
一、为什么自动对接这么重要?
在移动机器人(Mobile Robot)的长期应用中,“自动对接(Automatic Docking)”是一个看似小但至关重要的环节。
无论是:
仓储物流中的AGV(自动导引车),需要在完成搬运任务后返回充电站;
农业场景中的田间机器人,需要定时回桩进行能量补给和数据上传;
家庭服务机器人(如扫地机、送餐机器人),必须能自动找到并精准对接充电底座;
如果没有可靠的自动对接,机器人就无法实现真正的“长时间无人值守”。
然而,这一过程在实际中面临巨大挑战:
1. 高精度要求:
对接并非简单的靠近,而是要达到厘米级的位置误差、几度以内的姿态误差。稍有偏差,充电触点无法接合,甚至会损坏接口。
2. 路径与控制难题:
如果轨迹不平滑,机器人在接近时可能出现急转弯或震动,导致“擦边”“卡壳”甚至碰撞障碍物。
3. 环境复杂性:
在室内,可能遇到光照变化、家具遮挡等问题;
在户外,更复杂:地面不平、草地、坡度、天气变化、GPS漂移都会让定位发生误差。
特别是长时间任务后,机器人的累计定位误差会导致它回到对接点时偏离既定轨迹。
正因为如此,自动对接的成功率与鲁棒性几乎决定了机器人能否真正走向大规模应用。
换句话说,它是机器人产业落地过程中的“临门一脚”:算法、硬件再强,如果机器人无法稳定回桩充电,它依旧无法在现实场景中连续运行。
二、RGB-D视觉的潜力
为了实现自动对接,研究者们尝试了多种传感器:
红外(Infrared):可以识别特定反射信号,但在强光下易受干扰;
超声波(Ultrasonic):测距简单,但精度有限,且容易受到环境噪声影响;
激光雷达(LiDAR):精度高,但成本昂贵,对小目标或透明材质的检测能力有限。
这些方法有两个共同局限:
1. 只提供几何信息(距离、方向),但缺乏“环境语义”。它们能告诉机器人“前方 20 厘米有个物体”,却无法判断“这是充电底座”还是“一张椅子”。
2. 依赖外部标记或专用硬件。例如在底座上加反光板、灯条、二维码等,这虽然能提高识别率,但灵活性不足,一旦场景变化或标志损坏,对接就会失败。
相比之下,视觉(Camera) 成为更具潜力的选择:
低成本 & 易部署:一台RGB-D相机即可,同时捕捉彩色信息与深度数据。
环境上下文感知:不仅能识别基站,还能理解周围障碍物的形状、纹理与位置。
双模态互补:
RGB 提供外观和语义(识别这是基站,而不是其他物体);
Depth 提供几何与空间结构(基站距离、角度、相对高度)。
这意味着:
理论上,RGB-D视觉让机器人可以“像人一样靠眼睛回家”,只凭环境感知就能完成精准对接。
关键问题在于:如何把视觉输入转化为一条可行、平滑、精确的轨迹?
传统方法往往采用“感知 → 姿态估计 → 轨迹规划 → 控制”四步走,但每一步都会带来误差积累,而且对机器人的初始位置要求非常严格。
于是,自然而然地就引出了本文的核心问题:
能否用端到端的学习方法,让机器人仅凭RGB-D输入,直接输出对接轨迹?
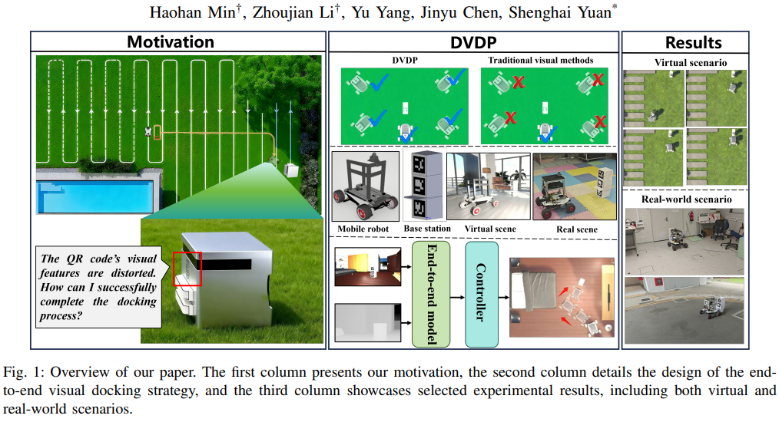
三、DVDP:一次创新的尝试
现有的视觉自动对接方法大多采用 感知–规划–控制(Perception–Planning–Control) 的分阶段流程:
1. 感知:识别基站上的特征点(如二维码、灯条、反光板等),进行位姿估计;
2. 规划:在估计的坐标系下生成运动轨迹;
3. 控制:将轨迹转化为低层速度指令,驱动机器人移动。
这种方法的问题在于:
误差积累:感知环节如果识别不准,后续规划和控制都会放大偏差;
初始条件敏感:机器人必须处于较小的误差范围内,否则很容易出现“轨迹偏离”“姿态对不上”的失败情况;
鲁棒性不足:在户外或光照复杂环境下,特征容易被遮挡或扭曲。
为了解决这些问题,研究团队提出了 Direct Visual Docking Policy (DVDP),其创新点主要体现在三个方面:
1. 端到端直接映射:跳过传统的分阶段流程,从输入到输出不再经过复杂的中间环节,而是直接由深度神经网络学习 RGB-D输入 → 对接轨迹输出 的函数映射。
2. 消除手工特征依赖:不再依赖人工设计的特征点或标记物,避免了“特征消失/失真”带来的系统性风险。
3. 适应任意初始位置:通过在训练中引入多样化的初始状态,DVDP 能够在机器人从任意角度、任意偏移量开始对接时,依旧生成平滑、可行的路径。这一特性解决了传统方法“必须从预设轨迹起点进入”的痛点。
换句话说,DVDP 就像给机器人装上了一双“懂得回家”的眼睛和大脑:它看到环境后,能够自主规划一条合理的路径,并且确保姿态正确、轨迹可行。
四、DVDP 如何工作?
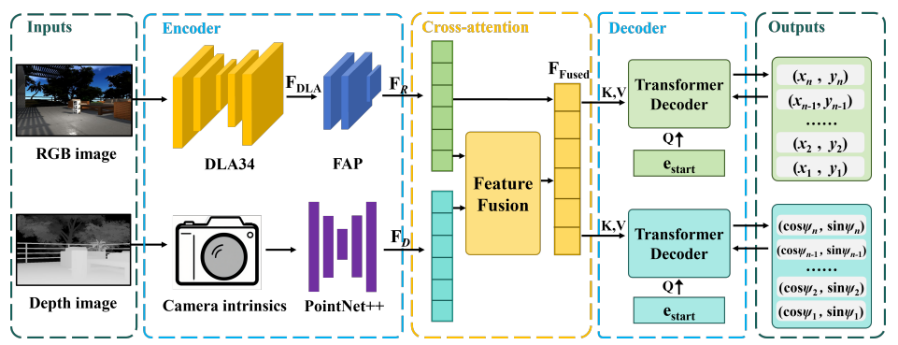
DVDP 的网络架构体现了“多模态感知 + 序列预测”的设计思路,具体分为四个核心环节:
1. 双流编码器 (Dual Encoder)
RGB流(外观与语义):采用 DLA-34 (Deep Layer Aggregation) 作为骨干网络。DLA 的优势在于层间特征的多尺度聚合,能够在保持细节的同时捕捉全局上下文。配合 FAP(Feature Aggregation Pipeline) 与 Pyramid Pooling Module (PPM),RGB流不仅识别基站,还能感知周围障碍物和全局场景布局。
Depth流(几何与结构):使用 PointNet++ 对深度图进行点云化处理,并引入 不确定性传播机制,考虑深度传感器噪声对点云坐标的影响。这使得网络学到的几何信息更加稳健,能在现实场景中处理光照不足或红外干扰。
2. 跨模态注意力 (Cross-Attention)
RGB 与 Depth 特征在模态上是互补的:
RGB 提供“看到的是什么”(基站的语义和纹理信息);
Depth 提供“物体在空间里怎么摆放”(基站的精确位置与几何形状)。
通过跨模态注意力机制,DVDP 让深度特征作为 Query 去选择性关注 RGB 特征中的相关部分,从而获得 兼具语义与几何约束的融合特征。相比简单拼接或加权,这种交互能显著提高对复杂环境的理解能力。
3. 双解码器 (Trajectory + Orientation)
DVDP 的输出不仅是“去哪儿”,还包括“怎么去”:
轨迹解码器:输出连续二维坐标点 (xt,yt)(x_t, y_t)(xt,yt),形成完整的行进路径;
方向解码器:输出对应的方向向量 (cosψt,sinψt)(\cos\psi_t, \sin\psi_t)(cosψt,sinψt),避免角度周期性问题,保证在对接过程中机器人始终保持正确的朝向。
关键设计:采用 自回归解码(Autoregressive Decoder),即每一步预测依赖前一步的结果。这样输出的轨迹具备时间因果性,更符合物理运动规律,也避免了并行预测可能带来的“轨迹不连续”问题。
4. 训练方式
研究团队构建了一个 混合场景大规模数据集:
虚拟数据(约 1 万条):基于 Unity 3D + ROS2,覆盖卧室、客厅、阳台、庭院等多种场景。利用规则算法生成对接路径,并通过 Domain Randomization(随机光照、材质、传感器噪声)增强模型鲁棒性。
真实数据(约 1200 条):使用配备 Intel RealSense D455 相机与 LiDAR 的 SCOUT Mini 平台采集,涵盖实验室、走廊、室外地面等真实场景。
这种 “虚拟先学,再迁移到真实” 的训练范式,使模型能在有限的真实数据下保持良好性能。
五、实验效果如何?
为了全面验证 DVDP 的有效性,研究团队设计了 对比实验、消融实验和真实机器人部署实验。实验覆盖虚拟环境与真实场景,结合多维度的评估指标,结果相当有说服力。
1. 对比实验:和现有方法的较量
研究团队选择了多种代表性方法作为基线,包括:
CenterPose(单模态,RGB输入,基于关键点的姿态估计);
AnyGrasp(单模态,深度输入,鲁棒抓取感知);
PVN3D(多模态,结合点云与图像,常用于6D姿态估计);
Hoang et al. 方法(典型的视觉位姿估计与融合方法)。
这些方法本身并非为对接任务而设计,因此研究者将其 感知编码器嵌入 DVDP 框架,保持相同的解码器,统一比较不同感知骨干的效果。
结果:DVDP 全面领先
成功率(SR):73.2%,显著高于其它方法(最高仅 53.3%);
L2 轨迹误差:DVDP 为 0.044 m,相比 CenterPose 的 0.070 m 和 AnyGrasp 的 0.067 m,误差减少约 30-40%;
姿态误差(AER):DVDP 仅 4.6°,而 AnyGrasp 高达 7.3°。
原因分析:
DVDP 的“分层特征聚合(DLA)+ 上下文增强(PPM+FAP)+ 跨模态融合(Cross-Attention)”形成了完整的 层级–上下文–模态互补 表征机制。相比之下,CenterPose 和 AnyGrasp 的单模态输入严重受限,PVN3D 和 Hoang 等方法虽是多模态,但骨干网络无法充分聚合层间特征,导致表现逊色。
2. 消融实验:关键模块的重要性

为了验证 DVDP 架构中各部分的作用,研究团队做了消融实验:
去掉跨模态注意力(w/o CrossAtt) → 成功率骤降至 35.6%,几乎腰斩。说明简单拼接RGB与Depth特征不足以完成有效融合,Cross-Attention 的动态交互机制是性能提升的关键。
去掉自回归解码器(w/o Decoder) → 成功率降低至 66.8%,并且轨迹出现明显的不连续性。并行解码虽然加快预测,但失去了时间因果性建模,导致轨迹不平滑甚至不物理可行。
这证明了 DVDP 的两个核心设计——跨模态注意力 + 自回归解码——都不可或缺,它们共同保障了对接轨迹的准确性与物理合理性。
3. 真实机器人部署:从仿真到现实
实验最后在 SCOUT Mini 平台上进行真实部署,机器人配备了 Intel RealSense D455 RGB-D 相机 和 MID360 LiDAR。
实验环境:实验室走廊、开放场地、真实办公区域;
结果:机器人在真实场景中能够 平滑且准确地完成自动对接,轨迹可行,姿态对齐,验证了模型的现实可用性。
更重要的是,DVDP 能够在初始位置偏差较大、光照变化、甚至部分视觉特征失真的情况下依旧完成任务,这显示了其强大的鲁棒性和泛化能力。
六、这项工作的意义
为什么这篇论文值得关注?我认为它的意义可以从四个层面来理解:
1. 范式转变:端到端取代传统管道
从“感知 → 规划 → 控制”多阶段管道 → 转变为 端到端直接预测轨迹。
消除了中间环节的误差累积问题,让机器人能够直接学习从视觉输入到行动输出的映射。
类似于从“翻译时先做语法解析”到“直接神经机器翻译”的跨越。
2. 鲁棒性提升:适应任意初始状态
传统方法要求机器人从特定的“预设位置”进入对接路径,否则容易失败。
DVDP 则能在偏差较大的初始状态下重新生成平滑轨迹,完成对接。
这对于长时间运行、定位漂移、GPS误差频繁的户外环境尤为关键。
3. 资源贡献:数据集与指标体系
研究团队构建了一个 大规模混合场景数据集(虚拟+真实,室内+室外),涵盖多种光照、纹理、起始位置。
定义了一整套 评估指标(轨迹误差、姿态误差、最终对接误差、成功率等),为后续研究提供了基准。
这不仅是方法创新,也为学界和产业界搭建了实验平台。
4. 应用前景:落地价值显著
物流领域:AGV/AMR 在仓库中自动回充,减少人工干预;
农业领域:田间机器人在非结构化环境中自主回桩,提高作业连续性;
家庭服务:扫地机器人、配送机器人等的充电对接更加鲁棒,不再“对不准充电桩”。
一句话总结:
DVDP 让“机器人看见就能回家”,首次证明了RGB-D感知结合端到端学习能够真正解决自动对接这一“临门一脚”的难题。
七、局限与未来展望
尽管 DVDP 在视觉自动对接领域迈出了重要一步,但论文也坦诚地指出,这项工作仍存在一些局限性和挑战:
1. 数据量不足
真实数据有限:目前的数据集中,真实场景仅 1200 个样本,训练主要依赖虚拟仿真生成的大规模数据。虽然通过 Domain Randomization 缓解了虚实差距,但在高复杂度的实际环境中,模型可能出现性能下降。
覆盖范围不足:真实数据大多集中在实验室和室外地面,尚未涵盖雨天、夜间、强光、半户外/半室内等多样化工况。
2. 成功率仍未达到工业级
DVDP 在测试中的 成功率为 73.2%,在学术研究中已经显著超越基线方法,但在工业应用中仍不足够。
例如:仓储机器人若每 4 次对接就失败一次,会严重影响生产线的连续性。因此,如何将成功率提升至 95%+ 甚至 99%+,仍是未来研究必须解决的瓶颈。
3. 复杂环境适应性未知
环境挑战:雨水会干扰深度相机,强光会导致 RGB 图像过曝,灰尘或遮挡可能破坏特征识别。
动态场景:目前 DVDP 假设环境相对静态,但若在对接过程中出现动态障碍(行人、其他机器人),模型能否保持鲁棒性仍待验证。
4. 算法与架构限制
当前采用的自回归解码虽然提升了轨迹连续性,但带来了 推理速度较慢 的问题。若要应用于实时对接,解码效率可能成为瓶颈。
DVDP 完全依赖监督学习,缺乏“自适应”能力。一旦环境分布与训练数据差异过大,性能可能迅速退化。
未来展望
研究团队在论文中也提出了一些未来的探索方向:
1. 扩展真实场景数据
在更多环境中采集大规模真实数据,尤其是 非结构化户外环境(农田、工地、停车场)。
引入 自动数据采集和标注工具,减少人工成本。
2. 结合强化学习或模仿学习
在端到端架构的基础上,融合 强化学习(RL) 或 模仿学习(IL),让模型在真实环境中通过试错不断优化轨迹。
这能解决“分布外场景”下的适应性问题,使 DVDP 不再依赖一次性训练完成。
3. 多传感器融合
将 LiDAR + RGB-D + IMU 数据融合,提升鲁棒性。
视觉提供语义信息,LiDAR 提供高精度测距,IMU 提供运动约束,多源数据可以互补弱点,确保在极端工况下仍能稳定对接。
4. 跨平台与跨任务泛化
当前实验仅在 SCOUT Mini 平台上验证,未来应测试在不同尺寸、不同结构的机器人上。
甚至可以扩展到 无人机对接、无人船回港、工业机械臂插接 等更广泛的场景。
5. 优化推理效率
通过模型压缩、轻量化 Transformer 或边缘计算优化,加快对接轨迹的生成速度,使其真正满足工业部署的实时性要求。
八、总结
回到最初提出的问题:RGB-D视觉能否让机器人自动精准对接?
通过这篇论文的研究,我们可以明确地回答:
可以,而且已经有了切实可行的解决方案。
核心贡献:
DVDP 证明了 端到端学习 可以替代传统的“感知–规划–控制”管道。
机器人不再需要依赖人工设计的特征或规则,而是能够 直接从视觉输入学会生成对接轨迹。
在实验中,DVDP 已经展现出比现有方法更高的精度、更强的鲁棒性和更好的泛化能力。
现实意义:
在仓储物流、农业无人化、家庭服务机器人等领域,DVDP 为机器人“自主回桩充电”提供了关键技术突破。
这意味着未来机器人能够实现更长时间的连续运行,真正朝着“零人工干预”的方向发展。
长远展望:
尽管当前的成功率和真实场景覆盖仍有限,但这一研究方向为后续的 跨模态感知、强化学习结合、多传感器融合 打下了坚实基础。
可以预见,随着数据规模扩大、算法优化和硬件进步,基于 RGB-D 的端到端对接策略有望在未来几年内走向工业落地。
一句话总结:
DVDP 让机器人“看见就能回家”,这是视觉对接领域从理论走向实践的关键一步,也是机器人产业规模化应用的重要里程碑。

扫描下方二维码一起来学习吧!












