。
仓储物流:优化抓取、放置动作,减少出错率。
工业装配:提前预测工件交互,保证精准操作
结语
UnifoLM-WMA-0是机器人领域的一个重要突破,它让机器人从“盲目执行”进化到“有脑子会思考”,这是走向通用机器人(General-Purpose Robot)的关键一步。
未来几年,我们可能会看到:
世界模型成为机器人标配,就像 LLM 成为对话 AI 标配。
家用机器人能在复杂环境里自主学习,而不是靠写死规则。
工业和救援场景的机器人更加智能,减少事故和失误。
参考资料:
UnifoLM-WMA-0 GitHub仓库











