
ICML 2025 将在在加拿大温哥华当地时间 7月13日到19日举办,来一起和使用书生Intern和千问Qwen盘点 ICML 2025 各方向论文,据不完全统计 ICML 共 3342 篇论文中稿,其中 Oral 121 篇、Spotlight 225 篇、Poster 2996 篇。
今年的 ICML 2025 在强化学习(RL)领域可谓是百花齐放!我们精选了30篇重磅论文,为您揭示最新的研究热点与技术突破。从解决模型偏差的 MICE 算法,到应对分布外(OOD)挑战的 PARS 和 C2IQL;从借鉴狼群战术的 Wolfpack 对抗攻击,到重塑LLM训练范式的 eva 自博弈框架;再到探索智能体可塑性与知识遗忘问题的 C-CHAIN 和 DRAGO。这不仅是一场技术的盛宴,更是未来智能体发展的风向标。准备好了吗?让我们一起潜入RL研究的最前沿!
书生体验链接:
https://chat.intern-ai.org.cn/
千问:
https://chat.qwenlm.ai/
(1) 告别『胆小』探索:MICE算法如何通过记忆驱动降低约束强化学习中的风险
论文原始英文标题:
Controlling Underestimation Bias in Constrained Reinforcement Learning for Safe Exploration
论文链接:
https://icml.cc/virtual/2025/poster/44096
简要介绍:
由上海交通大学的研究者提出了 MICE(记忆驱动的内在成本估计) 方法。该工作发现,在约束强化学习中,对成本价值函数的低估是导致训练中频繁违反约束的关键原因。受人类闪光灯记忆的启发,MICE 构建了一个记忆模块来存储危险状态,通过引入内在成本来纠正低估偏差,从而促进更安全的探索。
核心图片:
(2) 线下RL的『外推』之痛:PARS如何通过惩罚与缩放驯服Q函数
论文原始英文标题:
Penalizing Infeasible Actions and Reward Scaling in Reinforcement Learning with Offline Data
论文链接:
https://icml.cc/virtual/2025/poster/45886
简要介绍:
由 LG AI Research 和韩国科学技术院(KAIST)的研究者提出了 PARS (Penalizing infeasible Actions and Reward Scaling) 算法。该工作指出,离线强化学习中的Q值外推错误是性能瓶颈,特别是基于ReLU的MLP在数据范围外的线性外推行为。PARS通过奖励缩放与层归一化(RS-LN)以及对不可行区域动作的惩罚(PA)机制,有效引导Q值在数据范围外逐渐减小,显著提升了算法在D4RL基准测试中的性能。
核心图片:
(3) 跨动态学习的『禁区』:ASOR如何聚焦全局可达状态,提升策略迁移能力
论文原始英文标题:
Policy Regularization on Globally Accessible States in Cross-Dynamics Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/45810
简要介绍:
由南洋理工大学等机构的研究者提出了 ASOR (Accessible State Oriented Policy Regularization)。该工作发现,在跨动态环境中,由于状态可达性的变化,模仿专家轨迹可能产生误导。ASOR通过将模仿学习限制在所有动态下都可达的“全局可达状态”上,并结合奖励最大化,有效缓解了这一问题,显著提升了跨域策略迁移算法的性能。
核心图片:
(4) 🚀 RLEF:用强化学习与执行反馈『接地气』,让代码大模型持续进化
论文原始英文标题:
RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/45358
简要介绍:
由 Meta 的研究团队提出了 RLEF(基于执行反馈的强化学习)。该工作旨在通过端到端的强化学习,教会大语言模型在代码生成任务中有效利用单元测试和错误信息等执行反馈。RLEF将代码生成构建为一个多轮对话的RL环境,通过最大化最终代码的通过率来优化模型,在CodeContests等高难度编程基准上取得了SOTA性能,并显著降低了所需的样本数量。
核心图片:
(5) SimbaV2:超球面归一化,为可扩展深度强化学习注入稳定性
论文原始英文标题:
Hyperspherical Normalization for Scalable Deep Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/44241
简要介绍:
由韩国科学技术院(KAIST)和德克萨斯大学奥斯汀分校等机构的研究者提出了 SimbaV2 架构。该工作指出,传统RL在模型和计算规模扩大时常遭遇过拟合与优化不稳定的问题。SimbaV2通过引入超球面归一化来约束权重和特征范数的增长,并结合分布式价值估计和奖励缩放来稳定梯度,从而解决了这一难题,在57个连续控制任务上实现了SOTA性能。
核心图片: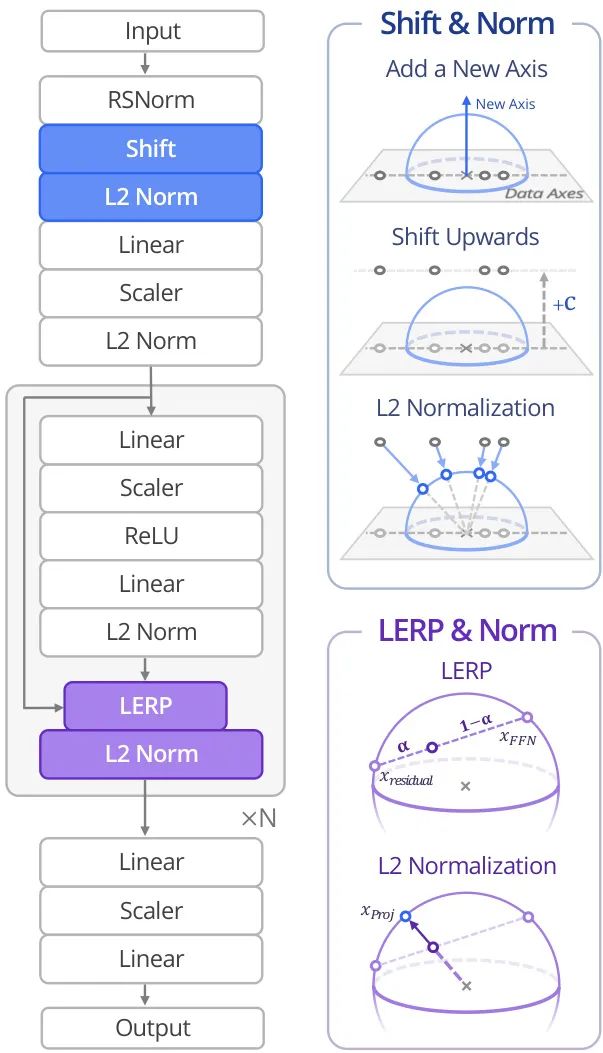
(6) 🔥 在线世界模型规划:用『现学现卖』对抗灾难性遗忘的持续强化学习
论文原始英文标题:
Continual Reinforcement Learning by Planning with Online World Models
论文链接:
https://icml.cc/virtual/2025/poster/44151
简要介绍:
由新加坡国立大学等机构的研究者提出了 OA (Online Agent) 框架。针对持续强化学习中的灾难性遗忘问题,该工作提出通过在线学习一个“Follow-The-Leader”浅层世界模型来捕捉环境动态,并利用模型预测控制进行规划。这种方法在理论上被证明具有低遗憾,并且通过增量式更新,智能体能够在不遗忘旧技能的同时持续学习新任务。
核心图片: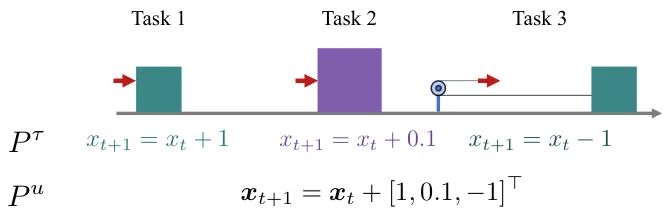
(7) 生物序列设计的『保守探索』:δ-保守搜索如何提升离策略强化学习
论文原始英文标题:
Improved Off-policy Reinforcement Learning in Biological Sequence Design
论文链接:
https://icml.cc/virtual/2025/poster/46683
简要介绍:
由 Mila 和 KAIST 等机构的研究者提出了 δ-保守搜索(δ-CS)。在生物序列设计中,由于代理模型在分布外数据上的不准确性,传统RL方法性能受限。δ-CS通过将探索限制在可靠区域内来增强鲁棒性:它从高分序列出发,以概率δ随机掩码部分序列,然后让策略进行去噪生成新序列。这种保守的搜索策略显著提升了GFlowNets在DNA、RNA、蛋白质等多种设计任务中的表现。
核心图片:
(8) 狼群攻击!一种针对鲁棒多智能体强化学习的新型对抗策略
论文原始英文标题:
Wolfpack Adversarial Attack for Robust Multi-Agent Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/46646
简要介绍:
由蔚山科学技术院(UNIST)的研究者提出了 狼群对抗攻击(Wolfpack Adversarial Attack) 框架。传统鲁棒MARL方法难以抵御协同攻击。受狼群狩猎策略启发,该攻击框架首先瞄准一个初始智能体,然后攻击前来协助的智能体,从而破坏整体协作。同时,作者提出了 WALL (Wolfpack-Adversarial Learning) 框架,通过训练智能体进行系统性协作来有效防御此类攻击。
核心图片:
(9) 分段反馈强化学习:反馈频率如何影响学习效率?
论文原始英文标题:
Reinforcement Learning with Segment Feedback
论文链接:
https://icml.cc/virtual/2025/poster/46633
简要介绍:
由伊利诺伊大学香槟分校的研究团队提出了 分段反馈强化学习 模型。该工作弥合了单步反馈与轨迹反馈之间的鸿沟,研究了将一个回合(episode)划分为m个分段并仅在段末提供反馈的场景。研究发现:在二元反馈(好/坏)下,增加分段数m能指数级降低遗憾;然而,在总和反馈(奖励总和)下,增加m对减少遗憾的帮助却微乎其微。
核心图片:
(10) 线下到线上RL的新篇章:C2IQL如何实现安全的策略迁移
论文原始英文标题:
C2IQL: Constraint-Conditioned Implicit Q-learning for Safe Offline Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/46250
简要介绍:
由香港科技大学的研究者提出了 C2IQL (约束条件隐式Q学习)。该工作为解决安全离线RL中的OOD问题,首先将IQL扩展到约束设置(CIQL),然后在CIQL基础上,通过一个成本重构模型来获得更准确的非折扣累积成本,并引入灵活的约束条件机制,以适应动态安全阈值,从而在保证安全的同时最大化奖励。
核心图片:
(11) 🔥 DIME:当扩散模型遇上最大熵强化学习
论文原始英文标题:
DIME: Diffusion-Based Maximum Entropy Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/46144
简要介绍:
由卡尔斯鲁厄理工学院(KIT)和达姆施塔特工业大学(TU Darmstadt)等机构的研究者提出了 DIME (基于扩散的最大熵强化学习)。传统最大熵RL使用高斯策略,表达能力有限。DIME创新地将富有表现力的扩散模型作为策略,并利用近似推断技术推导了最大熵目标的下界,设计了一个可证明收敛到最优扩散策略的策略迭代方案,在不增加过多算法复杂度的前提下,显著优于其他基于扩散的方法。
核心图片:
(12) Ex²PSRO:在多智能体博弈中,如何通过显式探索发现高社会福利的均衡?
论文原始英文标题:
Explicit Exploration for High-Welfare Equilibria in Game-Theoretic Multiagent Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/46142
简要介绍:
由密歇根大学的研究团队提出了 Ex²PSRO。在多均衡博弈中,标准PSRO算法可能收敛到次优解。该工作通过在策略空间中进行显式探索来引导算法发现高社会福利的均衡点。具体来说,算法从已有的模拟数据中提取高福利行为,训练一个探索策略,并用其正则化最佳响应的训练过程,从而有效引导策略生成,发现更优的社会福利解决方案。
核心图片:
(13) 🚀 AlphaQCM:用分布式强化学习在金融市场中挖掘Alpha因子
论文原始英文标题:
AlphaQCM: Alpha Discovery in Finance with Distributional Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/46517
简要介绍:
由厦门大学等机构的研究者提出了 AlphaQCM。该工作将公式化Alpha因子的发现问题重构为一个非平稳且奖励稀疏的马尔可夫决策过程。为了解决这些挑战,AlphaQCM采用分布式强化学习,通过Q网络和分位数网络分别学习Q函数和分位数,并利用分位数条件矩(QCM)方法学习无偏的方差作为探索奖励,从而高效地在巨大的搜索空间中挖掘有效的Alpha因子。
核心图片: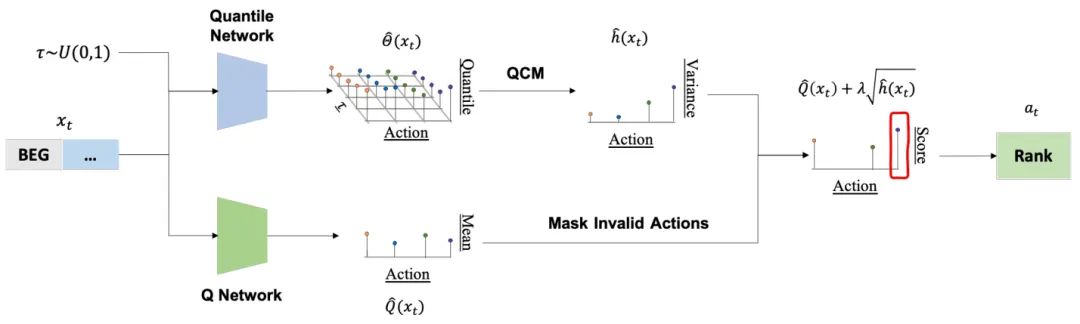
(14) 别只看数量级!论强化学习遗憾界中的常数项为何至关重要
论文原始英文标题:
Position: Constants are Critical in Regret Bounds for Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/40179
简要介绍:
这是一篇由米兰理工大学的研究者撰写的立场型论文(Position Paper)。该工作建设性地质疑了当前理论RL研究中忽视遗憾界中常数项的趋势,认为这导致了理论与实践的脱节。作者以UCBVI算法为例,通过改进其探索奖励项和遗憾分析,证明了优化常数项能显著提升算法的实际经验性能,从而呼吁研究者们应更加关注算法设计和分析中的常数项。
核心图片: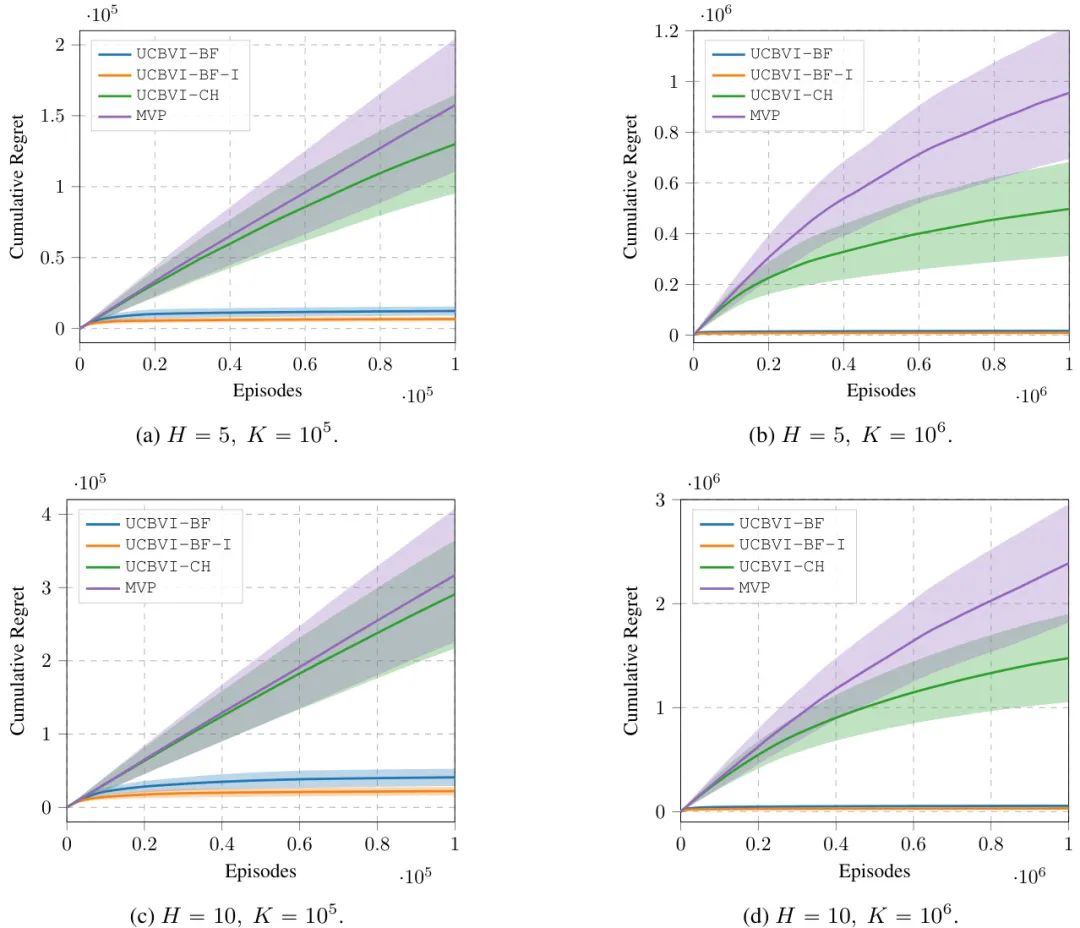
(15) 🔥 当RL遇上最优传输:一种与强化学习兼容的扩散策略
论文原始英文标题:
Score-Based Diffusion Policy Compatible with Reinforcement Learning via Optimal Transport
论文链接:
https://icml.cc/virtual/2025/poster/46577
简要介绍:
由上海人工智能实验室等机构的研究者提出了 OTPR。该工作创新性地将最优传输理论与扩散策略结合,用于强化学习微调。OTPR将Q函数视为传输成本,策略视为最优传输映射,实现了扩散策略与RL的高效稳定结合。此外,它引入了掩码最优传输和基于兼容性的重采样策略,在多个仿真任务中表现出卓越的性能和鲁棒性。
核心图片:
(16) 零样本泛化在离线强化学习中的可证明性
论文原始英文标题:
Provable Zero-Shot Generalization in Offline Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/46618
简要介绍:
由香港中文大学(深圳)和普林斯顿大学的研究者提出了 PERM 和 PPPO 两种元算法。该工作首次系统研究了离线强化学习的零样本泛化(ZSG)问题,并证明了在没有上下文信息的情况下,传统离线RL算法难以泛化。作者提出的新算法利用悲观策略评估来指导策略学习,并从理论上证明了它们能够找到具有ZSG能力的近优策略。
核心图片:
(17) 线下到线上RL的新起点:在线预训练如何解决价值估计不准问题
论文原始英文标题:
Online Pre-Training for Offline-to-Online Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/46420
简要介绍:
由 LG AI Research 和韩国科学技术院(KAIST)的研究者提出了 OPT (Online Pre-Training)。针对离线预训练智能体在线微调时因价值估计不准而性能不佳的问题,OPT创新地在离线预训练和在线微调之间增加了一个“在线预训练”阶段。该阶段专门为在线微调训练一个新的价值函数,从而有效解决了价值估计偏差,在D4RL基准上平均性能提升了30%。
核心图片: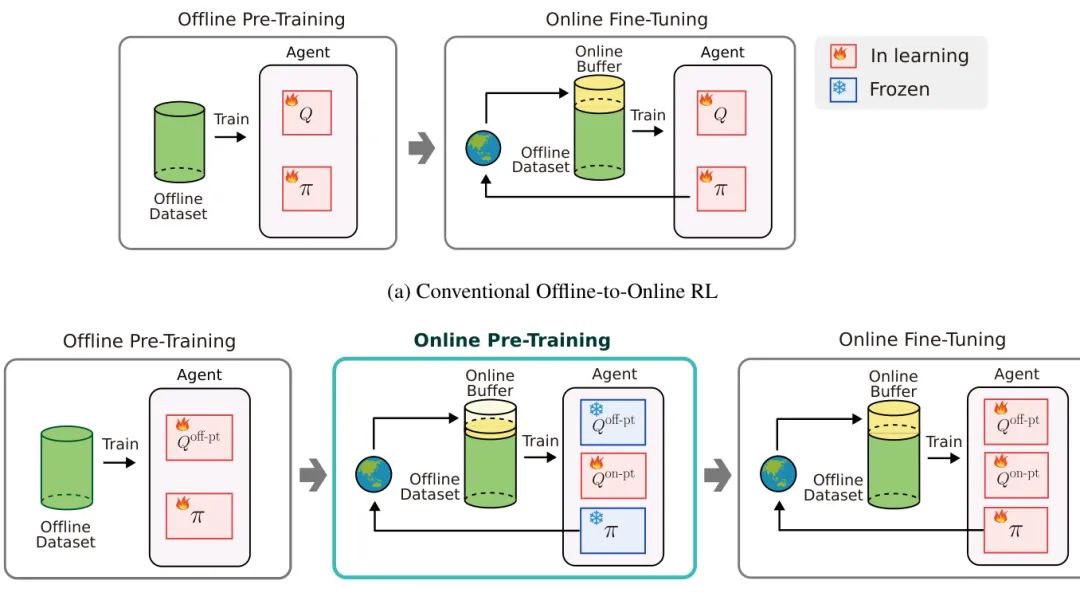
(18) 🔥 最大化轨迹的总相关性:一种让RL行为更简单、更鲁棒的新思路
论文原始英文标题:
Maximum Total Correlation Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/46265
简要介绍:
由卡尔斯鲁厄理工学院(KIT)和达姆施塔特工业大学(TU Darmstadt)的研究者提出了 MTC-RL (最大总相关强化学习)。该工作主张通过最大化智能体轨迹内部的总相关性,来引导策略学习更简单、一致和可压缩的行为。MTC-RL在标准RL目标之上增加了一个最大化总相关性的目标,并提出了一个实用的算法来优化此目标。实验表明,该方法能自然地生成周期性轨迹,并显著提升了对噪声和动态变化的鲁棒性。
核心图片:
(19) 偏好可控的强化学习:结合先进多目标优化
论文原始英文标题:
Preference Controllable Reinforcement Learning with Advanced Multi-Objective Optimization
论文链接:
https://icml.cc/virtual/2025/poster/46501
简要介绍:
由埃因霍芬理工大学的研究团队提出了 PCRL (Preference Controllable RL) 框架。为了解决传统多目标RL(MORL)方法在帕累托最优解覆盖和偏好控制精度上的局限性,PCRL框架训练一个以用户偏好为输入的元策略,并兼容先进的多目标优化(MOO)算法。作者还提出了一个专为PCRL设计的偏好正则化MOO算法(PreCo),在多达六个目标的复杂环境中展现了卓越的可控性和帕累托前沿覆盖能力。
(20) RobustZero:增强MuZero在状态扰动下的鲁棒性
论文原始英文标题:
RobustZero: Enhancing MuZero Reinforcement Learning Robustness to State Perturbations
论文链接:
https://icml.cc/virtual/2025/poster/46000
简要介绍:
由奥尔堡大学等机构的研究者提出了 RobustZero。这是首个旨在增强MuZero类方法在状态扰动下鲁棒性的工作。RobustZero设计了一个新颖的训练框架,包含一个自监督表示网络(用于生成一致的隐状态)和一个独特的损失函数。此外,它还引入了自适应调整机制,使模型能同时抵御最坏情况和随机情况的状态扰动,在多个复杂环境中表现出色。
核心图片: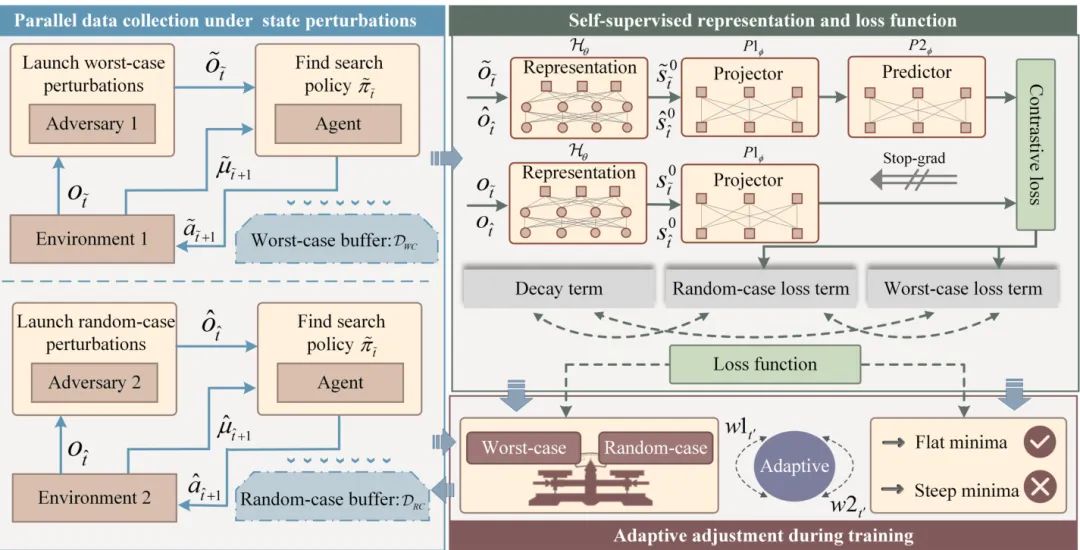
(21) DRAGO:持续模型基强化学习中的知识保留
论文原始英文标题:
Knowledge Retention in Continual Model-Based Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/45991
简要介绍:
由布朗大学的研究者提出了 DRAGO。该工作针对持续模型基强化学习(MBRL)中的灾难性遗忘问题,提出了一种新颖的方法。DRAGO包含两个核心组件:一是利用生成模型进行“合成经验回放”,在不存储旧数据的情况下强化已学动态;二是通过内在奖励机制“通过探索重拾记忆”,引导智能体重新访问先前任务的相关状态,从而实现知识的有效保留和整合。
核心图片:
(22) DRMARL:用于动态滑槽映射的分布式鲁棒多智能体强化学习
论文原始英文标题:
Distributionally Robust Multi-Agent Reinforcement Learning for Dynamic Chute Mapping
论文链接:
https://icml.cc/virtual/2025/poster/45979
简要介绍:
由杜克大学和亚马逊等机构的研究者提出了 DRMARL 框架。该工作针对亚马逊机器人仓库中的包裹分拣问题,在包裹入库率不确定的情况下,学习一个对入库率的对抗性变化具有弹性的目的地-滑槽映射策略。DRMARL利用分组分布式鲁棒优化(group DRO),并引入一种基于上下文赌博机(contextual bandit)的最坏情况奖励估计器,显著提高了学习效率和策略鲁棒性,在仿真中平均减少了80%的包裹再循环。
核心图片:
(23) 🔥 告别可塑性丧失:C-CHAIN如何通过减少“流失”来缓解持续强化学习的困境
论文原始英文标题:
Mitigating Plasticity Loss in Continual Reinforcement Learning by Reducing Churn
论文链接:
https://icml.cc/virtual/2025/poster/45929
简要介绍:
由 Mila 和蒙特利尔大学等机构的研究者提出了 C-CHAIN。该工作从“流失”(churn,即由小批量训练引起的批外数据网络输出变异性)的视角研究了深度持续RL中的可塑性丧失问题。研究表明,可塑性丧失与流失加剧高度相关,而减少流失有助于防止神经正切核(NTK)矩阵的秩崩溃。C-CHAIN通过持续最小化流失,在多个持续学习基准上显著提升了学习性能。
核心图片:
(24) 🔥 eva:用奖励引导的提示进化,开启大语言模型RL新篇章
论文原始英文标题:
Reward-Guided Prompt Evolving in Reinforcement Learning for LLMs
论文链接:
https://icml.cc/virtual/2025/poster/46064
简要介绍:
由 Google DeepMind 的研究团队提出了 eva。该工作首次实现了让LLM在RL训练中通过奖励信号自适应地创造和优先选择有用的提示。eva将LLM训练视为一个创建者(生成提示)和解决者(生成回复)之间的非对称自博弈,通过奖励优势来识别有用的提示并进行演化。在Arena-Hard等基准上,eva显著提升了gemma-2-9b-it的性能,超越了claude-3-opus。
核心图片:
(25) 贝尔曼无偏性:通往可证明高效的分布式强化学习之路
论文原始英文标题:
Bellman Unbiasedness: Toward Provably Efficient Distributional Reinforcement Learning with General Value Function Approximation
论文链接:
https://icml.cc/virtual/2025/poster/46074
简要介绍:
由韩国科学技术院(KAIST)的研究者提出了 贝尔曼无偏性 的关键概念。该工作旨在解决分布式RL中,因分布的无限维特性而被忽视的理论挑战。研究发现,在所有统计泛函中,只有矩泛函(moment functionals)能够被精确且无偏地学习。基于此,作者提出了 SF-LSVI 算法,在通用价值函数近似下实现了
核心图片:
(26) 🔥 物理约束下的量子控制:用强化学习驾驭量子世界
论文原始英文标题:
Reinforcement Learning for Quantum Control under Physical Constraints
论文链接:
https://icml.cc/virtual/2025/poster/45921
简要介绍:
由慕尼黑大学的研究者提出了一种 物理约束下的强化学习算法。该工作通过将量子态动力学的时间尺度和现实控制信号的限制作为约束,有效地缩小了RL算法的解空间。这种方法不仅提高了量子控制任务的保真度(在所有测试系统中均超过0.999),还增强了对噪声和实验缺陷的鲁棒性,并在计算上更具可扩展性。
核心图片: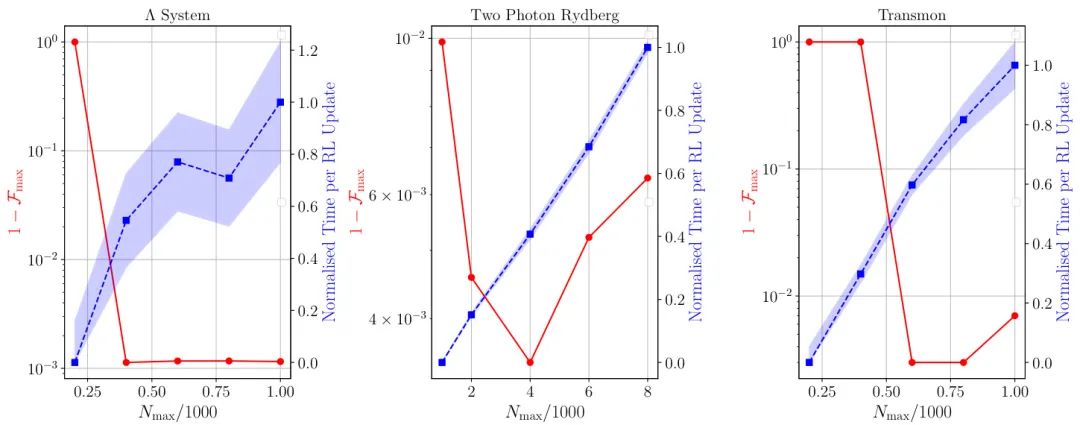
(27) 为量子强化学习建立基准:一种新的统计评估方法
论文原始英文标题:
Benchmarking Quantum Reinforcement Learning
论文链接:
https://icml.cc/virtual/2025/poster/45915
简要介绍:
由慕尼黑工业大学的研究团队提出了一种新颖的 QRL基准测试方法。该工作指出,当前QRL领域缺乏统一的基准和严格的统计验证,导致许多关于“量子优势”的声明可能存在误导。作者提出了一种基于样本复杂度和统计显著性的评估流程,并设计了一个可灵活扩展难度的基准环境。通过大规模实验,他们对QRL的性能给出了更细致的评估,对先前的一些优势声明提出了质疑。
核心图片:
(28) 线下到线上RL的数据魔法:基于无分类器扩散模型的生成增强
论文原始英文标题:
Offline-to-Online Reinforcement Learning with Classifier-Free Diffusion Generation
论文链接:
https://icml.cc/virtual/2025/poster/46491
简要介绍:
由北京大学的研究者提出了 CFDG (无分类器扩散生成)。该工作通过无分类器引导的扩散模型,显著提升了离线和在线数据的生成质量,解决了O2O RL中生成数据与在线数据分布不符的问题。CFDG将离线和在线数据视为不同标签进行条件生成,并通过重加权方法使生成数据更符合在线策略,在D4RL基准上平均性能提升了15%。
核心图片: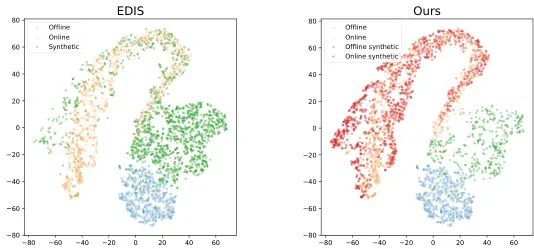
(29) 🚀 最大熵RL与扩散策略的联姻:MaxEntDP
论文原始英文标题:
Maximum Entropy Reinforcement Learning with Diffusion Policy
论文链接:
https://icml.cc/virtual/2025/poster/46039
简要介绍:
由上海人工智能实验室等机构的研究者提出了 MaxEntDP。传统最大熵RL算法SAC使用高斯策略,在多模态任务中探索能力有限。该工作创新地采用表现力更强的扩散模型作为策略表示,并提出了Q加权噪声估计和对数概率的数值积分近似方法,成功将扩散模型融入SAC框架。实验证明,MaxEntDP在Mujoco基准上优于高斯策略和其他生成模型。
核心图片:
(30) 🔥 分布式鲁棒强化学习的“降维打击”:一个平均奖励下的归约框架
论文原始英文标题:
A Reduction Framework for Distributionally Robust Reinforcement Learning under Average Reward
论文链接:
https://icml.cc/virtual/2025/poster/46132
简要介绍:
由中佛罗里达大学的研究团队提出了一个 基于归约的框架。该工作解决了在平均奖励准则下,分布式鲁棒RL研究不足的问题。通过将鲁棒平均奖励优化问题转化为一个具有特定折扣因子的鲁棒折扣奖励优化问题,该框架实现了数据高效和可扩展性。作者设计了模型基的归约算法,并提供了首个数据效率和可扩展性保证,为在不确定环境下优化长期性能提供了具体方案。
核心图片:
以上内容根据ICML 2025官网论文由 AI 生成,信息可能有误,仅供学术交流使用。
-- 完 --

书生体验链接:
https://chat.intern-ai.org.cn/
千问:
https://chat.qwenlm.ai/










