

作者:InternLM、Qwen 等 LLM
引言
随着大型语言模型的飞速发展,智能体(Agent)已成为人工智能领域的前沿焦点。本文汇总了 ICML 2025 Oral 论文中的 7 篇智能体方向论文,集中展示了智能体研究的三个核心发展方向:评估与基准、学习与训练范式以及系统设计与治理。
在评估与基准方面,研究者们正致力于构建更全面、更贴近现实的测试平台。OmniBench、EmbodiedBench和ITBench三篇论文分别针对通用虚拟智能体、具身智能体和企业级IT运维场景,提出了创新的基准框架。它们共同的趋势是超越单一的成功率指标,转向可扩展、多维度、面向能力的自动化评估,旨在更深刻地揭示现有智能体的能力边界和未来挑战。
在学习与训练范式上,两篇论文探索了如何让智能体获得更通用的核心能力。Training a Generally Curious Agent通过在合成数据上进行上下文强化学习,赋予智能体泛化的好奇心与探索策略。Cross-environment Cooperation则提出了一种全新的零样本协作训练方法,通过在海量多样化的环境中训练,而非依赖多样的伙伴,来培养智能体普适的协作规范,在与人类协作时表现出色。
在系统设计与治理层面,研究者们关注如何构建更高效、更安全的智能体系统。Multi-agent Architecture Search颠覆了传统“一招鲜”的多智能体系统设计思路,提出动态、按需、自动地从一个“架构超网”中生成最优的智能体组合。而立场论文AI Agents Need Authenticated Delegation则高屋建瓴地指出了智能体安全治理的紧迫性,倡导通过扩展现有成熟的Web协议,为智能体建立可认证、可审计的授权体系,为未来智能体的安全应用铺平道路。
这些工作共同勾勒出智能体领域从基础能力到应用实践、从技术创新到安全治理的完整图景,预示着一个更强大、更可靠、更智能的AI智能体时代的到来。
【1】虚拟智能体应用瓶颈何在?OmniBench:一个可扩展的多维基础能力基准
论文英文标题:
What Limits Virtual Agent Application? OmniBench: A Scalable Multi-Dimensional Benchmark for Essential Virtual Agent Capabilities
论文链接:
https://icml.cc/virtual/2025/poster/46463
论文中文摘要:
随着多模态大型语言模型(MLLM)的进步,基于MLLM的虚拟智能体已展现出卓越的性能。然而,现有基准测试面临着显著的局限性,包括任务复杂度不可控、大量手动标注导致场景有限,以及缺乏多维度评估。为应对这些挑战,我们引入了OmniBench,这是一个自生成、跨平台、基于图的基准测试框架,其自动化流程能通过子任务组合来合成复杂度可控的任务。为了在图结构上评估虚拟智能体的多样化能力,我们进一步提出了OmniEval,一个多维度评估框架,包括子任务级评估、基于图的度量标准,以及对10种能力的全面测试。我们合成的数据集包含20个场景下的3.6万个图结构化任务,达到了91%的人类接受率。在我们的图结构化数据上进行训练表明,与手动标注的数据相比,它能更有效地指导智能体。我们对各种开源和闭源模型进行了多维度评估,揭示了它们在各种能力上的表现,并为未来的发展铺平了道路。
核心图片:

文章推荐理由:
本文直击当前虚拟智能体评估的核心痛点:现有基准任务复杂度不可控、依赖高成本的人工标注且评估维度单一。为此,作者提出了OmniBench,一个极具创新性的解决方案。其亮点在于构建了一个自生成、基于图的自动化任务合成管线,能够低成本、大规模地生成复杂度可控(涵盖依赖、指令、知识、层次、分支五大维度)的高质量任务,极大地扩展了任务的多样性和规模(3.6万个任务)。更重要的是,它配套提出了多维度评估框架OmniEval,能够从10个细分能力维度对智能体进行全面“体检”,远超传统只关注最终任务成功率的评估方法。研究发现,即便是最强的GPT-4o,在处理复杂的图结构任务时也表现不佳,这为未来智能体的研究指明了具体的优化方向,例如提升规划能力和对任务意图的理解。该工作为智能体评估领域树立了新的标杆,其方法论和开源工具将极大地推动社区发展。
【2】立场论文:AI智能体需要可认证的授权委托
论文英文标题:
Position: AI Agents Need Authenticated Delegation
论文链接:
https://icml.cc/virtual/2025/poster/40172
论文中文摘要:
自主AI智能体的快速部署在授权、问责和访问控制等领域带来了紧迫挑战。这篇立场文件认为,对AI智能体进行可认证和可审计的权力委托,是减轻实际风险和释放智能体价值的关键组成部分。为支持这一论点,我们探讨了如何扩展现有的Web认证和授权协议,以及通用访问控制机制的自然语言接口,从而实现对AI智能体的安全认证委托。通过使用特定于智能体的凭证扩展OAuth 2.0和OpenID Connect,并利用自然语言权限到跨多种交互模式的稳健范围规则的透明转换,我们勾勒出如何实现认证委托,以建立清晰的问责链,同时保持与现有认证和Web基础设施的兼容性,从而实现即时兼容。这项工作有助于确保智能体AI系统只执行适当的操作。它主张将委托基础设施作为AI智能体治理的关键组成部分优先考虑,并为此提供了一个路线图。
核心图片:

文章推荐理由:
随着AI智能体逐渐从实验室走向现实世界,如何确保其行为安全、可控、可追溯,成为一个刻不容缓的议题。这篇立场论文精准地抓住了这一核心矛盾,前瞻性地指出“可认证的授权委托”是AI智能体安全治理的基石。文章的亮点在于没有凭空创造新协议,而是提出了一条务实且兼容的路径:扩展当前互联网上广泛应用的OAuth 2.0和OpenID Connect等成熟标准,为其增加智能体专用的凭证和权限范围规则。这意味着智能体在代表用户执行操作(如订票、购物)时,第三方服务可以清晰地验证其身份、来源(代表哪个人类用户)以及被授予的权限范围,从而建立起一条清晰、可审计的问责链。本文不仅深刻剖析了为何需要这种机制(如防止滥用、保护人类在线空间),还提供了具体的技术构想和路线图,为整个行业在构建可信AI生态系统方面提供了极具价值的指导。
【3】EmbodiedBench:面向视觉驱动具身智能体的综合基准测试
论文英文标题:
EmbodiedBench: Comprehensive Benchmarking Multi-modal Large Language Models for Vision-Driven Embodied Agents
论文链接:
https://icml.cc/virtual/2025/poster/45994
论文中文摘要:
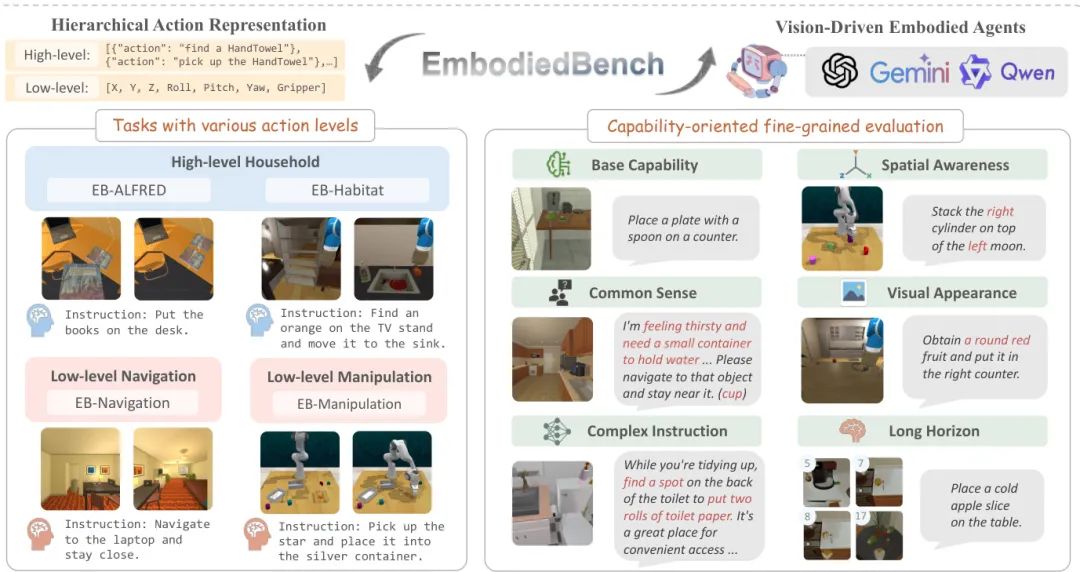
利用多模态大型语言模型(MLLM)创建具身智能体为解决现实世界任务提供了一条有前景的途径。尽管以语言为中心的具身智能体已获得广泛关注,但基于MLLM的具身智能体由于缺乏全面的评估框架仍未得到充分探索。为了弥合这一差距,我们引入了EMBODIEDBENCH,这是一个旨在评估视觉驱动具身智能体的广泛基准。EMBODIEDBENCH的特点包括:(1)在四个环境中设置了1128个多样化的测试任务,涵盖从高级语义任务(如家务)到涉及原子动作的低级任务(如导航和操控);(2)六个精心策划的子集,用于评估智能体的基本能力,如常识推理、复杂指令理解、空间意识、视觉感知和长期规划。通过广泛的实验,我们在EMBODIEDBENCH中评估了24个领先的专有和开源MLLM。我们的发现揭示:MLLM在高级任务上表现出色,但在低级操控任务上举步维艰,最好的模型GPT-4o平均得分仅为28.9%。EMBODIEDBENCH提供了一个多方面的标准化评估平台,不仅突出了现有挑战,也为推动基于MLLM的具身智能体发展提供了宝贵的见解。
核心图片:
文章推荐理由:
当我们将多模态大模型(MLLM)作为“大脑”放入机器人,它们在物理世界中的真实能力如何?本文通过构建EmbodiedBench给出了迄今最全面的答案。该基准的核心亮点在于其“分层”和“多维”的评估设计。首先,它同时涵盖了高级语义规划(如“把书放桌上”)和低级原子操控(如控制机械臂的平移旋转)任务,全面考察了智能体从“思考”到“执行”的全链路能力。其次,它精心设计了六大能力子集(如常识、空间感知、长程规划),能够精细化地诊断模型在不同认知维度上的优劣。通过对24个主流MLLM的广泛评测,文章得出了一个关键结论:当前模型擅长“高层规划”,却在“底层操控”上表现糟糕,这直接指明了从虚拟世界走向物理世界的最大技术鸿沟。EmbodiedBench的出现,为社区提供了一个标准化的“考场”,将有力地引导和加速视觉驱动的具身智能体研究。
【4】训练一个通用好奇的智能体
论文英文标题:
Training a Generally Curious Agent
论文链接:
https://icml.cc/virtual/2025/poster/45106
论文中文摘要:
高效的探索对于智能系统与环境的交互至关重要,但现有语言模型在需要战略性信息收集的场景中常常表现不佳。在本文中,我们提出了PAPRIKA,一种微调方法,使语言模型能够发展出不局限于特定环境的通用决策能力。通过在需要不同策略的各种任务的合成交互数据上进行训练,PAPRIKA教会模型在无需更多梯度更新的情况下,根据环境反馈在上下文中探索和调整其在新任务上的行为。实验结果表明,使用PAPRIKA微调的模型可以有效地将其学到的决策能力零样本迁移到完全未见过的任务中。与传统训练不同,我们方法的主要瓶颈在于采样有用的交互数据,而非模型更新。为了提高样本效率,我们提出了一种课程学习策略,优先从具有高学习潜力的任务中采样轨迹。这些结果为实现能够自主解决需要与外部世界互动的新型序列决策问题的AI系统,指明了一条有前景的道路。
核心图片:

文章推荐理由:
如何让大模型智能体像人一样,面对未知问题时懂得主动探索、收集信息,而非被动等待指令?本文提出的PAPRIKA框架为此提供了一个创新且可行的训练范式。其核心思想是,与其教模型解决某个特定任务,不如教它“学会如何解决问题”。亮点在于,它通过在大量多样化的合成决策任务(如猜词、扫雷、解谜等)上进行训练,让模型从成功的轨迹中学习通用的探索和决策策略。这种能力随后可以零样本迁移到全新的、从未见过的任务中,展现出强大的泛化性。这本质上是一种“上下文强化学习”,模型在与新环境的交互中动态调整策略,而非依赖额外的微调。此外,文章还提出了课程学习策略,优先训练“学习潜力大”的任务,有效提升了数据效率。这项工作为培养具有通用好奇心和自主解决问题能力的智能体开辟了新路径,是通向更高级人工智能的重要一步。
【5】通过智能体超级网络进行多智能体架构搜索
论文英文标题:
Multi-agent Architecture Search via Agentic Supernet
论文链接:
https://icml.cc/virtual/2025/poster/44335
论文中文摘要:
由大型语言模型(LLM)赋能的多智能体系统通过规范的协作和互动,扩展了单个智能体的认知边界,但构建这些系统通常需要耗费大量人力的手动设计。尽管已有方法可以自动化设计智能体工作流,但它们通常寻求找到一个静态、复杂、一刀切的系统,然而这无法根据每个查询的难度和领域动态分配推理资源。为了应对这一挑战,我们不再追求单一的智能体系统,而是优化一个“智能体超级网络”(agentic supernet),即一个概率性的、连续的智能体架构分布。我们引入了MaAS,一个自动化框架,它从该超级网络中采样依赖于查询的智能体系统,提供高质量的解决方案和量身定制的资源分配(如LLM调用次数、工具调用次数、Token成本)。在六个基准测试上的全面评估表明,MaAS(I)仅需现有手工设计或自动化多智能体系统6%~45%的推理成本,(II)性能超越它们0.54%~16.89%,并且(III)具有优越的跨数据集和跨LLM骨干的迁移能力。
核心图片:

文章推荐理由:
本文颠覆了当前自动化多智能体系统(MAS)设计的底层逻辑。传统方法致力于寻找一个固定的、最优的“超级智能体团队”来解决所有问题,但这往往导致系统臃肿、资源浪费,且无法适应不同任务。本文的核心创见是引入了“智能体超级网络”(Agentic Supernet)的概念,这是一个包含无数种可能智能体架构的概率分布空间。基于此,作者开发了MaAS框架,其最大亮点在于实现了“按需组队”:面对一个新任务(查询),MaAS能从超级网络中智能地采样出一个“恰到好处”的智能体系统——简单任务用精简团队,复杂任务用豪华阵容。这种动态、自适应的架构搜索不仅在性能上超越了现有SOTA方法,更惊人的是,它仅用6%到45%的推理成本就实现了这一目标。这项工作从“寻找最优解”转变为“优化解的分布”,为构建高效、经济、可扩展的AI智能体系统提供了全新的、更优越的范式。
【6】ITBench:在多样化的真实世界IT自动化任务中评估AI智能体
论文英文标题:
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
论文链接:
https://icml.cc/virtual/2025/poster/44303
论文中文摘要:
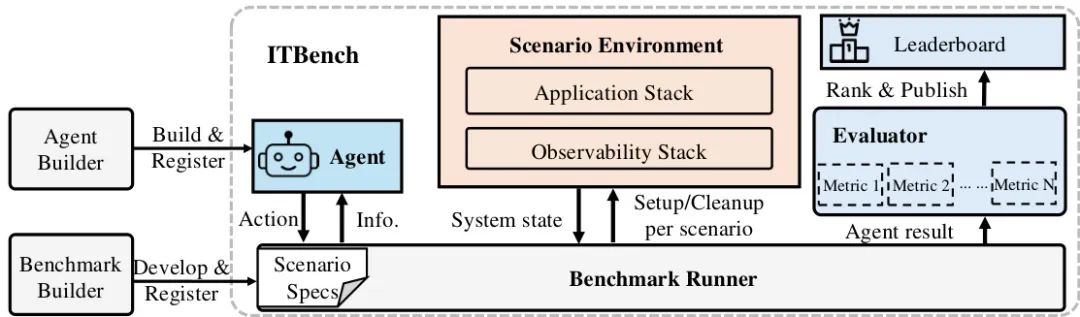
实现使用AI智能体自动化关键IT任务的愿景,取决于衡量和理解所提出解决方案有效性的能力。我们引入了ITBench,一个为评估AI智能体解决真实世界IT自动化任务提供系统性方法的框架。我们的初始版本针对三个关键领域:网站可靠性工程(SRE)、合规与安全运营(CISO)以及财务运营(FinOps)。该设计使AI研究人员能够通过一键式工作流和可解释的指标来理解AI智能体在IT自动化领域的挑战和机遇。ITBench包含了初步的102个真实世界场景,并可通过社区贡献轻松扩展。我们的结果显示,由最先进模型驱动的智能体仅解决了11.4%的SRE场景、25.2%的CISO场景和25.8%的FinOps场景(不包括异常检测)。对于FinOps特定的异常检测(AD)场景,AI智能体实现了0.35的F1分数。我们期望ITBench能成为推动正确、安全、快速的AI驱动IT自动化的关键力量。
核心图片:
文章推荐理由:
AI智能体在IT运维领域的应用潜力巨大,但如何衡量其在真实、复杂场景下的“实战”能力,一直是个难题。本文提出的ITBench是该领域的首个综合性、真实世界基准,具有重要的实践价值。其核心亮点在于高度贴近产业现实:它不使用玩具问题,而是针对IT行业三大核心角色(SRE、CISO、FinOps)构建了102个源自真实生产事故、行业安全标准(CIS)和财务实践的自动化场景。这使得对智能体的评估不再是纸上谈兵。其次,ITBench提供了一套包含环境部署、智能体运行、安全护栏和自动化评估的完整框架,大大降低了研究门槛。初步的评测结果(SOTA模型解决率仅为10%-25%)揭示了当前AI智能体在IT自动化领域面临的巨大挑战,也凸显了ITBench作为“试金石”的价值。该工作的发布,有望像SWE-bench对软件工程领域一样,极大促进AI在IT运维领域的落地和发展。
【7】跨环境合作为零样本多智能体协调赋能
论文英文标题:
Cross-environment Cooperation Enables Zero-shot Multi-agent Coordination
论文链接:
https://icml.cc/virtual/2025/poster/43490
论文中文摘要:
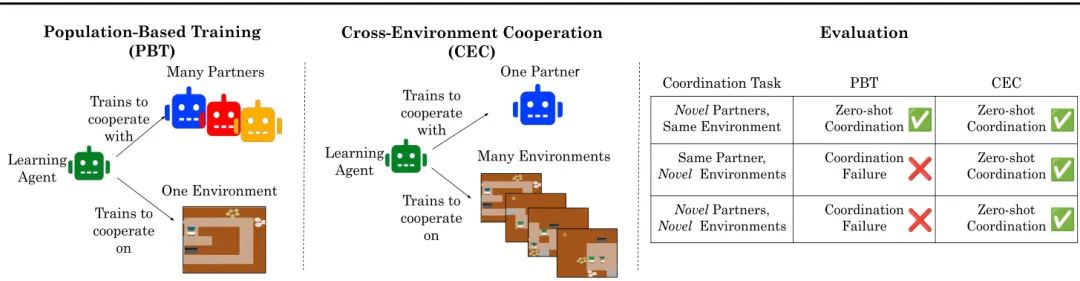
零样本协调(Zero-shot coordination, ZSC),即在合作任务中适应新伙伴的能力,是实现与人类兼容的AI的关键组成部分。虽然先前的工作侧重于训练智能体在单一任务上合作,但这些专用模型无法泛化到新的、即便是高度相似的任务中。在这里,我们研究了在具有单个伙伴的环境分布上进行强化学习,如何能够学习到通用的合作技能,从而支持与许多新伙伴在许多新问题上的ZSC。我们引入了两个基于Jax的程序化生成器,可创建数十亿个可解的协调挑战。我们开发了一种名为“跨环境合作”(Cross-Environment Cooperation, CEC)的新范式,并表明在与真人合作时,它在数量和质量上均优于竞争性基准。我们的发现表明,学习在许多独特场景中进行协作,能鼓励智能体发展出通用的行为规范,而这些规范在与不同伙伴的合作中证明是有效的。
核心图片:
文章推荐理由:
如何让AI智能体在无需事先磨合的情况下,能与陌生的人类或其他AI伙伴默契协作?传统方法(如PBT)认为需要让智能体在训练时见过“足够多”的不同伙伴。本文提出了一个反直觉但更有效的新范式——跨环境合作(CEC)。其核心亮点在于,它认为协作能力的泛化性主要来源于对多样化“任务”的理解,而非对多样化“伙伴”的适应。文章通过一个极具创意的训练设置来验证这一点:只让智能体和同一个伙伴进行训练,但训练场景是程序化生成的、数以亿计的《胡闹厨房》关卡。实验结果惊人地发现,这种在海量不同环境中“锤炼”出的智能体,在面对新伙伴(包括真人玩家)和新环境时,其协作能力远超在单一环境中与大量不同伙伴训练的传统模型。这项工作深刻地揭示了通用协作规范的形成机制,为开发能与人类进行流畅、即时协作的AI助手提供了全新的、更高效的思路。
-- 完 --
机智流推荐阅读:
1. AI时代,你的速度决定了你的高度:吴恩达YC创业学校万字干货
2. ICCV25 | AI终于分清照片中的前景和背景了!探索南开DenseVLM在密集预测中的区域-语言对齐策略
3. 发个福利,可以免费领WAIC2025(世界人工智能大会·上海)单日门票
4. ICML 2025最佳论文花落谁家?120篇Oral前沿一网打尽!
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
在「机智流」公众号后台回复下方标红内容即可加入对应群聊:
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群










