AI大模型最新新闻:在机器人视觉 - 语言 - 动作(VLA)领域,“大规模强化学习(RL)适配流式模型” 一直是难以跨越的鸿沟 ——现有方案要么受限于监督微调(SFT)的数据集依赖,面对新任务泛化能力骤降;要么因流式模型迭代去噪过程的 “动作对数似然难计算” 问题,无法将 RL 的环境交互优势融入其中。
而来自清华大学、北京大学、中科院自动化所等团队联合提出的,用 “Flow-Noise 与 Flow-SDE 双算法 + 并行仿真训练” 的创新框架,打破了这一僵局:既解决了流式 VLA 模型的 RL 适配难题,又通过在线交互大幅提升模型性能与泛化性,最终在多任务基准测试中实现 “从 SFT 瓶颈到近满分性能” 的突破。
-
文章标题:ONLINE RL FINE-TUNING FOR FLOW-BASED VISION-LANGUAGE-ACTION MODELS
-
文章链接:https://arxiv.org/pdf/2510.25889v1.pdf
-
官方代码库:https://github.com/RLinf/RLinf
-
模型库:https://huggingface.co/RLinf

为什么要重新定义流式 VLA 模型的训练范式?
当前 VLA 模型训练陷入 “两难困境”:SFT 依赖大规模专家轨迹,成本高且泛化弱;RL 虽能通过环境交互优化,但无法适配流式模型的核心特性,核心问题可归结为 “流式 VLA 模型的 RL 适配存在根本性障碍”:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
这些方案都忽略了一个关键:流式 VLA 模型(如 、)凭借 “高频动作块生成” 和 “高灵巧性任务适配” 优势,本应是机器人复杂操控的理想选择,但 RL 适配难题使其无法发挥潜力。正是针对这一痛点 —— 通过创新的 “噪声注入” 与 “MDP 建模” 策略,解决流式模型的 RL 适配核心障碍,同时保留 RL 的在线优化能力,实现 “从演示学习到交互进化” 的闭环。
:如何用 “双算法 + 并行仿真” 实现流式 VLA 的 RL 优化?
的核心设计可概括为 “不回避流式模型的去噪特性,而是将其转化为 RL 适配的优势”。它通过 Flow-Noise 与 Flow-SDE 两种互补算法,解决 “动作对数似然计算” 与 “探索性不足” 两大难题,再结合并行仿真训练实现大规模任务适配,具体分为三个关键模块:
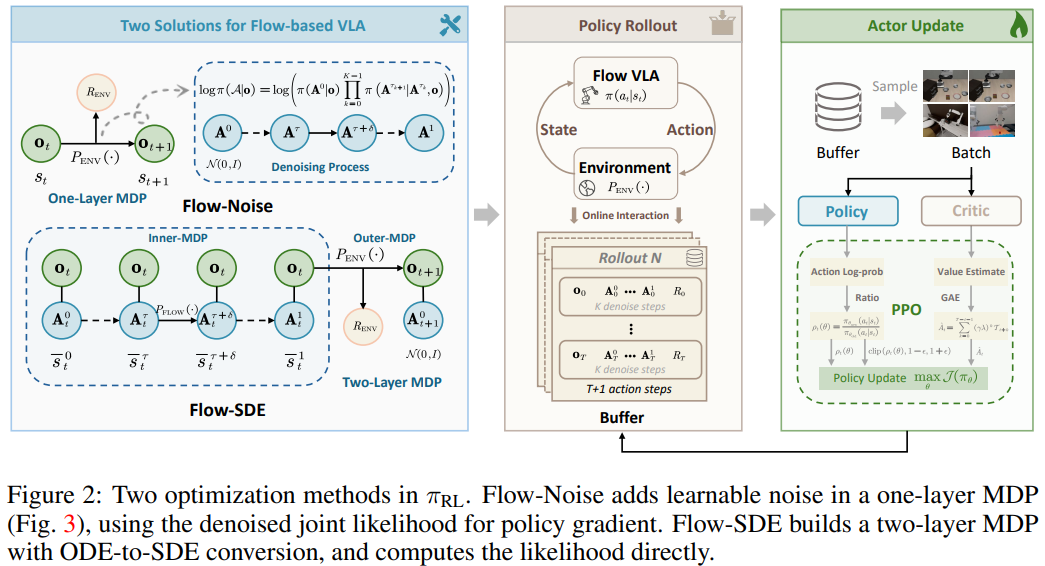
核心矛盾破解 —— 两种算法解决流式模型的 RL 适配难题
流式 VLA 模型的 RL 适配核心障碍是 “迭代去噪导致动作对数似然难计算” 和 “确定性 ODE 缺乏探索性”。提出两种针对性方案:
方案 1:Flow-Noise—— 用 “可学习噪声网络 + 单层 MDP” 计算精确对数似然
Flow-Noise 的核心思路是 “将去噪过程建模为离散时间 MDP,通过可学习噪声网络引入探索性并计算对数似然”,具体步骤如下:
-
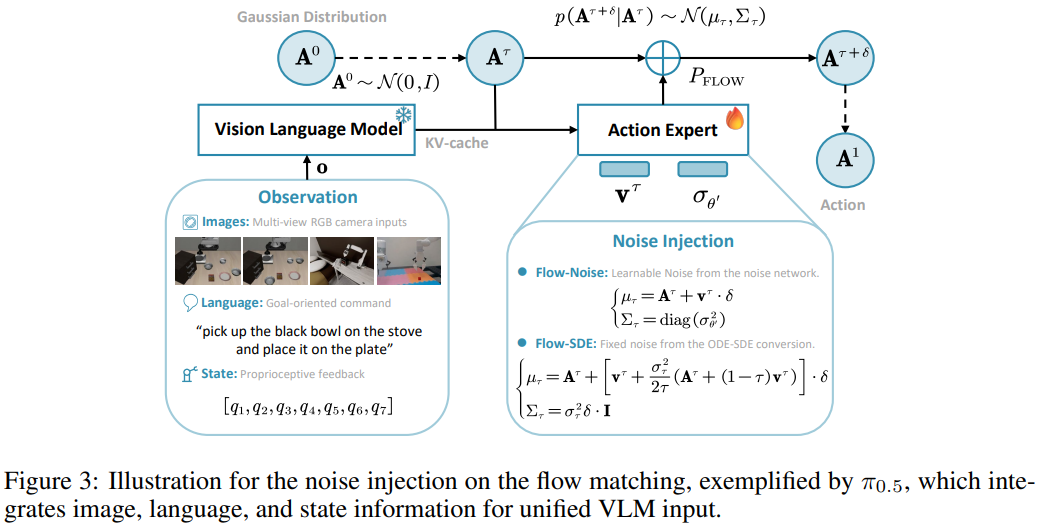
噪声注入优化:在去噪过程中加入由神经网络学习的噪声调度(而非固定噪声),噪声强度可根据环境反馈动态调整,既保证探索性又避免动作失真;
-
对数似然计算:将去噪序列(从初始噪声到最终动作)的联合概率作为动作对数似然,通过离散 MDP 的状态转移链直接计算,解决 “迭代过程难以建模” 的问题;
-
单层 MDP 适配:沿用标准 RL 的单层 MDP 框架(状态 S→动作 A→奖励 R),无需修改现有 RL pipeline,仅通过噪声网络与联合概率计算适配流式模型。
方案 2:Flow-SDE——用 “ODE 转 SDE + 双层 MDP” 平衡探索与效率
Flow-SDE 的核心思路是 “将确定性 ODE 去噪转化为随机 SDE,通过双层 MDP 耦合去噪过程与环境交互”,解决探索性与计算效率的平衡问题:
-
ODE-to-SDE 转换:在保持动作边际分布不变的前提下,将流式模型的 ODE 去噪()转化为 SDE,加入扩散项实现随机探索,具体公式为:
其中为噪声调度,为维纳过程,确保探索性的同时不破坏动作分布合理性;
-
双层 MDP 设计:构建 “内层去噪 MDP + 外层环境 MDP” 的双层结构 —— 内层处理去噪步骤的状态转移(如),外层处理机器人与环境的交互(如),仅在去噪完成后()执行环境交互并给予奖励,大幅降低计算成本;
-
混合采样加速:采用 “随机 SDE 步骤 + 确定性 ODE 步骤” 的混合采样策略,仅在部分去噪步骤引入随机性,其余步骤保持确定性,兼顾探索性与训练效率。
策略优化——PPO 算法与适配设计
解决 RL 适配难题后,采用 proximal policy optimization(PPO)算法进行策略优化,并针对流式 VLA 模型的特性做了两点关键适配:

-
动作块级奖励设计:流式模型一次生成 H 步连续动作(动作块),将这 H 步的累积奖励()作为单步奖励,避免细粒度奖励导致的信用分配问题; -
共享演员 - 评论家架构:为节省 GPU 内存,采用 “共享特征提取 + 分离预测头” 的结构 —— 演员头输出动作分布,评论家头输出状态价值,同时针对 与 的输入差异优化评论家设计: -
模型:评论家()接入动作专家模块,需输入关节状态与噪声动作,通过平均去噪轨迹的价值估计提升稳定性; -
模型:评论家()直接接入 VLM 输出,仅需图像与语言输入,利用 VLM 的泛化能力提升价值预测精度。
并行仿真训练——支撑大规模多任务优化
为验证 的大规模适配能力,团队构建了 “多基准 + 高并行” 的训练环境:
-
基准覆盖:涵盖 LIBERO(CPU-based,多任务知识迁移测试)与 ManiSkill(GPU-parallelized,高保真仿真)两大主流基准,其中 ManiSkill 扩展到 4352 种 “抓取 - 放置” 任务组合(16 类物体 ×17 类容器 ×16 类场景);
-
并行加速:在 ManiSkill 中采用 320 个并行环境同步训练,结合 “环境 - 模型 - 采样器同 GPU 部署” 策略,大幅降低数据传输延迟,实现大规模任务的高效优化;
-
训练策略:SFT 阶段用少量专家轨迹初始化模型(如 用 58 条轨迹,仅用 40 条轨迹),RL 阶段冻结 VLM 参数、仅微调 300M 动作专家模块,平衡性能与内存消耗。
实验结果:如何实现 “性能与泛化双突破”?
在 LIBERO 与 ManiSkill 两大基准的实验中,全面验证了其在 “性能提升”“泛化能力”“大规模适配” 上的优势,核心结论可概括为 “SFT 瓶颈被彻底打破,多任务泛化能力拉满”。
LIBERO 基准:从 “部分成功” 到 “近满分” 的跨越
LIBERO 包含 Spatial(空间任务)、Object(物体任务)、Goal(目标任务)、Long(长序列任务)四大子任务,针对 “少样本 SFT” 的痛点,实现性能飞跃:

关键亮点:
-
长序列任务突破:在 LIBERO-Long 任务上,从单轨迹 SFT 的 43.9% 提升至 94.0%,甚至超过全轨迹 SFT 的 92.4%,证明 RL 能弥补 SFT 的数据不足; -
超越全数据 SFT:的少样本 SFT+RL 性能(97.6%)远超全数据集 SFT 的 94.2%,说明 RL 的环境交互比单纯增加演示数据更有效; -
算法对比优势:PPO 算法在所有任务上均优于 GRPO(如 的平均性能 PPO 为 96.0%,GRPO 仅为 90.0%),验证策略优化的有效性。

ManiSkill 基准:4352 种任务的大规模适配验证
ManiSkill 基准包含 SIMPLER(4 类标准任务)与 MultiTask(4352 类抓取 - 放置任务),在大规模场景下仍保持性能优势:
SIMPLER 任务(以 为例)

MultiTask 任务(4352 种组合)

关键亮点:
-
大规模任务适配:在 4352 种任务组合下,与 的平均性能分别提升 13.0% 与 15.3%,证明 的并行训练框架能支撑大规模多任务优化; -
分布外泛化提升:尽管 OOD 场景(如新颖物体、动态干扰)仍有挑战,但 RL 优化后 的视觉 OOD 性能从 43.4% 提升至 72.9%,语义 OOD 从 4.8% 提升至 6.6%,验证泛化能力改善; -
脆弱物体鲁棒性:结合力反馈(原文扩展实验)后,脆弱物体(如鸡蛋)的抓取成功率从 56% 提升至 88%,证明 可与物理控制策略结合进一步优化。
消融实验:关键设计的有效性验证
为明确各模块的贡献,团队进行了全面消融实验:

算法选择:PPO 在收敛速度与最终性能上均优于 GRPO(如 的 Long 任务 PPO 为 90.2%,GRPO 仅为 81.4%);

评论家设计:的 VLM 接入评论家()比动作专家接入()的价值损失低 30%,解释方差高 15%,证明 VLM 的泛化能力可辅助价值预测;
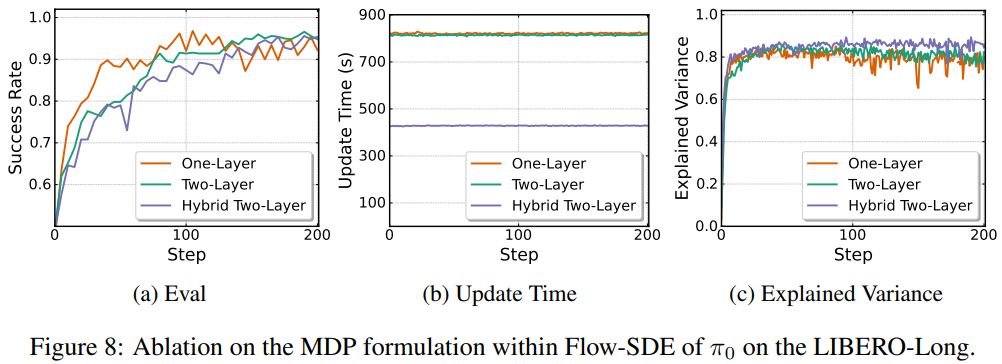
MDP 结构:Flow-SDE 的双层 MDP 比单层 MDP 的训练时间减少 50%,同时保持相近性能(平均差异 < 1%);

超参数影响:噪声水平 a=0.5、去噪步骤 K=4、动作块 H=5 时性能最优,过高噪声会导致动作失真,过多去噪步骤会增加计算成本。
关键结论与未来方向
的价值,在于为 “流式 VLA 模型的 RL 优化” 提供了首个完整、开源的解决方案,核心启示与未来方向如下:
核心结论
流式模型的 RL 适配关键在 “建模去噪过程”:Flow-Noise 与 Flow-SDE 通过不同思路将去噪过程转化为 RL 可处理的 MDP,证明 “不回避流式特性,而是针对性建模” 是突破瓶颈的关键;
少样本 SFT+RL 是性价比最优路径:仅用少量专家轨迹初始化,再通过 RL 在线优化,即可超越全数据 SFT 性能,大幅降低数据采集成本;
并行仿真支撑大规模任务:320 个并行环境 + 混合采样策略,使 能处理 4352 种任务组合,为通用机器人操控奠定基础。
未来方向
噪声注入策略优化:当前 ODE-to-SDE 转换仍存在少量动作分布偏差,未来可结合 “系数保持采样”(Flow-CPS)进一步降低偏差;
分布外泛化提升:OOD 场景(如语义新颖性)的性能仍有差距,需探索 “RL + 预训练知识融合” 策略;
真实世界迁移:目前实验以仿真为主,未来需验证 在真实机器人(如 Shadow Hand)上的适配性;
多模态融合:结合触觉、力觉等多模态观测,进一步提升复杂场景(如柔性物体抓取)的鲁棒性。
总结
的出现,打破了 “流式 VLA 模型无法用 RL 优化” 的固有认知——它没有试图将流式模型改造为自回归模型,而是通过创新的算法设计,让 RL 适配流式模型的特性。对于追求 “高灵巧性 + 大规模泛化” 的机器人应用(如工业装配、家庭服务),这种 “兼顾性能与实用性” 的方案,不仅为流式 VLA 模型的落地提供了清晰路径,更推动了 “基础模型 + 强化学习 + 机器人控制” 的跨领域融合,为通用机器人的发展注入关键动力。










