从四足机器人 → 人形机器人的无缝衔接
——通用导航大脑
在具身智能的发展版图里,导航几乎是绕不开的核心能力,但问题在于导航能力的“碎片化”——
目标导航、视觉语言导航、自动驾驶……每个任务都需要量身定制的模型;
四足机器人、无人机、轮式小车……每种硬件平台都构成了一个独立的技术孤岛。
北大王鹤老师团队新工作提出了 Embodied Navigation Foundation Model(NavFoM),尝试把导航也做成“基础模型”。
研究团队收集了超过 1270 万个样本,覆盖了四足、无人机、车辆等多种形态,以及视觉语言导航、目标搜索、目标跟踪、自动驾驶等多类任务。
模型测试结果在多个主流基准上达到或刷新了 SOTA,并且在真实机器人上完成了跨任务、跨平台的验证。
这意味着,未来我们可能真的能有一个“通用导航大脑”,驱动各种机器人去执行多样化的任务。

为什么要做导航的“基础模型”?
因为它不仅仅是在做一个“更强的导航算法”,而是在尝试回答一个更根本的问题:
能不能用一套统一的模型,驱动不同形态的机器人完成不同的导航任务?
NavFoM 的设计正是为了解决这个问题。它提出了两项关键创新:
TVI Tokens —— 让模型能识别不同相机视角和时间顺序,从而兼容单摄像头、多摄像头,短时长、长时长的各种任务输入。
BATS 策略 —— 在有限算力约束下,自适应抽取关键信息,既保持性能,又能在真实机器人上高效运行。

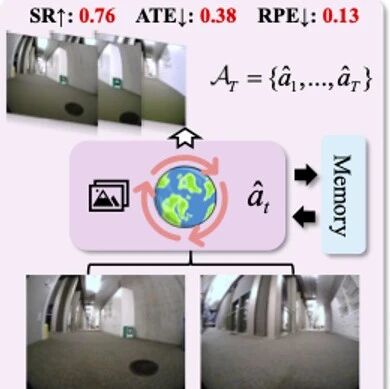
▲图1|左侧展示的是 NavFoM 的整体架构,右侧则给出了真实机器人实验的结果。可以看到,该方法在不同任务和不同机器人形态下都展现出了稳定的性能,验证了其跨任务、跨平台的泛化能力©️【深蓝具身智能】编译
接下来,我们将深入解读论文中的核心方法,看看研究团队是如何构建这样一个“导航基础模型”的。

方法解析
总体框架
NavFoM 的目标,是在不同任务和不同具身形态下实现统一的导航能力。
为此,研究团队采用了一个双分支架构:
导航分支:根据视觉输入和历史信息,预测未来的动作轨迹。
问答分支:基于相同的感知输入,输出文本化的推理或解释结果。
这种设计让模型既能做决策(走哪条路),又能做推理(回答环境相关的问题),实现了感知—推理—控制的统一。

▲图2|图中展示了 NavFoM 的整体流程。该方法提供了一个统一的框架,同时兼顾 图像问答、视频问答和导航任务。在输入阶段,文本与视觉信息通过 时序-视角指示符(TVI tokens) 进行组织。在输出阶段,模型针对不同任务采用不同的分支:在问答任务中使用自回归的语言建模头生成答案,而在导航任务中则通过规划头直接预测未来轨迹©️【深蓝具身智能】编译
模型的训练数据来自四类任务:
视觉语言导航(VLN)、目标搜索(OVON)、目标跟踪(EVT-Bench)、自动驾驶(NavSim)
此外,还引入了“大规模导航相关问答数据”,帮助模型学到更强的语言与环境对齐能力。
输入与时序建模
导航任务的关键在于处理多视角、多时间的感知输入。
论文提出了 Temporal-Viewpoint Indicator (TVI) Tokens,它的作用是:
用一组特殊的 token 来编码“这一帧来自哪个相机、属于哪个时间点”。
这样,模型就能区分正前方视角还是侧面视角、当前帧还是历史帧,从而避免信息混淆。

▲图3|图中展示了 时序-视角指示符(TVI tokens) 的可视化结果。研究团队采用聚类算法将高维嵌入映射到二维空间,从而直观呈现不同时间与视角下的特征分布情况©️【深蓝具身智能】编译
TVI tokens 的设计保证了模型可以无缝处理单摄像头 / 多摄像头、短时 / 长时的数据输入。
历史信息压缩
在大规模数据和多帧输入下,如果把所有帧都直接喂给模型,算力和显存开销会非常大。
为此,作者提出了 Budget-Aware Temporal Sampling (BATS) 策略:
在有限 token 预算下,动态挑选最关键的历史帧。
例如,任务早期可能需要更密集的历史信息,而任务后期则可以抽取更稀疏的帧。
这样既保留了时序上下文,又能控制模型推理成本。

▲图4|图中展示了 BATS 策略及其对应的时间开销。(a) 在固定 token 预算 B = 1600 的条件下,给出了最终时刻 T 下不同时刻 t 的采样概率分布。(b) 当最大时长为 T = 125 时,展示了不同 token 预算下,各个时刻的采样概率变化。(c) 对比了使用 BATS 与不使用 BATS(即保留所有帧)时的推理时间差异。可以看到,BATS 在控制计算成本的同时,依然能够高效保留关键信息,显著降低了推理延迟©️【深蓝具身智能】编译
消融实验显示,BATS 比固定采样或随机采样效果更优,尤其在长时间导航任务中。

▲图5|图中展示了 NavFoM 在不同任务下的 token 组织策略。©️【深蓝具身智能】编译
在图像问答任务中,模型使用细粒度的视觉 token,并仅结合 TVI tokens 的基础嵌入。
在视频问答任务中,采用粗粒度的视觉 token,同时引入基础嵌入与时间嵌入。
在导航任务中,则结合了粗粒度与细粒度的视觉 token,整合了基础、时间和角度三个维度的 TVI 嵌入信息。
这种灵活的 token 组织方式,使 NavFoM 能够在不同任务间自适应地处理信息,从而实现跨任务的统一建模。
多任务联合训练
为了让模型真正具备“通用性”,NavFoM 采用了多任务联合训练:
不同任务的数据被统一格式化后输入同一个模型。
模型通过共享的感知 backbone,提取通用的视觉—语言—时序特征。
在输出层,则分为导航分支和问答分支,分别学习动作预测和文本生成。

▲图6|图中展示了 离线视觉特征缓存机制。研究团队预先对视频帧和导航历史进行了计算,并将其存储为粗粒度的视觉 token,以便在模型推理过程中高效调用©️【深蓝具身智能】编译
这种方式让模型能够在不同任务间迁移。
例如:从目标搜索学到的空间推理能力,可以反哺到自动驾驶;从问答数据中学到的语义知识,可以帮助视觉导航。
训练目标
整个模型的学习目标由两部分构成:
轨迹预测损失:让导航分支能够预测与专家演示轨迹一致的路径。
语言生成损失:让问答分支能生成符合语义的回答。
两者结合,确保模型既能走得对,也能说得清。
小结
总的来说,NavFoM 在方法上有三大亮点:
TVI Tokens —— 解决多视角、多时间输入的表示问题;
BATS 策略 —— 在有限算力下高效建模历史信息;
多任务联合训练 —— 让模型获得跨任务、跨平台的泛化能力。

实验结果与分析
研究团队在仿真环境和真实机器人上对 NavFoM 进行了全面评估,覆盖了视觉语言导航、目标搜索、目标跟踪和自动驾驶四大类任务。
结果显示,单一模型不仅能在多个任务中表现优异,还具备跨形态的泛化能力。
视觉语言导航(VLN-CE, RxR)
单视角条件下,NavFoM 的成功率从 51.8% 提升到 57.4%。
多视角条件下,成功率从 56.3% 提升到 64.4%。
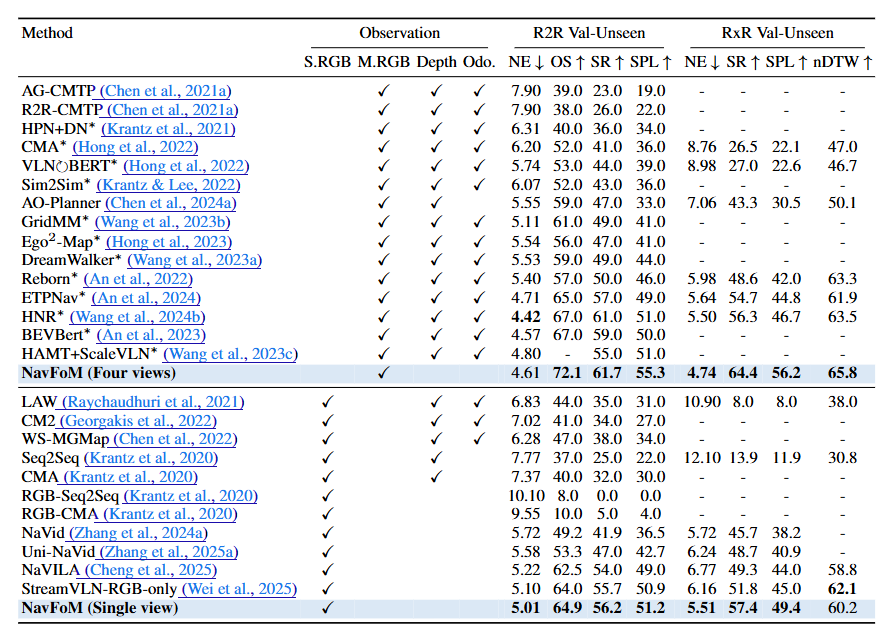
▲图7|VLN-CE视觉语言导航任务定量实验结果©️【深蓝具身智能】编译
结果说明 NavFoM 在理解自然语言指令和执行复杂导航路径上更稳健。

▲VLN-CE视觉语言导航任务过程可视化©️【深蓝具身智能】编译
零样本目标搜索(HM3D-OVON)
成功率提升到 45.2%,超过此前最佳方法的 43.6%。

▲图8|HM3D-OVON零样本物体导航定量实验结果©️【深蓝具身智能】编译
结论:在没有任务专门训练的情况下,NavFoM 依然能准确找到目标物体,显示出强大的零样本能力。
标跟踪(EVT-Bench)
单视角条件下,成功率达到 85.0%。
四视角条件下,进一步提升到 88.4%,超过专门微调的 TrackVLA。

▲图9|EVT-Bench目标跟踪任务定量实验结果©️【深蓝具身智能】编译
结论:多视角融合+TVI tokens 的设计在这里展现出显著优势。

▲EVT-Bench目标跟踪任务可视化©️【深蓝具身智能】编译
自动驾驶(NavSim)
在 8 视角条件下,表现分数(PDMS)达到 84.3,接近专门的 DrivingGPT、DiffusionDrive 等方法。
即使没有针对驾驶任务单独优化,也依然具备极强的泛化性。

▲图10|NavSim自动驾驶数据集定量实验结果©️【深蓝具身智能】编译

▲NavFoM自动驾驶任务可视化©️【深蓝具身智能】编译
真实机器人测试
研究团队在四足、人形、无人机、轮式机器人上进行了 110 个实测案例,结果表明:
NavFoM 明显优于之前的 Uni-NaVid,且在实际部署场景中也能完成跨任务的导航。

消融实验
多任务训练:比单任务显著更强,尤其是在搜索和跟踪任务中。
相机数量:四个相机时效果最佳,六个反而略微下降。
TVI Tokens & BATS:均显著优于替代方案,证明设计有效性。

总结
从结果来看,NavFoM 不仅能在实验室基准上打破记录,还能真正跑上不同形态的机器人,在真实世界中完成复杂任务。这意味着:
一个能够适配无人机、四足、人形甚至无人车的统一导航大脑,正在成为现实。
当然,挑战依然存在,比如算力成本、数据偏差、长时间任务的稳定性。但不可否认,NavFoM 已经展示了“基础模型”范式的可行性。
未来,当这些模型进一步压缩优化、结合更多模态数据,我们或许会看到机器人像人一样,学会在陌生环境里自然、灵活地行走和探索。
各位读者朋友认为:这样的“通用导航大脑”,是具身智能导航任务的通解吗?
编辑|阿豹
审编|具身君
Ref:
论文题目:EMBODIED NAVIGATION FOUNDATION MODEL
论文作者:Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Jiahang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, Yuxin Fan, Wenjun Li, Zhibo Chen, Fei Gao, Qi Wu, Zhizheng Zhang, He Wang
论文地址:https://arxiv.org/pdf/2509.12129
项目地址:https://pku-epic.github.io/NavFoM-Web/
工作投稿|商务合作|转载
:SL13126828869(微信号)
>>>现在成为星友,特享99元/年<<<


【具身宝典】||||
【技术深度】|||||||
【先锋观点】|||
【非开源代码复现】||
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文