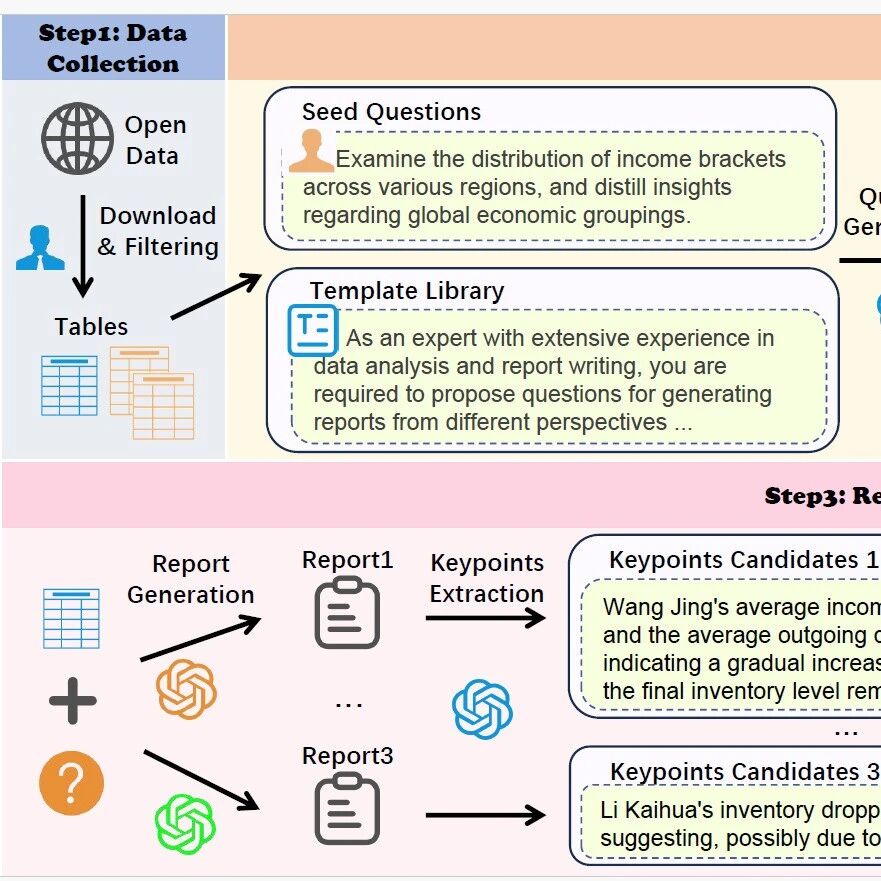
近日,来自 MetaGPT、蒙特利尔大学和 Mila 研究所、麦吉尔大学、耶鲁大学等机构的研究团队发布 CARE 框架,一个新颖的原生检索增强推理框架,教会 LLM 将推理过程中的上下文事实与模型自身的检索能力有机结合起来。该框架现已全面开源,包括训练数据集、训练代码、模型 checkpoints 和评估代码,为社区提供一套完整的、可复现工作。

项目主页:https://foundationagents.github.io/CARE
论文地址:https://arxiv.org/abs/2509.13683
开源代码:https://github.com/FoundationAgents/CARE
开源模型 & 数据集:
https://huggingface.co/collections/sheryc/care-datasets-emnlp-2025-68be35242afab58f4bed7d97
https://huggingface.co/collections/sheryc/care-checkpoints-emnlp-2025-68be35dbd732816c9d98f258
研究背景
从“外部搜索”到“原生检索”的转变
1、现有方法的困境
目前解决上下文保真度问题主要有两条路:1. 搭建复杂的 RAG 系统,依赖向量数据库、检索器等一整套基础设施;2. 让模型去调用搜索引擎,但这样反而忽略了用户已经提供的宝贵信息。这两种方法都把检索当作一个独立的外部过程,没有真正融入模型的思考流程。与此同时,目前的LLM有着较强的多任务能力,所以检索器和理解模型在长上下文阅读中或许可以被LLM所统一。
2、CARE:让检索成为推理的一部分
CARE 的突破在于提出了原生检索增强推理这一全新范式。简单来说,就是教会模型在推理过程中利用模型本身的能力自然地引用输入文本中的关键信息。就像学生在答题时会在试卷上划重点一样,模型会在思考过程中插入类似“根据文档第三段提到...”这样的引用,确保每一步推理都有据可依。
这种方法的优势显而易见:不需要额外的检索系统,不增加推理延迟,部署极其简单。对于使用 LLM 的项目来说,只需要替换模型权重就能获得显著的性能提升。
技术实现:两阶段训练策略
CARE 采用了精心设计的两阶段训练流程,确保模型既能学会检索-推理的格式,又能在各种场景下灵活运用。
第一阶段:让模型学会“引用”
研究团队首先基于 HotpotQA 数据集构建了训练数据。通过一个巧妙的数据生成流程,他们将原始的问答数据转换成包含明确引用的推理链。例如,当模型需要回答“约翰的妈妈买的电影票价格合理吗”时,它会先思考“需要从用户输入中抽取约翰的妈妈买票的价格”,再利用自身能力自回归地引用用户输入中出现的原文片段“票价是 15 美元”。之后,它再次思考“需要从用户输入中抽取普通票价”,再自回归地引用“普通场次票价范围是 10-12 美元”,最后得出结论。
这个阶段使用监督学习,让模型熟悉这种“先查找,再推理”的思考模式。关键是使用特殊标记来标识引用内容,让模型清楚地区分哪些是从原文提取的事实,哪些是自己的推理。
第二阶段:强化学习优化检索质量
然而,仅仅学会格式还不够,模型需要知道什么时候该检索,检索什么内容。第二阶段采用强化学习,通过三个精心设计的奖励信号来引导模型:
准确性奖励确保最终答案正确,格式奖励保证输出规范,研究团队在检索奖励上进行了创新:它鼓励模型检索的内容必须真实存在于原文中,不能凭空捏造。这个看似简单的约束,实际上极大地提升了模型的上下文忠实度。
在此基础上,为了让模型能够适应各种不同长度的输入输出,研究团队引入了课程学习策略,让模型从简单的短文本问答逐步过渡到复杂的多跳推理任务。这就像教小孩先学会在一页纸上找答案,再逐步学会在整本书中寻找线索。

评估效果
为了全面验证 CARE 框架的有效性,研究团队在真实世界和反事实(Counterfactual)两大类问答基准上进行了严谨的实验,并与多种主流方法进行了对比。实验结果清晰地表明,CARE 在模型上下文保真度和回答准确性方面取得了全面且显著的提升。
真实世界问答任务:全面超越现有方法
在涵盖了多领域、长文本、多跳推理等复杂场景的四大主流 QA 基准(MFQA, HotpotQA, 2WikiMQA, MuSiQue)上,CARE 表现出了压倒性的优势。
性能显著提升:实验数据显示,以 Llama-3.1-8B 模型为例,搭载了 CARE 框架后的模型平均 F1 分数提升了 15.29%。 这一提升在需要综合多个信息点进行推理的复杂多跳任务(如 2WikiMQA 和 MuSiQue)上尤为明显,涨幅分别达到了 29.42% 和 18.92%。
普适性强:无论是在 Llama 还是 Qwen 等不同架构和尺寸的模型上,CARE 都能带来一致的性能增益,证明了该框架的强大通用性。

反事实问答任务:真正做到“忠于原文”
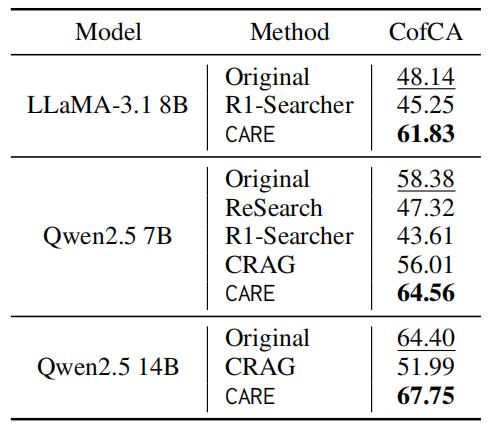
为了测试模型在面对与自身“知识”相悖的上下文时,是否能坚守原文信息,研究团队在 CofCA 基准上进行了测试。这被认为是检验模型上下文保真度的“试金石”。CofCA基准将测试中使用的长文档由维基百科替换为了真实世界中不存在的信息,利用反事实的上下文,测试模型在用户输入极度OOD时的幻觉表现。
上下文保真度大幅领先:CARE 能够在给定上下文与模型预训练知识冲突时,依然准确依据上下文作答,在 LLaMA-3.1 8B 上实现了 13.69% 的性能飞跃。
揭示外部搜索的弊端:相比之下,依赖外部搜索引擎的传统方法在这一任务上表现不佳,因为外部信息反而加剧了模型混淆,导致其忽略了眼前的“标准答案”。这凸显了 CARE 原生检索范式的关键优势:优先并忠实于用户提供的即时信息。
事实检索能力评估:答得对,更找得准
CARE 的成功不仅体现在最终答案的准确性上。通过在 HotpotQA 基准上对模型检索出的事实进行直接评估,研究团队发现:
检索质量更高:与其他方法相比,CARE 在定位和提取关键支撑事实方面的能力更强,其检索内容的 BLEU 和 ROUGE-L 分数均达到最高。 这证明了 CARE 真正学会了如何在推理过程中精准地“引用”原文,为最终答案的可靠性提供了坚实的基础。

综合来看,CARE 框架通过其创新的原生检索增强推理机制,不仅在各项评估中取得了 SOTA 级别的性能,更重要的是,它为解决大型语言模型在实际应用中的“幻觉”和“上下文遗忘”问题,提供了一条高效、低成本且易于部署的全新路径。
总结
针对 LLM 在上下文中容易丢失事实信息的固有问题,虽然已有借助 RAG 流程或调用检索引擎进行改进的方式,但使得整体流程更长,耗时更久。CARE 则通过一种结合课程学习策略 + RL 的方法来提升 LLM 自身检索能力,让模型更多关注到上下文中的事实信息并进一步回答的更准确。这种使用原生检索增强推理的范式降低了使用者的对接成本,具备更灵活的落地应用性。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com