
> 本文由 Intern-S1 等 AI 生成,机智流编辑部校对
经常关注我们的朋友知道,昨天我们发布了一份 ICLR-2026 论文洞察报告。报告分析了当前机器学习领域的,以及。
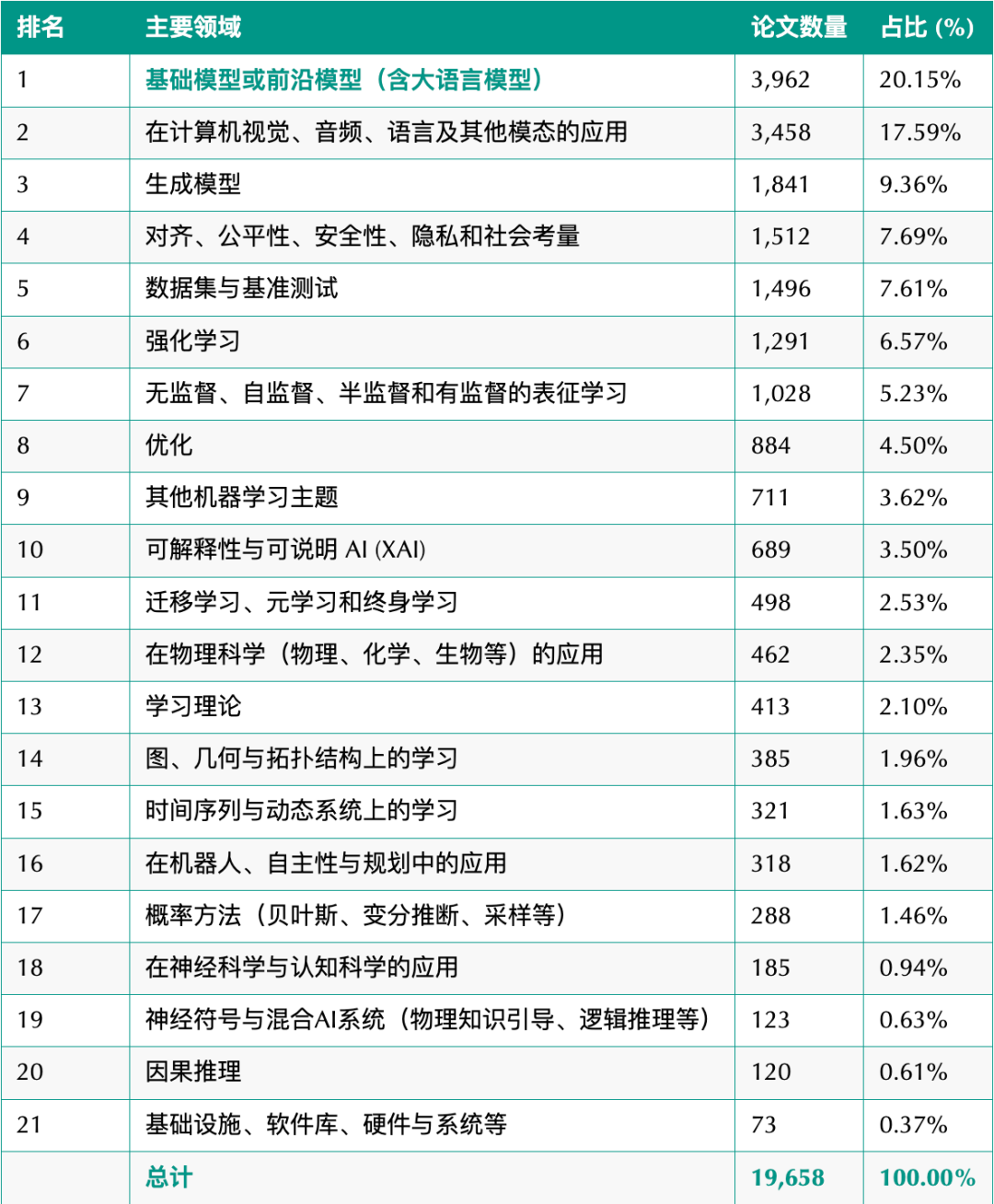
然而在这 19658 篇论文中,突然有一篇论文在圈内火了。那就是计算机视觉领域神作“Segment Anything”系列的新工作——《SAM 3: Segment Anything with Concepts》(“基于概念分割一切”)。
今天我们带大家来回顾一下 SAM 系列的前世今生,以及 SAM3 究竟有哪些变化,又有哪些令人瞩目的技术创新点。

引言
想象一位机器人工程师置身于喧嚣的果园,任务是快速识别并分割所有“红色苹果”。
过去的工具或许能精准勾勒出一颗苹果的轮廓,但若要求它主动找到每一颗符合描述的苹果(如“带有黄色斑纹的苹果”),却显得力不从心。这正是视觉AI领域长期面临的挑战:从被动响应用户指令,到主动理解抽象概念,分割所有匹配的物体。Meta AI的Segment Anything(SAM)系列模型,恰如一位视觉探险家,经历了从SAM 1的初探,到SAM 2的动态追踪,再到如今SAM 3的“概念觉醒”。
注:SAM 3这篇论文仍处于盲审中,但 Meta 作为 SAM 系列的开山鼻祖,推出续作 SAM3 合情合理
SAM 3不仅继承了前辈的分割能力,还通过引入Promptable Concept Segmentation(PCS,概念提示分割)任务,开辟了全新的可能性:用户只需提供简单的名词短语(如“黄色校车”)或图像范例,模型便能检测、分割并跟踪所有匹配的物体实例。
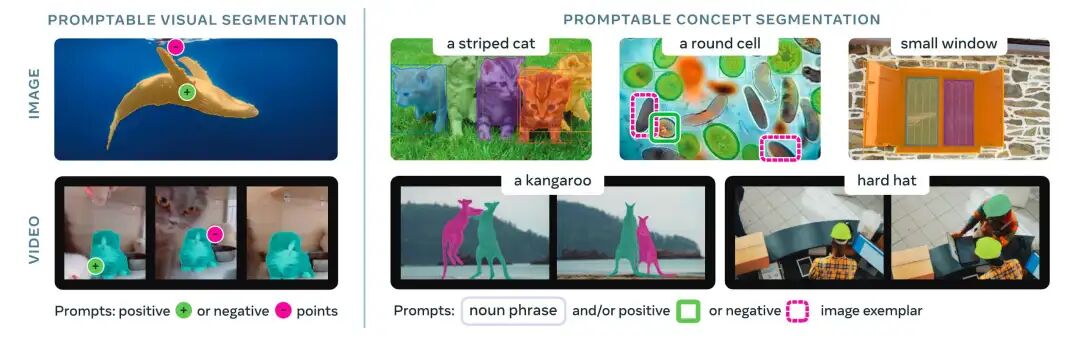
图 1:SAM 3在Promptable Visual Segmentation(左)和Promptable Concept Segmentation(右)任务上的表现,展示其通过点击或名词短语分割所有匹配实例的能力。
SAM系列的征途起点
SAM系列的故事始于2023年,Meta AI推出了SAM 1[1],首次定义了Promptable Visual Segmentation(PVS,视觉提示分割)任务。SAM 1如同一把精准的画笔,用户通过点击、框选或提供掩码,就能让模型分割出图像中的单一物体。这项突破让数据标注、内容创作和机器人导航等应用场景焕然一新。然而,SAM 1的局限也很明显:它依赖用户明确的视觉提示,只能处理单一物体,无法应对“找出所有猫”这样的全局需求。
2024年,SAM 2[2]登场,像是探险家获得了追踪时间的能力。它扩展到视频分割,允许用户通过提示跟踪动态场景中的单一物体,并在交互中精炼结果。SAM 2在视频处理上表现出色,但在面对抽象概念或多实例分割时,仍然显得捉襟见肘。无论是SAM 1还是SAM 2,它们都像是忠实的执行者,等待用户的精确指令,却无法主动理解“概念”的含义。这种局限,为SAM 3的登场埋下了伏笔。
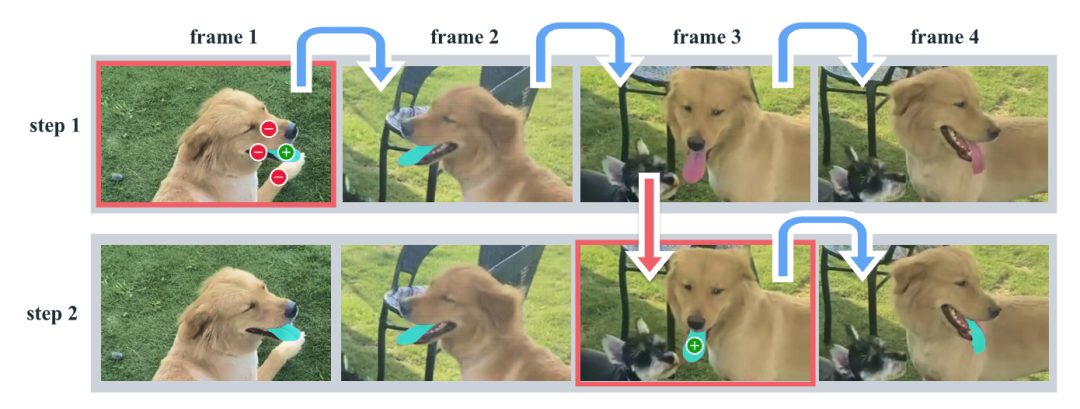
图 2:基于 SAM2 对视频中某一对象的分割示例。展示了 SAM 2 通过 “选择(第 1 帧用正负提示获舌头分割并自动传播,丢失目标可加提示修正)- 优化(第 3 帧单击 1 次恢复目标并获正确掩码)” 两步流程分割舌头,且因具备记忆功能,相比需在第 3 帧多次点击重新标注的“分离 SAM + 视频跟踪器”方法更高效。
SAM 3的“概念觉醒”
SAM 3的发布,标志着视觉AI从“工具”到“智能代理”的飞跃。它引入了Promptable Concept Segmentation(PCS)任务,允许用户通过简单的名词短语(如“红色苹果”或“条纹猫”)或图像范例,甚至两者结合,指定一个视觉概念,模型便能自动检测、分割并跟踪所有匹配的物体实例。
无论是静态图像还是短视频(≤30秒),SAM 3都能生成精确的实例掩码、语义掩码,并保持视频中物体的身份一致性。这种能力让SAM 3在机器人、增强现实和科学分析等领域展现出巨大潜力。
SAM 3的架构设计是其成功的关键。它采用双编码器-解码器Transformer结构,分为检测器和跟踪器,共享一个视觉-语言对齐的Perception Encoder(PE)骨干。

图 3:SAM3 架构概览
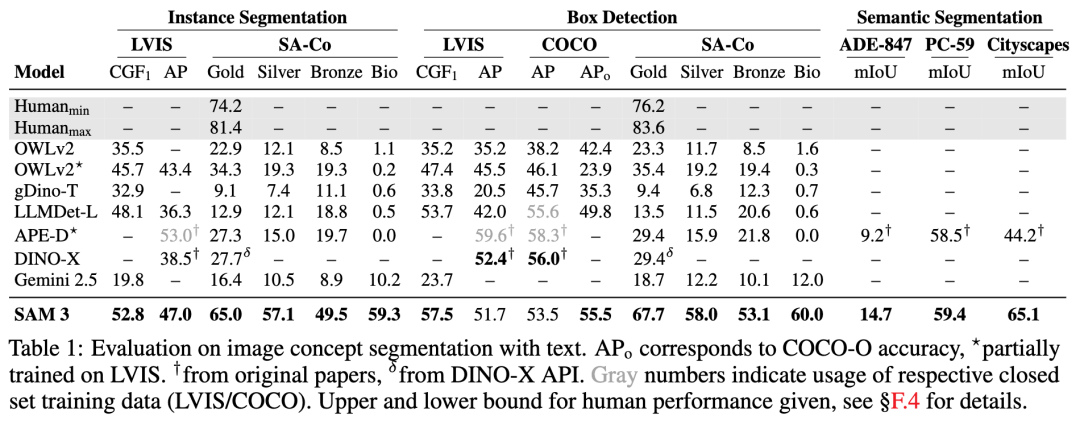
检测器基于DETR(检测Transformer)范式,通过融合图像和文本提示,生成物体提案。特别值得一提的是,SAM 3引入了一个创新的“Presence Token”,将物体的识别(“是什么”)与定位(“在哪里”)解耦。Presence Token负责判断目标概念是否出现在图像中,而提案查询则专注于精确定位。这种解耦设计显著提升了开放词汇检测的准确性,尤其是在处理“硬负例”(如容易混淆的“mouse”指动物还是设备)时,表现尤为出色。实验表明,SAM 3在图像和视频PCS任务中的性能是现有系统的两倍,在LVIS数据集上零样本掩码平均精度(AP)达到47.0,远超之前的38.5。
跟踪器则继承了SAM 2的内存机制,通过单帧传播和时序去歧策略(如掩码检测分数和定期重新提示),解决视频中遮挡和拥挤场景的挑战。此外,SAM 3支持交互式精炼,用户可以通过正/负图像范例或点击调整结果,化解概念模糊性。例如,“小窗户”可能因主观性引发歧义,用户可通过提供范例框选,引导模型聚焦预期目标。
SAM 3的另一大亮点是与多模态大语言模型(MLLM)的结合,形成了SAM 3 Agent。通过一系列工具(如segmentPhrase、examine_each_mask等),它能处理复杂的语言查询,例如“保护你免受雨淋的黑色物体”。MLLM负责解析复杂描述,转化为SAM 3能处理的简单名词短语,再通过迭代精炼生成最终掩码。这种协作让SAM 3 Agent在ReasonSeg和RefCOCOg等数据集上实现了零样本最优性能,展现了强大的推理能力。
数据引擎的“炼金术”
SAM 3的卓越性能,离不开其背后精心设计的“数据炼金术”——一个由人类与AI协同驱动的数据引擎。这台引擎通过四阶段的迭代进化,生成了前所未有的高质量训练数据,涵盖52M个掩码和4M个独特名词短语,远超传统数据集的规模与多样性。它的创新不仅体现在技术架构,还在于媒体采集、标签生成和验证优化的突破,让SAM 3得以应对开放词汇的复杂挑战。
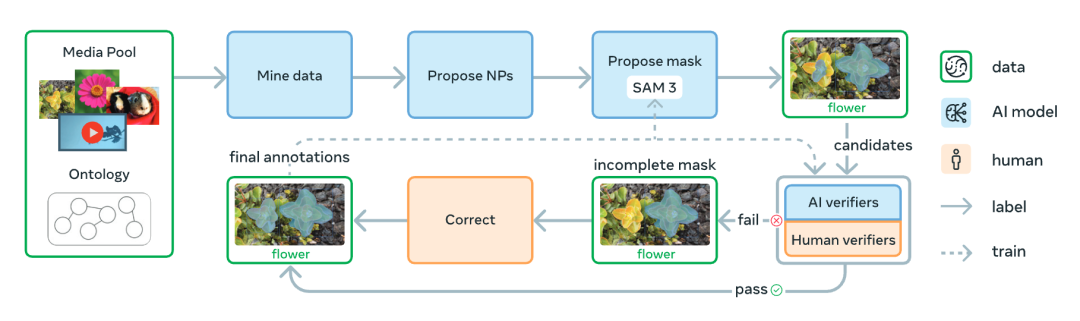
图 4:SAM3 数据引擎概览。图中“NP”指名词短语。
引擎的核心创新首先体现在媒体采集的多样性上。传统方法往往依赖单一的网络来源,导致视觉场景单一,难以适应真实世界的复杂性。SAM 3的数据引擎打破这一局限,主动挖掘15个不同领域的视觉数据,覆盖从日常场景到医学影像、工业环境等多样化域。这种广泛的覆盖确保模型能够理解从“黄色校车”到“显微镜下的细胞”各种概念,极大地提升了泛化能力。
其次,标签生成环节引入了基于 2240 万个节点的 SA-Co(Segment Anything with Concepts)本体的智能设计。传统的标签生成依赖人工定义或简单爬取,概念覆盖有限且缺乏挑战性。SAM 3的引擎利用多模态大语言模型(MLLM)作为“AI标注者”,生成丰富的名词短语,并通过本体结构主动构造“硬负例”,如区分“老鼠”(动物)与“鼠标”(设备)。这些对抗性标签迫使模型学习更细粒度的概念边界,显著提升其在模糊场景下的表现。
验证优化是另一大亮点。数据引擎通过微调Llama 3.2,开发出高效的AI验证器,用于检查掩码质量(Mask Verification)和完整性(Exhaustivity Verification)。这些AI验证器接近人类性能,将标注吞吐量提升一倍以上,使人类标注者能够聚焦于修正复杂错误案例,而非重复简单任务。这种人机协作模式极大地提高了数据生成效率。
第一阶段:奠基的人类验证
在数据引擎的起点,所有验证工作由人类完成。引擎从随机采样的图像开始,使用简单的图像描述模型和解析器生成名词短语,初始掩码则由SAM 2结合开放词汇检测器生成。这一阶段生成了包含4.3M个图像-短语对的SA-Co/HQ数据集,为SAM 3的初步训练奠定了基础。尽管效率有限,但这一阶段为后续AI辅助奠定了标注标准。
第二阶段:人机协同的效率飞跃
进入第二阶段,引擎引入AI验证器,利用第一阶段的人类标注数据微调Llama 3.2,使其能够自动执行掩码和完整性验证任务。这将人类的工作重点转向复杂错误修正,显著提升效率。引擎还升级了短语生成管道,加入基于Llama的硬负例生成,新增122M个图像-短语对。SAM 3在此阶段经历了6次迭代训练,AI验证器与模型性能同步提升,数据吞吐量翻倍。
第三阶段:规模与领域的双重扩展
第三阶段进一步放大了引擎的野心。引擎利用AI模型挖掘更具挑战性的案例,并将SA-Co/HQ扩展到15个数据集,覆盖长尾和细粒度概念,如从图像的alt-text中提取特定短语,或通过Wikidata的本体挖掘概念。这一阶段新增19.5M个图像-短语对,AI验证器在跨域场景中展现出零样本能力,仅需少量领域特定监督即可优化完整性验证。SAM 3和AI验证器分别迭代7次和3次,数据质量和模型性能持续跃升。
第四阶段:征服视频的挑战
最后,引擎将触角伸向视频,生成52.5K个视频和467K个掩码的SA-Co/VIDEO数据集。引擎针对视频特有的挑战(如拥挤场景和跟踪失败)优化数据采集,应用场景/运动过滤和目标搜索,优先选择高难度片段。视频帧通过随机或对象密度采样,进入第三阶段的图像标注流程,再由SAM 3生成掩码并进行去重和优化。这一阶段确保SAM 3在动态场景中同样游刃有余。 通过这四阶段的递进,SAM 3的数据引擎不仅创造了规模空前的训练数据,还通过多样化媒体、智能化标签和高效验证,赋予模型应对开放词汇和复杂场景的能力。最终,引擎产出的SA-Co基准,包含214K个独特概念和3M个媒体-短语对,成为评估开放词汇分割的“金标准”,为视觉AI的未来研究铺平道路。
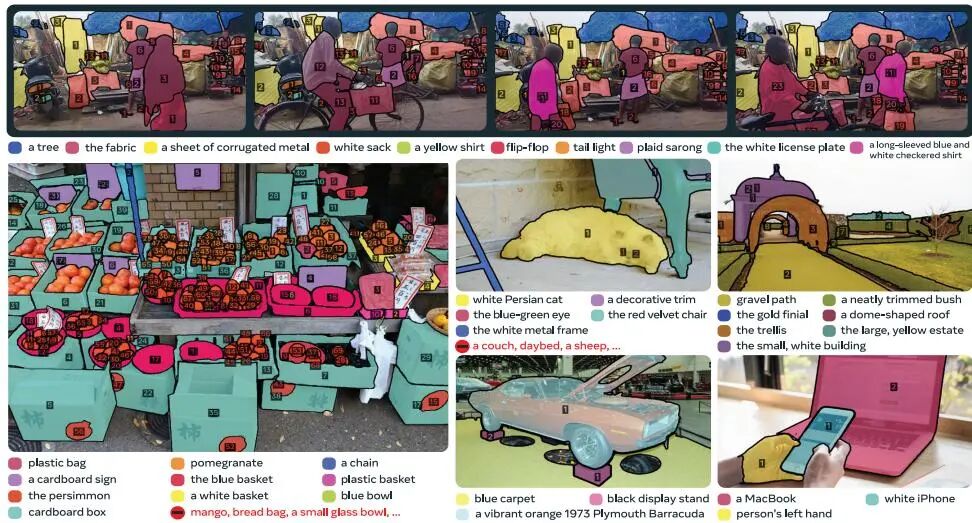
图 5:SA-Co数据集示例,展示视频(上)和图像(下)中的名词短语和实例掩码/身份标注,凸显其多样性和开放性。
SAM3 和前代的性能比较
SAM 3的出现,不仅是对SAM 1和SAM 2的继承,更是一场技术上的超越。SAM 1专注于静态图像的单一物体分割,依赖点、框或掩码提示,适合数据标注等基础任务,但无法处理多实例或抽象概念。SAM 2扩展到视频,引入了动态跟踪和交互精炼,但仍局限于单一物体,无法主动搜索所有匹配实例。SAM 3则通过PCS任务打破这些限制,支持文本和图像范例提示,检测所有匹配概念的实例,并在视频中保持身份一致性。
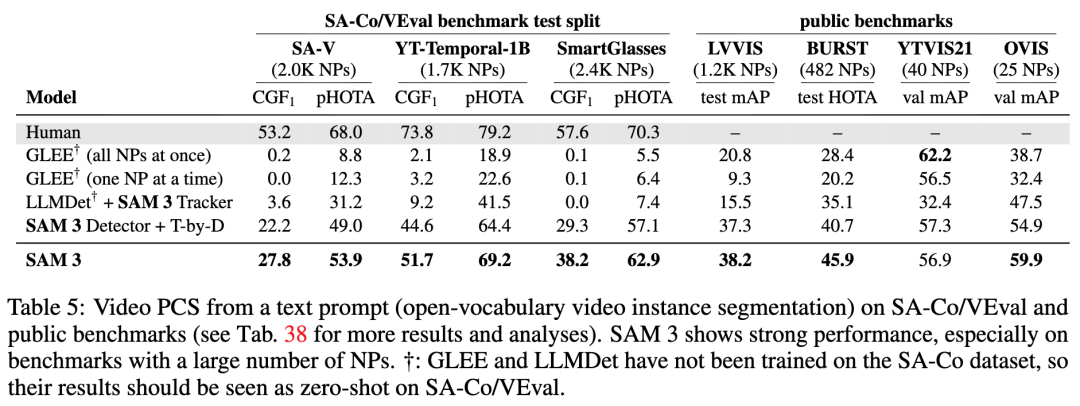
在性能上,SAM 3展现出压倒性优势。在LVIS数据集上,SAM 3的零样本掩码AP达到47.0,远超此前最佳的38.5;在SA-Co/Gold基准上,SAM 3的CGF1得分是OWLv2*的两倍,达到人类性能下限的88%。在视频PCS任务中,SAM 3在SA-Co/VEval上超越GLEE等基线,pHOTA指标接近人类水平的80%。此外,SAM 3在推理速度上表现出色,在H200 GPU上单图像处理仅需30ms,即使视频中跟踪5个物体也能保持近实时性能。
SAM 3 Agent的引入进一步拓展了应用边界。通过与MLLM协作,它能处理复杂推理查询,例如在ReasonSeg数据集上实现零样本最优性能,gIoU达73.8(Gemini2.5 Pro版本)。
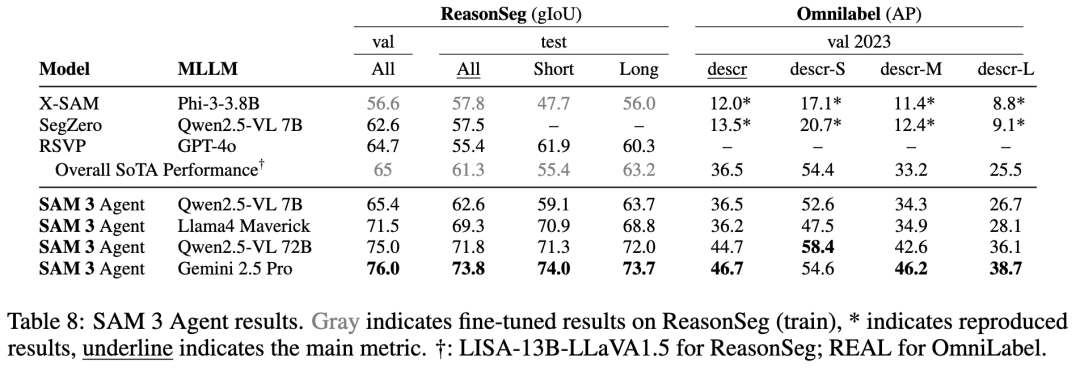
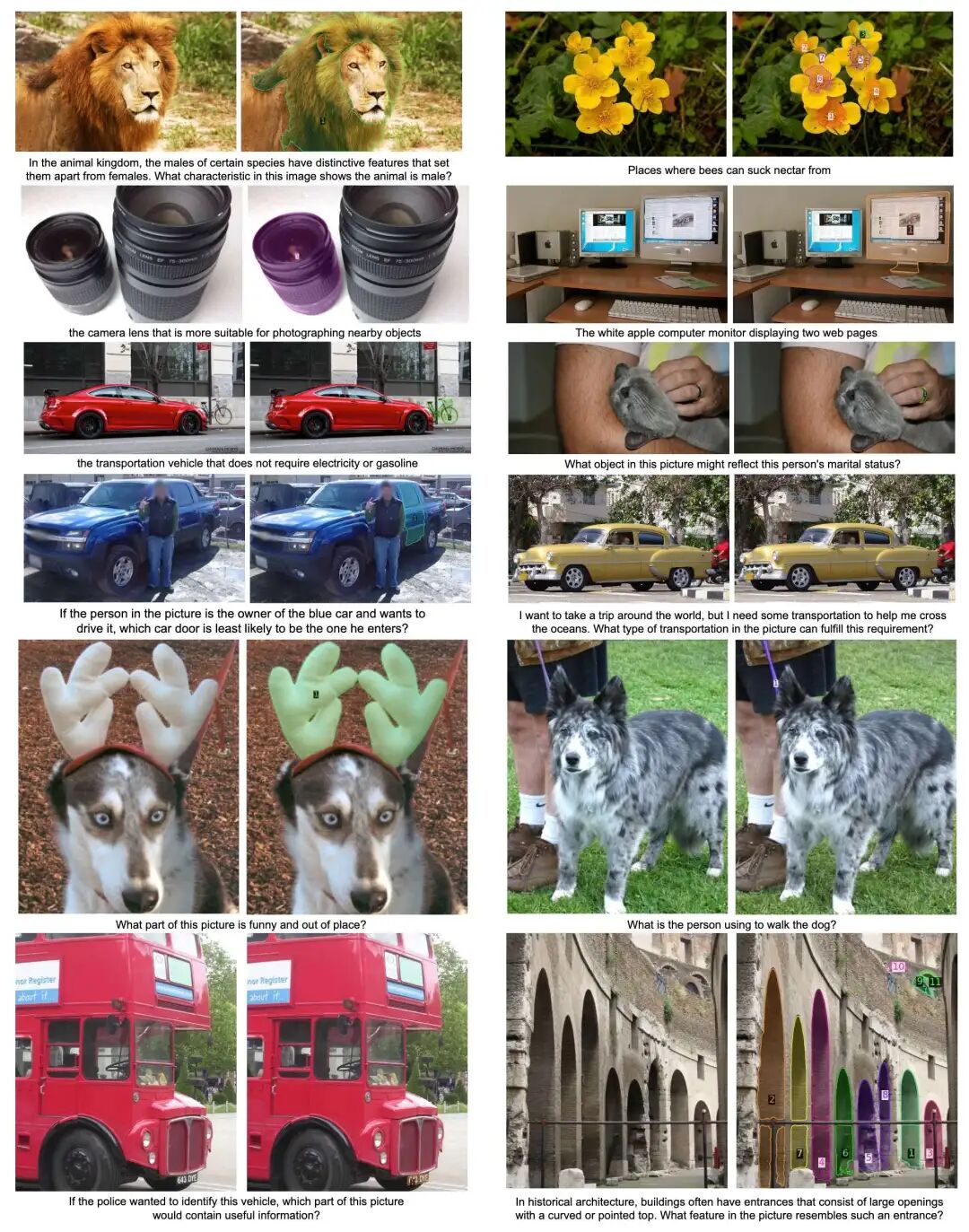
图 6:SAM 3 Agent在ReasonSeg数据集上的成功案例,展示其通过复杂推理查询(如“显示网页的白色苹果显示器”)生成精确分割的能力。
结论
SAM 3的故事不仅是一场技术的胜利,更是一扇通向未来的大门。它为机器人导航提供了“主动感知”的能力,让增强现实内容创作更具灵活性,为科学领域的数据分析注入新的活力。无论是识别果园中的每颗红色苹果,还是在视频中跟踪所有黄色校车,SAM 3都展现了从被动工具到智能代理的转型。
未来,SAM 3 Agent的推理能力可能进一步扩展,处理更复杂的场景和任务。
SAM 1: https://arxiv.org/abs/2304.02643
[2]SAM 2: https://arxiv.org/abs/2408.00714










