大家好!今天我们要介绍一项来自 Google DeepMind、西蒙弗雷泽大学 (Simon Fraser University) 和 纽约大学 (New York University) 的重磅研究成果 —— BlenderFusion。
你是否曾惊叹于AI绘画的一键生成,又是否曾苦恼于它无法精准控制画面中的物体?比如,想让画里的猫咪转个身,或者把桌上的苹果换个位置,往往需要繁琐的重绘和祈祷。
现在,BlenderFusion 框架横空出世,它巧妙地将强大的3D图形软件 Blender 与顶尖的 扩散模型 (Diffusion Model) 融合,旨在解决复杂场景下精准、三维感知的视觉编辑难题,让普通用户也能实现电影级的视觉特效创作!
项目主页已开放,快去看看更多惊艳的Demo吧
https://blenderfusion.github.io
🔥 AI视觉编辑的困境与突破
近年的生成式AI,尤其是文生图模型,在生成照片般逼真的图像上取得了巨大成功。然而,当我们需要进行复杂的“视觉合成”——比如从多张图片中提取物体,修改它们的位置、外观,再将它们无缝融入新背景时,这些模型就显得力不从心。它们缺乏对三维空间的理解,难以实现对多个物体的精准、解耦控制。
为了解决这一痛点,研究者们提出了 BlenderFusion,一个遵循“分层-编辑-合成”经典流程的全新框架。它将3D图形软件的精准控制能力与扩散模型的强大合成能力完美结合,实现了对物体、相机和背景的完全解耦和精细化操纵。
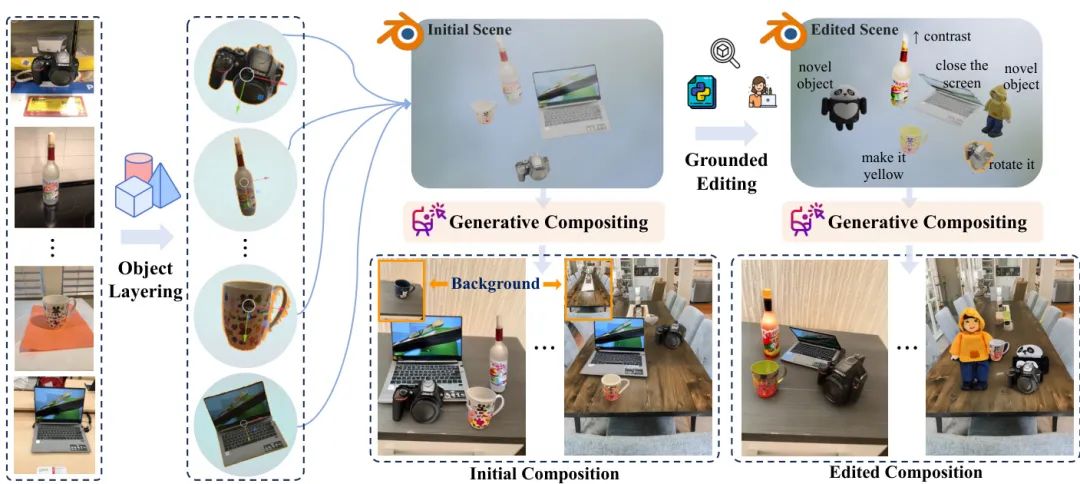
图1: BlenderFusion 框架概览
这张图展示了 BlenderFusion 如何将 Blender 强大的3D编辑能力(如属性修改、形变、插入新资产)与扩散模型的超强合成能力相结合。即使只在简单的视频数据上进行微调,它也能学会精确的物体控制,并泛化到极其精细的多物体编辑和场景合成任务中。
🚀 BlenderFusion 的三步走魔法
BlenderFusion 的工作流程非常直观,就像一位专业的视觉特效师在工作:
1. 分层 (Layering):万物皆可3D化
首先,框架利用现成的视觉基础模型(如 SAM2 和 Depth Pro)从输入的2D图像中自动分割出前景物体,并“提升”为可编辑的3D实体。这个过程就像是把照片里的物体“抠”出来,并赋予它三维的形状。
2. 编辑 (Editing):在Blender中随心所欲
接下来,这些3D化的物体被导入到 Blender 中。在这里,用户可以像玩3D游戏一样,利用 Blender 强大的原生功能进行各种骚操作:
- 基础控制
:移动、旋转、缩放、删除或替换任何一个物体。 - 高级控制
:改变物体的颜色、材质;进行非刚性变换,比如让物体变形、弯曲;甚至从零开始插入一个全新的模型。 - 场景控制
:自由移动相机视角,或者一键更换整个背景图片。
3. 合成 (Compositing):AI的画龙点睛之笔
编辑完成后,Blender会渲染出原始场景和编辑后场景的“草稿图”。最后一步,一个经过特殊训练的生成式合成器 (Generative Compositor) 会接管一切。它将Blender渲染的粗糙结果与背景图像进行融合,智能地修复瑕疵、补全细节、统一光影,最终生成一张完美、逼真、无缝衔接的图像。

图2: BlenderFusion 训练与工作流
该图详细展示了从分层、编辑到合成的完整流程。核心是双流扩散合成器,它同时处理原始(source)和编辑后(target)的场景信息。图中橙色框标示的“源掩码”策略是其关键训练技巧之一。
🤖 核心技术:揭秘强大的生成式合成器
为了让AI合成器能“理解”并完美执行用户的编辑意图,研究团队设计了几个关键创新:
- 双流架构 (Dual-Stream Architecture)
:合成器模型并行处理“编辑前”和“编辑后”两个信息流。这让模型能够清晰地对比变化,准确地生成修改后的内容,而不是凭空想象。 - 源掩码 (Source Masking)
:这是一项聪明的训练策略。在训练时,系统会随机遮挡原始图像中的某些区域。这教会了模型一个重要技能:当某个物体被移除或大幅修改时,要学会“忽略”原始信息,专注于根据Blender的“指令”生成新内容。 - 模拟对象抖动 (Simulated Object Jittering)
:现实世界的视频数据中,往往是相机在动,物体是静止的。为了让模型学会独立控制物体,研究者在训练中引入了一个技巧:固定相机,然后人为地在3D空间中“抖动”物体的位置。这为模型提供了相机与物体解耦控制的宝贵监督信号。
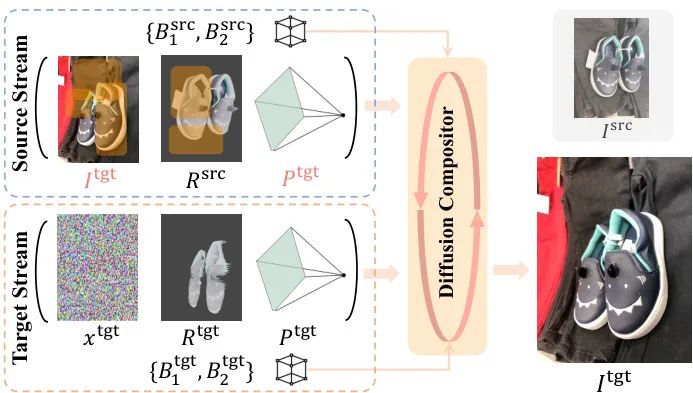
图3: 模拟对象抖动训练策略
该策略通过在固定相机的情况下模拟物体运动,有效增强了模型对物体和相机的解耦控制能力。
✨ 效果惊人:精准控制与复杂合成
BlenderFusion 的效果如何?一句话:显著优于现有方法。
在解耦控制任务中(比如固定相机,只移动或旋转物体),BlenderFusion 展现了超凡的实力。如下图所示,它能精确地执行3D变换,同时完美保持物体的外观细节和背景的稳定,而其他方法则常常出现物体扭曲或背景“跟屁虫”现象。

图4: 解耦视觉控制任务对比
在物体平移、旋转、缩放等任务中,BlenderFusion(最后一列)展示了更精准的控制力、更好的一致性和更彻底的物、场分离。
在更复杂的细粒度编辑和多对象合成任务中,BlenderFusion 的优势更加明显。无论是多个物体的空间重排、复制,还是多图物体的融合,它都能保证几何位置的精确性和外观语义的一致性。

图5: 细粒度多物体编辑与合成
该图展示了 BlenderFusion 在处理复杂任务时的优越性,例如精确地重排和复制多个物体,并保持其原始外观和几何形状。
研究团队还进行了广泛的用户研究,结果显示,在各种编辑任务中,用户对 BlenderFusion 生成结果的偏好率高达 87%,在复杂的细粒度编辑中更是达到了 93.75%!
更令人兴奋的是,BlenderFusion 继承了Blender的全部编辑能力,可以实现训练数据中从未见过的复杂操作,如物体变形、材质替换、添加贴花等,真正实现了“所想即所得”的渐进式编辑。

图6: 继承Blender的强大编辑能力
上图展示了模型对野外图像的泛化能力。下图则展示了BlenderFusion支持的渐进式、多样化编辑,例如改变颜色、部件级变形、替换纹理等,这些都超越了训练数据的范畴。
总结
BlenderFusion 通过将3D图形工具的精确性与生成模型的真实感相结合,为视觉内容创作领域带来了革命性的突破。它不仅显著提升了多物体场景编辑的可控性和灵活性,更为复杂的视觉内容创作提供了一个强大而实用的解决方案。
这项工作无疑为未来的视觉编辑和内容创作工具指明了一个新的方向,让我们共同期待一个创作者可以像上帝一样自由编辑虚拟世界的未来!
-- 完 --
机智流推荐阅读:
1. 空间智能,AI 的终极前沿: 李飞飞YC创业营万字演讲
2. 搜索更少,答案更准!ByteDance与NTU联合推出MMSearch-R1,革新多模态信息检索
4. 清华字节Seed推出PAROAttention:巧用Token“重整术”,视觉生成模型无损加速2.7倍!
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
在「机智流」公众号后台回复下方标红内容即可加入对应群聊:
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群




![2025年中国服务器电源行业发展背景、产业链全景、发展现状及趋势分析:算力需求激增带动,AI服务器电源市场规模加速扩张[图]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-09-09/68bf7d1046efb.jpeg)





