👇扫码免费加入交流群,如您有工作需要分享,欢迎联系:aigc_to_future

作者:Junyu Chen等

论文链接:https://arxiv.org/pdf/2509.25182
Git链接:https://github.com/dc-ai-projects/DC-VideoGen
亮点直击
DC-VideoGen,一个用于加速视频扩散模型的通用框架。通过低成本的后训练微调,它在视频生成中显著提高了效率。 引入了DC-AE-V,大幅减少了隐空间中的token数量,同时保持高重建质量,并能推广到更长的视频。 引入了AE-Adapt-V,使预训练的扩散模型能够快速适应新自动编码器的隐空间。 DC-VideoGen提供了加速的视频扩散模型,在保持基础模型质量的同时实现了卓越的效率,支持在单个GPU上生成高达2160×3840分辨率的视频。这为需要高效视频合成的应用提供了实际优势。此外,本文的加速模型相比基础模型具有更低的微调和训练成本,从而加速了视频生成领域的创新。

总结速览
解决的问题
现有的视频扩散模型在生成视频时效率较低,推理延迟高,且需要大量计算资源。
提出的方案
引入DC-VideoGen,一个后训练加速框架,适用于任何预训练的视频扩散模型,通过深度压缩隐空间和轻量级微调来提高效率。
应用的技术
使用DC-AE-V(深度压缩视频自动编码器),采用块因果时间设计,实现空间和时间上的压缩,同时保持重建质量。 使用AE-Adapt-V,一种稳健的适应策略,使预训练的扩散模型快速适应新隐空间。
达到的效果
使用DC-VideoGen适应预训练的模型仅需10个GPU天,加速后的模型实现了高达14.8倍的推理延迟降低。 支持在单个GPU上生成高达2160×3840分辨率的视频,同时降低微调和训练成本,促进视频生成领域的创新。
方法
DC-VideoGen 概述
由于隐空间token数量庞大,使用视频扩散模型生成高分辨率或长视频在计算上是昂贵的。此外,过高的预训练成本使得开发新的视频扩散模型既具有挑战性又风险较大。
本文从两个互补的角度解决这些挑战(下图2,左)。首先,本文通过深度压缩视频自动编码器大幅减少token数量。其次,本文引入了一种成本高效的后训练策略,以适应预训练模型到新的自动编码器。这种方法显著降低了风险、训练成本以及对大型高质量数据集的依赖。如下图2(右)所示,将本文的后训练策略应用于Wan-2.1-14B仅需10个H100 GPU天——仅为MovieGen-30B训练成本的0.05%。

预备知识和符号
本文使用 来表示视频自动编码器的配置。例如, 表示将大小为 的输入视频压缩为大小为 的隐空间。
压缩比定义为:
 在相同的重建质量下,通常优先选择更高的压缩比。本文称使用 自动编码器的扩散模型为“ 模型”。
在相同的重建质量下,通常优先选择更高的压缩比。本文称使用 自动编码器的扩散模型为“ 模型”。
一个视频扩散模型通常由一个单层的patch嵌入器(将隐空间映射到嵌入空间)、变压器块和一个将输出投射回隐空间的输出头组成(下图7c)。patch嵌入器包含一个称为patch大小的超参数 ,它进一步将隐空间在空间上压缩了一个 倍的因子。如[23]所示,在相同的总压缩比下,将更多的空间压缩分配给自动编码器而不是patch嵌入器能够产生更好的生成结果。

深度压缩视频自动编码器
现有的视频自动编码器可以根据其时间建模设计分为两类:因果和非因果。
因果。 在因果视频自动编码器中,信息仅从较早的帧流向较晚的帧(下图4b)。这种设计在推理过程中自然支持更长的视频,因为较晚帧的编码和解码不会影响较早的帧。然而,由于每帧只能利用前面帧的冗余,在深度压缩设置下,重建精度受到限制,如下图3所示。在因果设计的基础上,IV-VAE [20]指出,由于每 个输入帧被压缩为一个隐空间帧,因此在每组 帧内强制因果性是不必要的。为了解决这个问题,IV-VAE引入了一个组因果卷积,组大小为 ,以提高重建性能。然而,组大小严格与时间压缩比相关,如下图5所示,在深度压缩设置下,它对标准因果设计的重建质量提升有限。
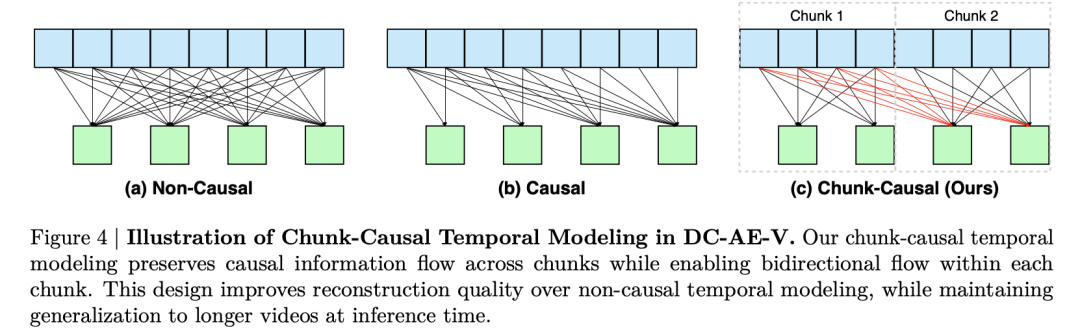


非因果。 非因果自动编码器允许帧之间的双向信息流(上图4a)。这使得每帧可以利用来自过去和未来帧的冗余,在深度压缩设置下获得更好的重建质量。然而,因为较早的帧依赖于较晚的帧,推广到更长的视频变得具有挑战性。诸如时间平铺和混合[25]之类的技术可以部分缓解这个问题,但往往会引入伪影,包括时间闪烁和边界模糊,如上图3所示。
本文引入了一种新的时间建模设计,称为chunk因果,以克服这些限制(上图4c)。其关键思想是将输入视频分割为固定大小的块,其中块大小被视为一个独立的超参数。在每个块内,本文应用双向时间建模以充分利用帧之间的冗余。然而,在块之间,本文强制因果流动,以便模型能够在推理时有效推广到更长的视频。上图5展示了关于块大小的消融研究。本文观察到增加块大小可以持续提高重建质量。在本文的最终设计中,本文采用了块大小为40,因为在此点之后的收益趋于平稳,而训练成本继续上升。
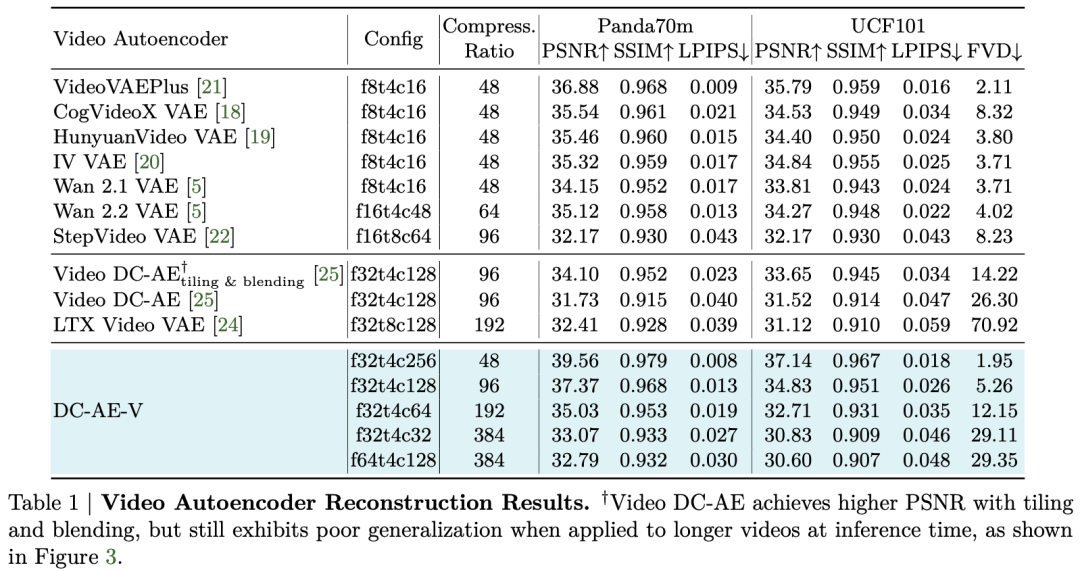
视频重建结果。 本文在下表1中总结了DC-AE-V与之前最先进的视频自动编码器的比较。与因果视频自动编码器(如LTX Video VAE [24])相比,DC-AE-V在相同压缩比下实现了更高的重建精度,并且在给定精度目标下实现了更高的压缩比。与非因果视频自动编码器(如Video DC-AE [25])相比,DC-AE-V在相同压缩比下提供了更好的重建质量,同时在推广到更长视频方面表现更佳(上图3)。
视频生成结果。 除了重建性能外,本文还评估了DC-AE-V在视频生成方面相对于之前自动编码器的表现。下表2展示了在Wan-2.1-1.3B [5]上的消融结果,显示DC-AE-V达到了最佳的视频生成性能。与基础模型相比,DC-AE-V-f64t4c128提供了22倍的加速,同时获得了略高的VBench分数。

后训练视频自动编码器适配
简单方法、挑战与分析
如前文所述,patch嵌入器和输出头本质上与隐空间表示紧密相关,因此在更换自动编码器时无法直接移植。因此,一种将预训练的视频扩散模型适配到新自动编码器的简单方法是保留预训练的DiT块,同时随机初始化patch嵌入器和输出头(上图7c,右)。这种策略在[25]中进行了探索,结果不尽如人意。
本文在本文的设置中评估了这种方法,观察到类似的结果。如下图6a(绿色虚线)所示,它未能达到基础模型的语义得分。此外,本文观察到训练不稳定性:模型的输出在20K训练步骤后退化为随机噪声(下图6b,顶部)。本文推测这种不稳定性源于新的隐空间和随机初始化的patch嵌入器引入的显著嵌入空间差距,这阻止了模型有效保留来自预训练DiT权重的知识。
本文的解决方案:AE-Adapt-V
为了解决这一挑战,本文在端到端微调之前引入了一个视频嵌入空间对齐阶段,以弥合嵌入空间之间的差距,并在适应新的隐空间的同时保留预训练模型的知识。
AE-Adapt-V 阶段1:视频嵌入空间对齐。 上图7b展示了本文视频嵌入空间对齐的一般概念,其中本文首先对齐patch嵌入器,然后对齐输出头。
对于patch嵌入器对齐,本文冻结基础模型的patch嵌入器,并训练一个新的patch嵌入器,将新隐空间映射到嵌入空间。目标是最小化基础模型的嵌入与新patch嵌入器生成的嵌入之间的距离。形式上,设基础模型的嵌入表示为,其形状为,新模型的嵌入表示为,其形状为,其中是嵌入通道维度,在本文的设置中,,。本文首先使用平均池化对进行空间下采样以匹配的形状,结果记为。然后随机初始化的patch嵌入器被训练以最小化以下损失函数: 通过对齐的patch嵌入器,输出头随后通过与patch嵌入器联合微调来对齐,使用扩散损失,同时保持DiT块冻结。这个过程在扩散损失收敛后停止,在本文的实验中最多需要4000步。
通过对齐的patch嵌入器,输出头随后通过与patch嵌入器联合微调来对齐,使用扩散损失,同时保持DiT块冻结。这个过程在扩散损失收敛后停止,在本文的实验中最多需要4000步。
上图7a展示了本文的视频嵌入空间对齐的视觉效果。使用对齐的patch嵌入器和输出头,本文可以在不更新DiT块的情况下,在新的隐空间中恢复基础模型的知识和语义。下图11提供了额外的消融研究,显示对齐patch嵌入器在视频嵌入空间对齐中起到了最关键的作用,而对齐输出头进一步提升了质量。

AE-Adapt-V 阶段2:使用LoRA进行端到端微调。 仅靠视频嵌入空间对齐无法完全匹配基础模型的质量。为缩小这一差距,本文执行端到端微调。由于阶段1提供了强大的初始化,本文在此阶段采用LoRA [51]微调。
下图8比较了LoRA微调与完全微调。本文发现LoRA不仅通过减少可训练参数降低了训练成本,还比完全微调获得了更高的VBench分数和更好的视觉质量。本文推测这是因为LoRA更好地保留了基础模型的知识。

DC-VideoGen 应用
DC-VideoGen可以应用于任何预训练的视频扩散模型。在本文的实验中,本文对两种代表性的视频生成任务进行了评估:文本到视频(T2V)和图像到视频(I2V)生成。本文使用预训练的Wan-2.1模型 [5]作为基础模型,并将生成的加速模型记为DC-VideoGen-Wan-2.1。
Wan-2.1-I2V模型通过将图像条件与隐空间变量连接来结合图像条件。由于Wan-2.1-VAE和DC-AE-V采用不同的时间建模设计(因果与块状因果),DC-VideoGen-Wan-2.1 I2V模型不能直接采用与前文相同的方法。为了解决这一问题,本文将给定的图像条件复制四次并附加空白帧以形成与视频形状匹配的块。然后本文用DC-AE-V对这些块进行编码,并将生成的特征与隐空间变量连接,随后可以以与Wan-2.1-I2V相同的方式进行处理。
实验
设置
实现细节。 本文使用PyTorch 2 [52]在16个NVIDIA H100 GPU上实现并训练所有模型。采用了三个预训练的视频扩散模型:Wan-2.1-T2V-1.3B、Wan-2.1-T2V-14B和Wan-2.1-I2V-14B,每个模型都从原始的Wan-2.1-VAE适配到本文的DC-AE-V。为了训练,本文使用Wan-2.1-T2V-14B收集了257K个合成视频,并将它们与从Pexels中选择的160K个高分辨率视频结合。详细的训练超参数在表8中提供。
效率测试平台。 本文在单个H100 GPU上使用TensorRT2对所有模型的推理延迟进行基准测试。为简化起见,本文专注于transformer主干,因为它构成了主要的效率瓶颈。
评估指标。 按照常规做法,本文使用VBench [53]评估文本到视频(T2V)扩散模型,并使用VBench 2.0 [54]评估图像到视频(I2V)扩散模型。此外,本文还提供了由本文的模型生成的视觉结果。
文本到视频生成
下表3在720×1280分辨率下比较了DC-VideoGen与领先的T2V扩散模型在VBench上的表现。本文遵循VBench团队提供的扩展提示集,并在相同分辨率下进行所有实验以确保公平的对比。

与基础的Wan-2.1模型相比,DC-VideoGen-Wan-2.1在效率显著提高的同时获得了更高的分数。例如,DC-VideoGen-Wan-2.1-14B将延迟减少了7.7倍,并将VBench分数从83.73提高到84.83。与其他T2V扩散模型相比,DC-VideoGen-Wan-2.1在获得最高VBench分数的同时也实现了最低的延迟。
图像到视频生成
下表4报告了本文在720×1280分辨率下的VBench I2V结果。与T2V的发现一致,DC-VideoGen-Wan-2.1-14B通过获得更高的VBench分数并将延迟减少7.6倍,优于基础的Wan-2.1-14B。ƒ

与其他I2V扩散模型相比,DC-VideoGen-Wan-2.1-14B提供了具有极高竞争力的结果,并且效率卓越,比MAGI-1快5.8倍,比HunyuanVideo-I2V快8.3倍。
结论
本文介绍了DC-VideoGen,这是一种后训练框架,通过结合深度压缩视频自动编码器和高效的适应策略来加速视频扩散模型。DC-VideoGen在推理速度上实现了高达14.8倍的提升,并大幅降低了训练成本,同时保持甚至提升了视频质量。这些发现表明,视频生成中的效率和保真度可以共同进步,使大规模视频合成在研究和实际应用中变得更加实用和可及。
参考文献
[1] DC-VideoGen: Efficient Video Generation with Deep Compression Video Autoencoder
技术交流社区免费开放
涉及 内容生成/理解(图像、视频、语音、文本、3D/4D等)、大模型、具身智能、自动驾驶、深度学习及传统视觉等多个不同方向。这个社群更加适合记录和积累,方便回溯和复盘。愿景是联结数十万AIGC开发者、研究者和爱好者,解决从理论到实战中遇到的具体问题。倡导深度讨论,确保每个提问都能得到认真对待。


技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!











