
实习生看几遍演示就会的复杂操作,机器人读百页说明书却仍不知从何下手。这道鸿沟的核心,藏在人类 “想象未来” 的能力里 ——
我们观察时,会同步预判下一步动作、物体动态和目标状态,而非机械模仿。
近期,香港科技大学(广州)与香港大学团队提出Super-Mimic 框架,让机器人从 “看人类做事” 升级为 “想自己该怎么做”:
无需依赖语言指令或精细标注数据,只需观看演示视频,就能在脑中 “预演” 操作过程。

为什么这件事很难?
机器人执行长时序操作(long-horizon manipulation)一直是具身智能领域的难点。
因为这类任务不只是“抓个物体”或“按个按钮”,而是需要连续决策、上下文理解和对未来结果的预测。
比如“清理一张桌子”这个任务:人类只需要扫一眼桌面就能规划顺序——先移走杯子,再叠书本,最后擦桌布。
但对机器人而言,这是一连串没有明确界限的复杂动作,每一步的终止条件、物体关系、约束条件都模糊不清。
以往的强化学习或模仿学习方法,往往依赖固定脚本或逐步监督,一旦环境稍有变化,模型就“懵圈”。
而 Super-Mimic 的目标,是让机器人像人一样——在观察人类演示时,自己构建“未来的想象”

▲图1|这张图概括了 Super-Mimic 的核心理念。它不再只是简单地模仿人类动作,而是能在零样本的条件下,根据人类演示灵活修改任务、迁移新技能,无需任何特定任务的数据训练。换句话说,机器人不只是“学动作”,而是开始理解“为什么要这么做“©️【深蓝具身智能】编译

看懂→想象→行动
这篇论文提出了 Super-Mimic 框架——
一套让机器人具备“视觉理解、未来想象与动作执行”能力的系统。
它的目标不是简单模仿人类的行为,而是让机器人在观察人类演示时主动推理:“人类为什么要这样做?我如果去做,接下来会发生什么?”
整个框架由三个主要部分组成:HIT(Human Intent Translator)、FDP(Future Dynamics Predictor) 和 Action Executor,共同形成了一个从“观察—想象—执行”的具身智能闭环。
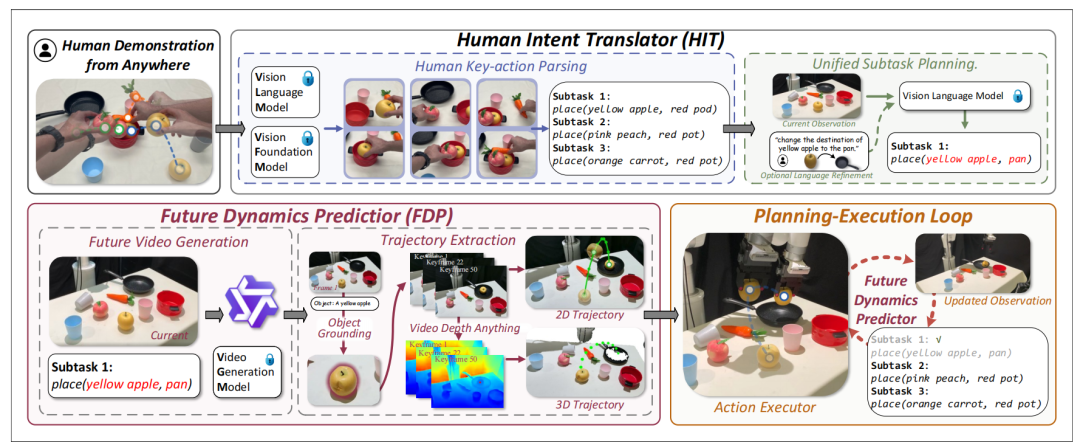
▲图2|这张图展示了 Super-Mimic 的整体流程。©️【深蓝具身智能】编译
首先,HIT 模块利用视觉语言模型(VLM)将人类演示转化为可适配的符号化计划,使机器人能够在模仿之外进行任务调整与技能迁移;
接着,FDP 模块通过视频生成模型“想象”当前子任务的未来执行过程,预测环境的合理变化;
最后,Action Executor 模块根据想象结果生成具体的机器人动作序列并执行。
每个子任务完成后,系统会更新环境观测并重新进入“规划—执行”循环,实现持续的自我推理与调整。
HIT:看懂人类的“意图逻辑”
HIT 模块的任务,是把连续、无脚本的人类演示视频,翻译成机器人能够理解并执行的任务计划。
不同于传统动作识别,HIT 关注的不是“做了哪些动作”,而是这些动作之间的逻辑因果关系。具体做法是:
系统首先利用 MediaPipe 追踪人类手腕的运动轨迹,并根据速度阈值筛选关键帧,提取出视频中最具语义意义的“关键动作”;
这些关键帧随后被输入到视觉语言模型(VLM),由模型解析并抽象为结构化的任务步骤;
最终输出一个由多个子任务组成的符号化计划。

▲图3|HIT整体框架©️【深蓝具身智能】编译
例如:
Subtask 1: Put the green apple into the basket
Subtask 2: Put the pink peach into the trash bin
当用户提供额外语言约束(如“把桃子丢掉”)时,HIT 会修改生成的子任务计划,从而实现任务调整或技能迁移。
这种机制使机器人不仅能模仿动作,还能理解并适应任务意图。
FDP:想象未来的“物理结果”
理解意图之后,机器人还需要预测动作的物理后果——这正是 FDP(Future Dynamics Predictor) 的作用。
FDP 利用一个预训练的视频生成模型 Wan 2.2-Lightning,在当前视觉观测和子任务目标的条件下,生成短视频来“想象”任务执行后的未来场景。
接着,系统使用 Grounded SAM 2 跟踪目标物体的运动轨迹,并通过 Video Depth Anything 估计深度,再结合 RDP 算法 将预测视频中的 2D 路径转换为稀疏、物理上可执行的 3D 轨迹。

换句话说,FDP 让机器人在真正执行动作之前,能够以视频的形式“预演未来”,为控制模块提供可信的动态参考。
它并不重新训练视频模型,而是直接利用生成结果进行空间推理。
Action Executor:行动规划器
Action Executor 是 Super-Mimic 的执行核心。它接收 FDP 生成的 3D 轨迹,经过两步优化后再执行:
抓取规划:利用 AnyGrasp 生成多个抓取候选,并由视觉语言模型选择最合适的方案;
轨迹优化:通过平滑项 (Cs mooth) 与避障项 (C coll) 的联合优化,使路径既连贯又安全。
优化后的轨迹会被发送给机器人执行。任务完成后,系统通过视觉语言模型验证结果;若目标未达成,则返回 HIT 重新规划,进入下一轮“规划—执行”循环。
模型整体协同过程
综上,Super-Mimic 的工作流程如下:
观察阶段(Watch):HIT 解析人类演示,提取关键动作与子任务逻辑;
想象阶段(Imagine):FDP 生成未来视频并提取3D轨迹,预测动作后果;
执行阶段(Act):Action Executor 优化并执行轨迹,实现物理操作;
自我修正(Re-envision):执行后验证结果,若失败则重新规划。
最终,Super-Mimic 能够在零样本(zero-shot)条件下,仅凭人类演示视频完成复杂的多阶段任务——
比如整理桌面、分类物品或准备餐食。
它不只是模仿,而是通过“看→想→做”的闭环,让机器人真正具备了推理与自我调整的能力。

实验结果
研究团队在真实机械臂平台(xArm7 + RGB-D 相机)上进行了多项长时序操作测试,包括备餐分类、桌面整理和无序搬运三种任务。

▲图4|实验平台设置©️【深蓝具身智能】编译
结果显示,Super-Mimic 在完全零样本的条件下,仅凭人类视频演示就能完成复杂操作:
在“备餐”任务中成功率达 50%,是对比方法(20%)的 两倍以上;
在“桌面整理”中达到 40% 成功率,同样远超 ReKep 和 MOKA;
在最难的“无序搬运”中,语言方法几乎全军覆没,而 Super-Mimic 依然能完成 20% 的任务。

▲图5|对实验结果(定量)©️【深蓝具身智能】编译
更重要的是,它还具备迁移技能:看人类分类水果,就能在新环境中自行归类物品。

▲图6|消融实验结果©️【深蓝具身智能】编译
消融实验进一步证明——去掉“意图解析(HIT)”或“未来预测(FDP)”,性能都会显著下降,说明真正的突破来自这两个模块的协同:
理解意图让机器人更准,想象未来让它更稳。

总结
Super-Mimic 的意义不止在于让机器人学会“模仿”,而是让它真正拥有一种具身的想象力。
在以往的模仿学习中,机器人只会复制人类的动作轨迹,却无法理解其中的意图或结果。而这项研究,让机器开始像人类那样去观察、预演、再行动——
它看一段视频,就能自己推断逻辑、预测后果,并在新场景中重新规划。
实验表明,Super-Mimic 能在零样本的条件下完成长时序任务,不依赖语言提示,也不需要任务特定数据。这意味着,未来的机器人只要看过人类的一次操作,就能在陌生环境中举一反三。
编辑|阿豹
审编|具身君
>>>现在成为星友,特享99元/年<<<


【具身宝典】||||
【技术深度】|||||||
【先锋观点】|||
【非开源代码复现】||
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文










