
7 篇本周关注到的学术进展(要点版)
【上海交通大学】提出 Harmanoid 框架,双人协同运动模仿方法。
【北京大学】提出LOMORO框架,将多机器人任务分配建模为受资源和监控间隔约束的优化问题。
【清华大学】等基于软提示(Soft Prompt)的学习方法,为每个数据源引入独立的可学习嵌入作为具身特定提示。
【中国科学院大学】等QDepth-VLA,一种通用框架,通过引入辅助的深度预测任务来增强VLA模型的空间感知能力。
【北京大学、智在无界】提出仅需一次仿真演示即可实现多任务泛化,并有效完成从仿真到真实机器人的迁移。
【上海交通大学】等提出“训练场”(training ground)的概念,即一个集任务与场景模拟、具身交互和反馈机制于一体的综合性基础设施。
【英伟达】提出将机器人动作直接用自然语言文本表示,无需修改VLM词汇表或添加专用动作模块试图解决如何构建高效的视觉-语言-动作模型(VLA)以实现通用机器人操作的问题。
(如果有不全面的地方,欢迎大家补充,以期共同进步。PS:没时间看详细介绍的朋友,【要点速览】可供快速浏览。)
1

1
人形机器人真正的潜力并不仅仅在于单个机器人的自主性:两个或更多人形机器人必须能够进行基于物理、具有社会意义的全身交互,以重现人类社交互动的丰富性。
然而,现有的单机器人方法存在孤立性问题,忽略了智能体之间的动态交互,导致接触错位、身体穿透以及动作不自然。
为解决这一问题,本文提出了Harmanoid——一种双人形机器人运动模仿框架,能够将人类之间的交互动作迁移至两个机器人,同时保持运动学上的精确性和物理上的真实性。Harmanoid包含两个关键组成部分:
(i)具备接触感知的运动重定向,通过将SMPL模型中的接触点与机器人顶点对齐,恢复身体间的协调性;
(ii)基于交互的运动控制器,利用针对特定交互设计的奖励机制,确保关键点的协同运动以及符合物理规律的接触行为。
通过显式建模智能体间的接触关系和交互感知的动力学,Harmanoid捕捉到了单机器人框架固有忽略的人形机器人之间的耦合行为。
实验表明,Harmanoid在交互式运动模仿方面显著优于现有单机器人框架,而后者在类似场景中大多表现不佳。

文章链接:https://arxiv.org/pdf/2510.10206v1
项目地址:https://github.com/ZuhongLIU/Harmanoid
2

2

文章链接:https://arxiv.org/pdf/2510.10046v1
3

3
成功的通用型视觉-语言-动作(VLA)模型依赖于在多种机器人平台上,利用大规模、跨具身形态、异构的数据集进行高效训练。
为了促进并充分利用丰富多样的机器人数据源中的异质性,本文提出了一种新颖的软提示(Soft Prompt)方法,仅需极少的额外参数,通过将提示学习的思想引入跨具身形态的机器人学习,并为每个不同的数据源引入独立的可学习嵌入向量。
这些嵌入向量作为特定具身形态的提示,在整体上使VLA模型能够有效利用多样化的跨具身特征。本文提出的新型X-VLA是一种简洁的基于流匹配(flow-matching)的VLA架构,完全依赖经软提示调制的标准Transformer编码器,兼具良好的可扩展性和结构简洁性。
该模型在6个仿真环境以及3个真实世界机器人平台上进行了评估,其中0.9B参数规模的实例X-VLA-0.9B在多项基准测试中均达到了当前最优(SOTA)性能,在从灵活操作能力到跨具身形态、跨环境及跨任务的快速适应能力等多个维度上表现出卓越的性能。

文章链接:https://arxiv.org/html/2509.14380v1
4

4
空间感知与推理对于视觉-语言-动作(VLA)模型完成细粒度操作任务至关重要。然而,现有方法往往缺乏理解和推理实现精确控制所必需的三维结构的能力。
为解决这一局限性,本文提出了QDepth-VLA,这是一种通用框架,通过引入辅助的深度预测任务来增强VLA模型。
该框架设计了一个专门的深度专家模块,用于预测由VQ-VAE编码器生成的深度图的量化潜在标记,从而使模型能够学习到包含关键几何线索的深度感知表征。
在仿真基准和真实世界任务上的实验结果表明,QDepth-VLA在空间推理方面表现出色,并在操作任务中实现了具有竞争力的性能。

文章链接:https://arxiv.org/html/2510.14836v1
5

5
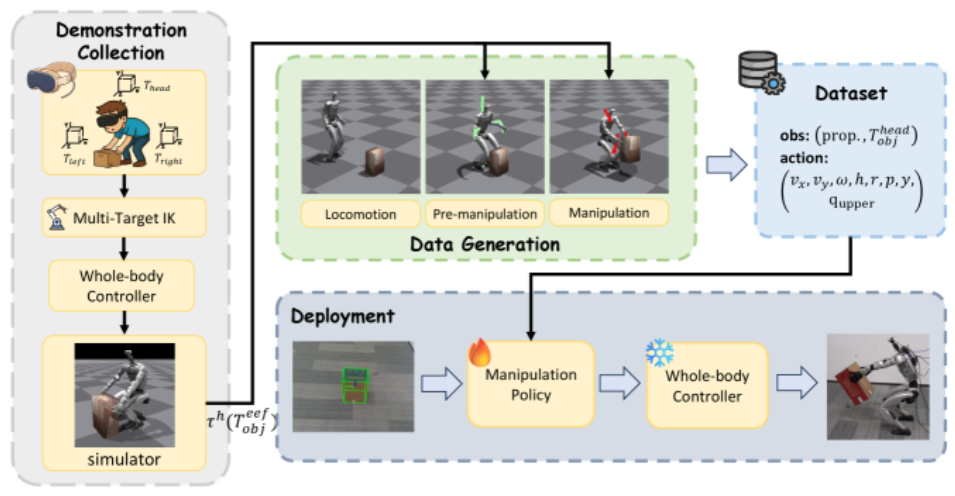
文章链接:https://arxiv.org/html/2510.11258v1
6

6

文章链接:https://arxiv.org/html/2510.12072v1
7

7
将动作直接表示为文本这一最简单的策略却几乎未被探索。本文提出了VLA-0以研究这一思路。本文发现,VLA-0不仅有效,而且表现惊人地强大。
通过合理的设计,VLA-0的表现超越了更为复杂的模型。在广泛用于评估VLA的基准测试LIBERO上,VLA-0在使用相同机器人数据训练的方法中表现最佳。此外,在无需大规模机器人专用训练的情况下,VLA-0的表现也优于那些基于大规模机器人数据训练的方法,如π0、π0.5、GR00T-N1和MolmoAct。
这些优势同样体现在真实世界场景中,VLA-0的表现优于SmolVLA——一种在大规模真实数据上预训练的VLA模型。本文总结了这一出乎意料的发现,并详细阐述了充分发挥这种简单而强大的VLA设计性能所需的具体技术。

文章链接:https://arxiv.org/html/2510.13054v1
项目地址:https://vla0.github.io/
>>>现在成为星友,特享99元/年<<<


【具身宝典】||||
【技术深度】|||||||
【先锋观点】|||
【非开源代码复现】||
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文










