论文题目:Think Only When You Need with Large Hybrid-Reasoning Models
论文地址:https://arxiv.org/pdf/2505.14631

创新点
LHRMs是首个能够根据用户查询的上下文信息自适应决定是否进行推理思考的模型。这种模型能够动态地选择是否启用扩展的思考过程,从而在推理能力和计算效率之间取得平衡。
HAcc用于量化评估模型在混合思考能力上的表现,通过比较模型选择的推理模式与专家标注的最优模式的匹配程度来衡量。
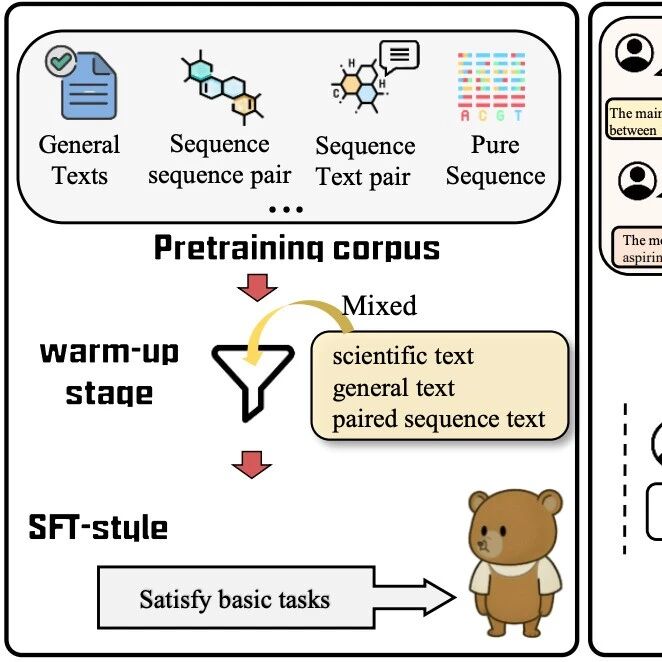
方法
本文提出了一种新型的大型混合推理模型(Large Hybrid-Reasoning Models, LHRMs),旨在解决现有大型推理模型(LRMs)在简单查询上过度思考的问题,同时保留其在复杂任务中的推理能力。研究方法的核心在于通过引入两种推理模式——思考模式(Thinking Mode)和非思考模式(No-Thinking Mode),并设计两阶段训练流程来实现模型的自适应推理能力。第一阶段是混合微调(Hybrid Fine-Tuning, HFT),通过混合格式的监督微调,使模型能够同时学习两种推理模式,避免了在冷启动阶段的不稳定性。第二阶段是混合组策略优化(Hybrid Group Policy Optimization, HGPO),通过在线强化学习,进一步优化模型在不同查询上选择合适推理模式的能力,同时提升模型生成更有帮助且无害的响应的能力。
不同模型的示例响应

本图展示了三种不同模型(Qwen2.5-7B-Instruct、DeepSeek-R1-Distill-Qwen-7B 和 LHRMs-7B)在推理相关任务(上半部分)和日常问答任务(下半部分)中的示例响应。对于推理任务,LHRMs-7B通过思考步骤给出了正确答案,而其他模型要么回答错误,要么虽然步骤正确但最终答案错误。在日常问答任务中,LHRMs-7B能够直接给出简洁的回答,而其他模型要么回答过于冗长,要么需要额外的思考步骤。这表明LHRMs能够在复杂推理和简单查询之间自适应地选择合适的推理模式,既保留了强大的推理能力,又提高了日常交互的效率。
混合组策略优化的示意图

本图展示了混合组策略优化(HGPO)的流程。HGPO通过以下步骤实现:首先,对于每个查询q,使用两种推理模式(思考模式和非思考模式)分别采样多组输出;然后,利用奖励模型对这些输出进行评分,并根据评分分配奖励;接着,计算每个输出的优势值,并通过更新策略模型来优化模型的推理模式选择能力。图中还展示了如何通过优势估计器(如GRPO)来计算优势值,并通过策略损失函数来更新模型参数。HGPO的目标是教会模型在何时进行扩展思考,同时生成更有帮助且无害的响应。
优势估计器和margin δ的影响分析

本图展示了在HGPO训练中,不同优势估计器(如RLOO、REINFORCE++和GRPO)以及不同margin值δ对模型推理模式选择的影响。图(a)表明,不同的优势估计器在模型性能上具有竞争力,说明HGPO对优势估计器的选择具有鲁棒性。图(b)展示了不同δ值下模型对两种推理模式的偏好变化。较大的δ值会使模型更倾向于选择非思考模式,而较小的δ值则使模型更倾向于选择思考模式。这表明δ可以作为控制模型推理行为的调节参数,根据具体应用需求调整模型在思考模式和非思考模式之间的偏好。
实验

本表展示了不同模型在多个任务和基准测试中的性能对比。这个表格的核心目的是通过量化指标来评估不同模型的推理能力和泛化能力,同时突出本文提出的 LHRMs(Large Hybrid-Reasoning Models) 相比于其他模型的优势。从表格中的关键数值可以看出,LHRMs 在所有任务中均表现优异,优于或至少与现有的 LLMs 和 LRMs 相当。综上所述,Table 1 通过详细的性能对比,清晰地展示了 LHRMs 在推理和泛化能力上的优势。它不仅证明了 LHRMs 在处理复杂任务时的推理能力,还表明了其在简单任务上的效率提升。此外,Hacc 指标的突出表现进一步验证了 LHRMs 在动态选择推理模式上的有效性。这些结果为 LHRMs 提供了有力的支持,证明了其作为一种新型混合推理模型的潜力和实用性。
-- END --

关注“学姐带你玩AI”公众号,回复“2025大模型”
领取2025大模型创新方案合集+开源代码