
到底是谁说,今天的主要工作是等放假?明明是(被迫)跟着各家AI团队卷生卷死:
继昨晚、今日凌晨,智谱、阿里、蚂蚁、智源也都赶在节前最后一天“卷”起来了!

(即梦AI生成)

智谱:GLM-4.6重磅上线,目前国内最强的Coding模型
今天下午14:53,智谱正式发布并开源新一代大模型GLM-4.6,在真实编程、长上下文处理、推理能力、信息搜索、写作能力与智能体应用等多个方面实现全面提升。

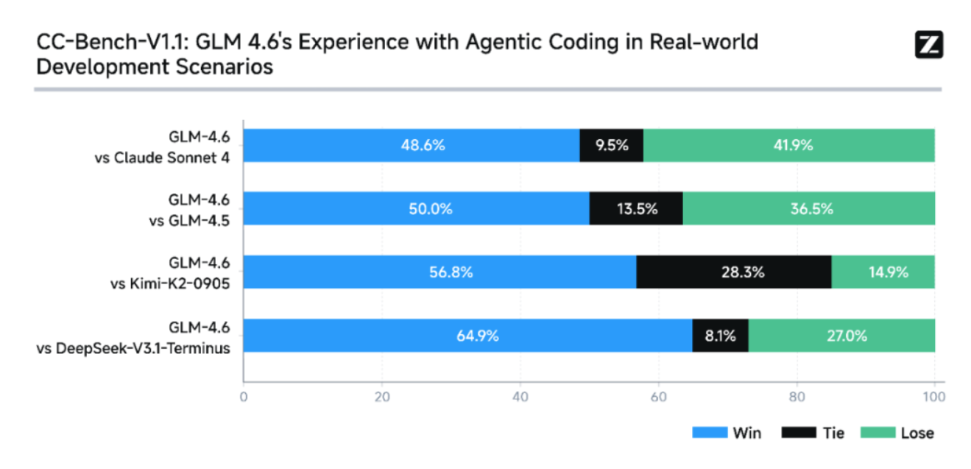
据官方介绍,GLM-4.6在公开基准和真实编程任务中的表现已对齐Claude Sonnet 4、超越DeepSeek V3.2-Exp,是目前国内最强的Coding模型:
(1)综合评测:在8大权威测试(AIME 25、LCB v6、HLE、SWE-Bench Verified、BrowseComp、Terminal-Bench、τ^2-Bench、GPQA)中,GLM-4.6在部分榜单表现对齐Claude Sonnet 4/Claude Sonnet 4.5,稳居国产模型首位;

(2)真实编程评测:在Claude Code环境下完成74个场景任务,结果显示,GLM-4.6实测超过Claude Sonnet 4,同时平均token消耗比GLM-4.5低30%,为同类模型最低。
值得一提的是,GLM-4.6已在寒武纪国产芯片上实现FP8+Int4混合量化部署,这是首套投产的芯片一体化方案,同时基于vLLM框架,也能在摩尔线程新一代GPU上以原生FP8精度稳定运行。
目前,GLM-4.6已全面上线智谱MaaS平台bigmodel.cn、z.ai、智谱清言,海外用户可通过z.ai使用 API,同时将在Hugging Face和ModelScope开源,遵循MIT协议。

阿里通义Qwen:Qwen3-LiveTranslate-Flash,视、听、说全模态同传大模型
而仅仅时隔半小时后,阿里通义Qwen团队在下午15:22,重磅介绍了视、听、说全模态同传大模型Qwen3-LiveTranslate-Flash。

Qwen3-LiveTranslate-Flash是一款高精度、高响应、高鲁棒性的多语言实时音视频同传大模型,依托于Qwen3-Omni强大的基座能力、海量多模态数据、百万小时音视频数据,实现了覆盖18种语言的离线和实时两种音视频翻译能力。
不仅如此,Qwen3-LiveTranslate-Flash可实现最低3秒延迟的同传体验,采用语义单元预测技术缓解跨语言调序问题,实现与离线翻译几乎无损的翻译质量。海量语音数据训练也保证了音色自然,可根据原语音内容自适应调节语气和表现力。
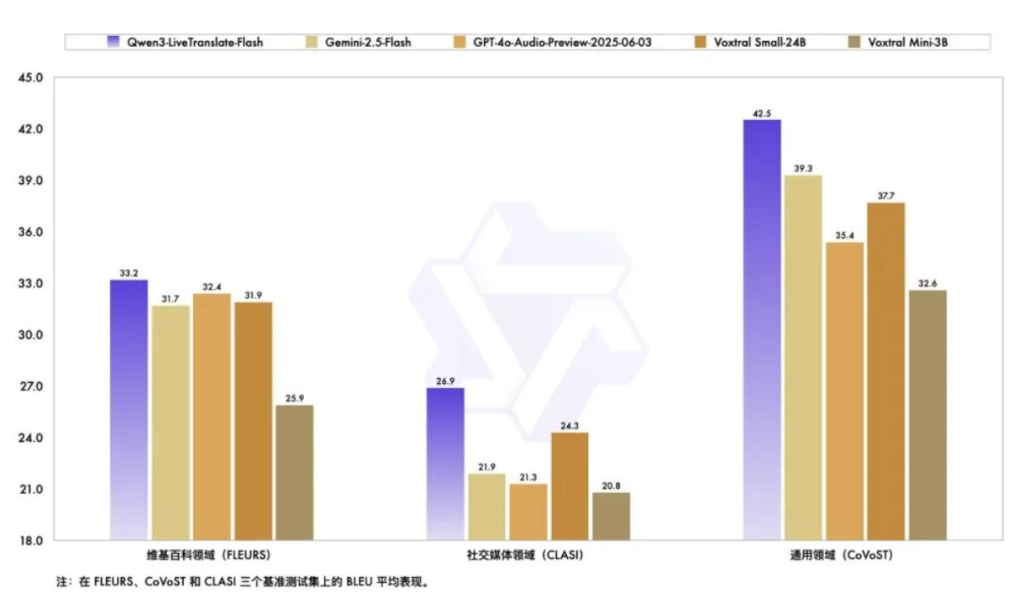
从公开测试集的结果来看,Qwen3-LiveTranslate-Flash在中英及多语言语音翻译准确度方面显著优于Gemini-2.5-Flash、GPT-4o-Audio-Preview和Voxtral Small-24B等主流大模型:

在不同领域和复杂声学环境下,Qwen3-LiveTranslate-Flash的翻译性能也依然保持领先:
同时,Qwen3-LiveTranslate-Flash还首次引入视觉上下文增强技术,让模型不仅“听得懂”,还能“看得懂”,进一步提升了对嘈杂音频、一词多译及专有名词翻译的精度,在实时场景中的优势也更为明显。
事实上早在上周,阿里Qwen团队负责人就曾在X平台上透露,阿里Qwen团队要发布6个“新东西”,包括1个产品,2个开源模型,3个API接口,具体为Qwen3Guard、Qwen Chat、Qwen3-LiveTranslate-Flash、Qwen3-Coder升级、Qwen3-VL和Qwen3-Max发布。

蚂蚁:开源首个万亿参数推理大模型!
在今日凌晨Claude Sonnet4.5发布的同时,蚂蚁集团也宣布开源自研的首个万亿参数大模型Ring-1T-preview。

据介绍,Ring-1T-preview是万亿参数推理大模型Ring-1T的预览版,但其自然语言推理能力已相当亮眼。例如,在数学能力测试AIME 25上,Ring-1T-preview取得92.6分,超越所有已知开源模型及Gemini 2.5 Pro,更接近GPT-5(无工具使用)的94.6分;在代码生成领域的CodeForces测试中,Ring-1T-preview更是斩获94.69分,直接超过GPT-5。

不仅如此,在LiveCodeBench、ARC-AGI-v1等权威榜单上,Ring-1T-preview也位列开源模型首位。据悉,蚂蚁百灵团队还在国际奥林匹克数学竞赛(IMO25)上对其推理能力进行了测试:Ring-1T-preview能一次性解对第三题,并在第1、2、4、5题可一次推理出部分正确答案,展现出其强大的逻辑与数学推理潜力。
蚂蚁百灵团队还透露,当前正在投入Ling2.0家族1T语言基座的后训练工作,以进一步激发万亿规模基座模型的潜力,正式版Ring-1T也在训练中,未来将进一步其极限能力。

智源:开源RoboBrain-X0,加速通用具身智能
除此之外,今天下午智源也开源了RoboBrain-X0——一个能够在零样本泛化、少量样本微调条件下,驱动多种不同真实机器人完成复杂任务的跨本体基座大模型。

根据智源介绍,RoboBrain-X0 源自 RoboBrain 的多模态基座能力,在 RoboBrain 2.0 数据基础上,进一步融合了真实机器人动作数据。通过统一建模视觉、语言与动作,RoboBrain-X0实现了跨本体的泛化与适配,具备从感知到执行的一体化能力。
为了支撑这一能力,智源还同步开源了RoboBrain-X0-Dataset,其涵盖多模态问答、开源动作、产业合作及自采数据,构建了覆盖“感知—思考—行动”的全链路训练基石。这一开放举措旨在打破“数据孤岛”,为开发者提供开箱即用的研发资源,加速机器人智能走向真实世界。
智源表示,RoboBrain-X0已全面开源,包括预训练模型、数据集和技术文档,并接入RoboBrain 2.0工具链。未来,团队将持续迭代,结合指令微调和强化学习,推动机器人在开放环境下的泛化与决策能力提升。
如此看来,双节前的最后一天,AI圈可谓是一点也没消停,甚至卷势还更胜以往……由此,不少圈内人都在喊话:别卷了别卷了,咱们要不国庆歇一歇呢?
最后由于时间有限,文中或许还遗漏了一些大模型动态,也欢迎大家在评论区留言补充~
参考链接:
推荐阅读:











