InSUR团队 投稿
量子位 | 公众号 QbitAI
人工智能模型的安全对齐问题,一直像悬在头顶的达摩克利斯之剑。
自对抗样本被发现以来,这一安全对齐缺陷,广泛、长期地存在与不同的深度学习模型中。
对此,北京航空航天大学与中关村实验室团队提出了一项全新框架InSUR,基于指令不确定性约简的思想,实现独立于具体任务与模型的对抗样本生成。该工作已入选NeurIPS 2025。

研究聚焦于语义约束对抗样本(SemanticAE)的生成问题,只需要提供一个指令,InSUR即可生成同时误导已知模型A和未知模型B对抗样本。

不仅如此,研究团队还结合3D生成框架首次实现了3D SemanticAE生成:直接通过一条指令生成自然的3D对抗性物体,并验证了引入的采样技术有效性(ResAdv-DDIM)。
InSUR框架:三维度破解语义不确定性
有效的SemanticAE生成器需要基于指令精确反演得出人类期望的生成范围,并生成对抗性的样本。
由于人类指令中固有的不确定性,现有的SemanticAE生成方法难以解决语义引导和对抗攻击的矛盾。研究团队将其归结为三大痛点:
指称多样性(Referring Diversity)导致对抗优化不稳定,同一指令(如“鲨鱼图像”)可能对应多种语义理解,导致扩散模型等生成工具的优化方向混乱。
描述不完整性(Description Incompleteness)限制了攻击的场景适应性。人类指令往往省略场景细节(如“船”未说明是“水面上的独木舟”),使得语义约束方向不精确,攻击面难以被充分探索。
边界模糊性(Boundary Ambiguity)使得生成器评估困难。语义约束的边界难以定义(如“像老虎”的程度如何量化),导致生成器的评估标准混乱。
InSUR框架通过残差驱动攻击方向稳定、生成过程规则编码嵌入和语义层次抽象评估方法,为语义对抗样本的生成与建模提供有效的方法支撑,整体框架如图1所示。

△图1 InSUR框架示意图
InSUR框架从“采样方法”“任务建模”“生成器评估”三个维度层层突破,实现“可迁移、可适应、高效能验证”的SemanticAE生成。研究首先将SemanticAE生成问题定义为:

其中 表示生成的SemanticAE语义约束的对抗样本。
表示生成的SemanticAE语义约束的对抗样本。 表示符合Text语义描述的数据集合,
表示符合Text语义描述的数据集合, 表示目标模型M对于
表示目标模型M对于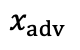 的识别结果,
的识别结果, 表示不符合Text语义的模型输出子集合。
表示不符合Text语义的模型输出子集合。
 与M对于攻击者而言均是未知的。框架整体采用扩散模型实现,并在对抗采样器、上下文编码和生成器评估上引入新机制。
与M对于攻击者而言均是未知的。框架整体采用扩散模型实现,并在对抗采样器、上下文编码和生成器评估上引入新机制。
采样方法:残差驱动稳定攻击方向(ResAdv-DDIM)
针对“指代多样性导致优化混乱”的问题,团队设计了残差引导的对抗DDIM采样器(ResAdv-DDIM),解决扩散模型的对抗采样问题。
扩散模型的初始去噪步骤确定了宏观的特征结构,而后续去噪步骤确定了微观的结构。如何构建有效的宏观对抗结构对于对抗样本的迁移性、鲁棒性具有重要作用。
然而,扩散模型的长流程多步采样使得初始去噪步骤对应的精确对抗特征难以稳定发现。解决该问题的核心思路是:通过“粗预测语言引导的采样过程”,提前锁定对抗优化的方向。具体来说:
在当前去噪步骤时,先预测最终生成目标(2D图像、3D物体的)的“粗略轮廓”;
基于这个轮廓优化对抗方向,避免不同采样步骤中对抗特征的优化方向反复跳跃;
同时加入L2范数约束,确保生成样本不偏离指令语义(如“老虎”的整体形态)。
这一设计让多步扩散模型有效发挥约束正则的作用,显著提升对抗迁移能力与鲁棒性。

△图2 残差驱动的攻击方向稳定
具体而言,研究者将扩散模型的去噪过程表述为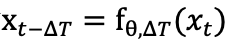 ,先前方法采用直接迭代优化
,先前方法采用直接迭代优化 来实现对抗样本的生成,但
来实现对抗样本的生成,但 梯度方向在不同时间步中不一致,使得对抗优化只能在扩散去噪过程最后几步生效。
梯度方向在不同时间步中不一致,使得对抗优化只能在扩散去噪过程最后几步生效。
研究认为,这约束了多步扩散模型的正则能力,而打破该约束是对抗迁移性和鲁棒性提升的关键。

如上式所示,ResAdv-DDIM少量k次迭代实现对最终预测结果的粗糙预测(g),再基于该预测下攻击损失的梯度调整扩散去噪过程 的方向,使得扩散模型生成过程中不同时刻的样本
的方向,使得扩散模型生成过程中不同时刻的样本 对模型M对攻击优化更加一致。图3的结果验证了该现象(ASR表示攻击成功率)。
对模型M对攻击优化更加一致。图3的结果验证了该现象(ASR表示攻击成功率)。

△图3 实验结果:少量的k步近似采样可以有效提升t较高时攻击优化的稳定性
任务建模:规则编码补全场景信息
在应用场景中,指令Text可能存在歧义或不完整,需要将学习到的引导与对抗攻击任务的目标相结合。
为实现有效的任务适应,引入任务目标嵌入策略,以实现更好的2D语义约束对抗样本生成,并首次实现3D语义约束对抗样本生成。
二维语义约束对抗样本生成的空间约束补全
有效的语义约束对抗样本生成器,应利用图像背景的优化空间,生成能增强攻击效果的背景模式。
然而,因为原始训练中未考虑攻击功能,扩散模型自动学习到的背景生成结果过于单一。
为生成与攻击相关的对抗图像背景,在ResAdv-DDIM的后验采样和对抗优化过程所应用的去噪过程 中,通过一种基于差异化引导掩码的构造,控制扩散模型生成内容的语义引导空间分布。
中,通过一种基于差异化引导掩码的构造,控制扩散模型生成内容的语义引导空间分布。

其中,α定义扩散模型中的噪声比率,ϵ_θ是扩散模型噪声估计函数,M是可自定义的引导掩码。与图像编辑领域不同,掩码M作用在不同引导之间,而不是整体修改区域。
三维语义约束对抗样本生成的可微分渲染管线嵌入
研究团队首次实现了无参考3D语义约束对抗样本生成,进行三维语义约束对抗样本生成的可微分渲染管线整合,主要包含三个部分:

△图4 3D优化管线
基于Trellis框架的3D高斯泼溅渲染(3D Gaussian-splatting Renderer)技术,将扩散模型的隐变量z解码为3D高斯点云; 集成可微渲染器,将3D结构投影为2D图像用于对抗损失计算,并通过 “变换期望(EoT)” 策略应对未知相机视角,实现多视图鲁棒攻击; 将ResAdv-DDIM嵌入到Trellis生成过程中,实现高效鲁棒的攻击优化。
对抗评估:构建严格且易用的SemanticAE对抗样本检验方法
对一个SemanticAE生成器进行评估,需要一个基准测试来判断生成的样本 是否属于指令Text对应的语义集合
是否属于指令Text对应的语义集合 ,并同时明确定义攻击目标
,并同时明确定义攻击目标 。这共同决定了生成器的对抗攻击性能和语义对齐(semantic alignment)能力。
。这共同决定了生成器的对抗攻击性能和语义对齐(semantic alignment)能力。
为了解决这个问题,研究基于SemanticAE生成任务的应用目标,提供了一种用于自动评估的任务构建方法。
首先,在现有的非目标(non-target)评估方法中,攻击目标通常基于ImageNet标签,但这往往过于简单。SemanticAE的约束空间相对宽松,这使得攻击生成模型很容易就能实现成功攻击。
例如,对于指令Text为“大白鲨(great-white-shark)”的攻击任务,使用ImageNet标签中的“虎鲨(tiger-shark)”作为错误分类的类别 任务过于简单。
任务过于简单。
在这个任务中成功攻击,并不能真正体现模型在真实场景下的攻击能力。为了明确评估的边界,研究利用WordNet的分类体系,通过提升抽象层次来重新构建评估标签。如图所示,构建过程分为三步:

△图5 SemanticAE评估方法设计
1、构建下位词图(Hyponymic Graph):基于WordNet定义的下位关系(例如,“鱼”是“动物”的下位词,“金鱼”和“大白鲨”是“鱼”的下位词)来构建ImageNet标签的层级关系图。
2、选择抽象级别(Abstraction Level):从图中筛选出合适的抽象层级,移除过于粗糙(如“动物”)和过于精细的标签。
3、定义攻击目标:将攻击目标定义为规避更高层级的抽象标签。例如,生成一张“大白鲨”的图像,其语义是正确的,但不能被模型识别为更高层级的“鱼”。
第二,从语义约束评估的角度来看,仅仅使用另一个深度学习模型(如CLIP)来进行评估,会将基准的有效性局限于该评估模型的鲁棒性范围内。
因此,研究进一步提出了非对抗性样本生成(non-adversarial exemplar generation)的子任务,要求对抗生成器G在生成对抗样本 的同时,生成一个与之邻近的、可被正确分类的“范例”样本
的同时,生成一个与之邻近的、可被正确分类的“范例”样本 ,以此证明
,以此证明 确实符合语义约束。
确实符合语义约束。
根据上述原则定义相对攻击成功率(ASR_Relative)和语义差异度

其中K是样本数量,S是一种视觉相似性度量,例如LPIPS或MS-SSIM。测量局部相似性更容易,因为它较少依赖基于高层次特征提取深度模型的结果,如Clip。
若假设生成器G没有寻找一个“正面对抗样本”的动机(即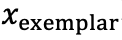 不是对抗样本),如果在两个指标上都获得高分,就可以充分证明G的对抗生成性能。
不是对抗样本),如果在两个指标上都获得高分,就可以充分证明G的对抗生成性能。
实验结果
2D 语义约束对抗样本:迁移攻击性能突破边界
InSUR在2DSemanticAE上整体结果如图6和图7所示,其中InSUR方法的语义约束强度分别设置为ϵ={1.5,2,2.5,3}和ϵ={2,2.5,3,4}。

△图6 ImageNet标签结果
之所以采用多个ϵ值,是因为基线方法难以控制和对齐语义扰动强度。图中以柱状图形式绘制了目标模型的最小/最大ASR(攻击成功率)以及生成图像的LPIPS(感知损失)标准差。

△图7 高抽象层级标签结果
图8展示了InSUR在ϵ=2.5时的结果。

△图8 不同代理模型上的2D生成结
总体而言,在4种代理模型和2种任务设置中,InSUR在所有目标模型中至少实现了1.19倍的平均ASR提升和1.08倍的最小ASR提升,同时保持较低的LPIPS,显示出一致的优越性。图中展示的帕累托(Pareto)改进更为显著。
3D SemanticAE生成:验证InSUR的跨任务可扩展性
将目标物体的视频可视化结果以MPEG4编码导出,并通过读取视频来评估攻击性能。代理目标模型为ResNet50,结果见图9。此前尚无可用的3D语义自动编码器。

△图9 3D SemanticAE生成结果
结果表明,该方法展现出令人满意的攻击性能,验证了InSUR的跨任务可扩展性。
需要注意的是,由于Trellis生成的3D模型与ImageNet图像存在偏差,生成的3D样本的干净准确率(clean accuracy)不高,但显著的相对ASR差异仍可以验证攻击有效性。
可视化结果表明(图10),InSUR生成的对抗样本在迁移攻击性、真实性方面展现出显著优越性。代理模型为ResNet50,目标模型为ViT或ResNet。正确标签标记在下方,模型分类结果标记在图中,绿色为分类正确。

△图10 可视化结果
讨论与展望
InSUR的设计与具体模型和任务解耦,在多种任务中持续提升攻击性能,展现出良好的可扩展性,也为测试时的红队评估框架提供了新思路。
研究还测试了在VLM大模型场景下的攻击性能,表明有效的可扩展性。通过进一步地与现有3D场景生成管线(如 DiffScene、EmbodiedGen 等)集成,InSUR方法可为自动驾驶、具身智能体等安全关键系统生成高逼真度的对抗测试场景。
此外,近期研究表明,扩散模型生成的“困难样本”在对抗训练中具有更高的样本效率。这意味着InSUR不仅可用于“红队测试”(red-teaming),还可作为高质量对抗训练数据的生成器,反向提升模型鲁棒性。
同时,生成质量的进一步提升、在更大规模模型上的验证、以及真实场景的部署适应性,都是未来值得深入探索的方向。
Github链接:https://semanticae.github.io/










