
从语言理解到图像识别,从通用问答到代码生成,大模型正在全面刷新AI能力的边界。近年来,越来越多研究者尝试将这些模型嵌入机器人系统,希望赋予它们“听得懂人话、看得懂场景、动得了身子”的能力。
这类尝试已在多个视觉-语言-动作(VLA)系统中初见成效:
SayCan 和 Code-as-Policies 让机器人能将自然语言翻译为操作序列,完成任务执行;
LM-Nav 和 ZSON 则让机器人能够理解“去那个红色杯子旁边看看”的指令,并结合视觉模型完成自主导航与反馈。
但这些系统的“聪明”,大多依赖 GPT-4、PaLM、LLaMA-70B 等大模型,通过云服务完成语言理解与任务规划。
换句话说,它们跑得动,是因为背后有人“推着走”——有结构化的环境、稳定的网络连接、远程的高性能算力。
一旦走出实验室,情况立刻变了样:
“
室外语义混乱,模型误判频发——机器人可能遇到没见过的障碍物,或者地图不全,不知道该往哪走;
机器人本体算力有限,大模型根本“跑不动”——野外机器人可能只能用小型芯片(如无人机上的 Jetson Orin NX)
网络中断,规划瞬间失效——机器人连不上服务器,无法获取模型指令
这就是现实中的“落差”:大模型确实让机器人更聪明,但前提是你得“带得动”、也“连得上”。
类似 DeepSeek 等开源大模型因支持本地部署而一度爆火,但真正尝试了的人都知道,要把它部署到机器人身上远非易事。不仅算力是一道门槛,模型裁剪、推理优化、接口对接等问题也层出不穷。更不用说在执行任务时还要保证响应速度、功耗可控、通信弹性。
因此,大模型本地化,不只是个“能不能”的问题,更是机器人能否真正走进现实世界的“必要条件”。

▲图1|本地部署了“满血”Deepseek的主机即便开出“天价”售卖,也卖到断货,可见当前市场对于本地化大模型的需求之大©️【深蓝具身智能】编译

本地部署,不只是“小模型”的事
一提到大模型本地部署,很多人的第一反应是:把大模型“压缩一下”,变成“小模型”放进机器人不就行了?
但现实远比这复杂。
真正让大模型在机器人上“跑得动”、“跑得对”,需要的是一整套系统性的设计思路,而不仅仅是模型瘦身。

▲表1|大模型本地化与非本地化性能对比
这篇文章我们就来盘点一下当前研究中常用的三种部署路径,每一种都揭示了“本地化”的深层挑战与折中方案。
蒸馏:把“聪明”压缩进机器人的算力预算
大模型之所以“跑不动”,首先是因为它“太大了”。
GPT-4、LLaMA-70B 这类模型通常需要几十 GB 显存,根本无法直接部署到资源有限的机器人平台上。
为了解决这个问题,可以采用模型蒸馏(Distillation) 的方法。
通俗地说,就是让一个大模型(老师)先完成任务、展示思路,再训练一个小模型(学生)学会模仿老师的行为,从而达到“用小模型做大事情”的目的。
在Deepseek官网经常因为访问量崩溃的那段时间,许多网站就是采用了蒸馏的方式,提供对于Deepseek的快速访问,但是挂出“满血Deepseek”的牌子,来为自身吸引流量,如果有使用过这些网站的小伙伴一定能发现,这些蒸馏版本的Deepseek与官网的“满血版”相比,还是存在一些差异的。

▲图2|模型蒸馏常见架构©️【深蓝具身智能】编译
放到具体的工作中,可以使用 GPT-4o 作为“专家规划器”,生成多轮任务推理和计划数据,并使用 LoRA(Low-Rank Adaptation) 技术微调一个 LLaMA 3.2B 小模型,使其能运行在无人机的本地计算平台上。
这里的LoRA我们也着重介绍一下,这是大模型本地化的关键:
在大语言模型(如 LLaMA、GPT)中,参数量非常大,通常动辄几十亿甚至上百亿个。我们在微调这些模型时,如果直接修改全部参数,不仅计算成本高、内存占用大,而且对于边缘设备来说根本跑不动。
这时候,LoRA 提供了一种巧妙的解决办法——
只在模型某些层中添加一小块“适配器”(adapter)结构,专门用来学习新任务的变化,而不动原始大模型的核心参数。
更具体地说,LoRA 会:
将一个原本高维的参数更新矩阵,用两个低维矩阵(也就是“低秩”)相乘来表示;
这样就把需要学习的参数量从“几亿”压缩到了“几百万”甚至更少;
原始大模型的参数保持冻结(不变),只更新这两个插入的小矩阵。
这两个矩阵就是所谓的 “低秩适配器”,它们像“外挂补丁”一样插在大模型里面,只学特定任务相关的内容。

▲图3|LoRA与一般大模型调整对比©️【深蓝具身智能】编译
要点总结:
蒸馏不是“缩小版GPT”,而是一种有选择地“转移经验”的方法,提炼出与任务最相关的知识,以适应受限硬件环境。
模块化架构:让大模型专心“想”,让小模块负责“做”
即便成功压缩了模型,单靠一个模型包打天下仍不现实。
因此,一种做法是采用模块化闭环的系统架构,将大模型从底层控制中抽离出来,仅专注于高层决策与语义规划,这种做法即发挥了大模型强大通用知识的能力,也保留了传统ruler-based方法的快速响应能力,同时降低了对大模型算力的需求,可以部署相对来说较低参数量的大模型。
这一思想常被用在当前的一些VLN架构中。

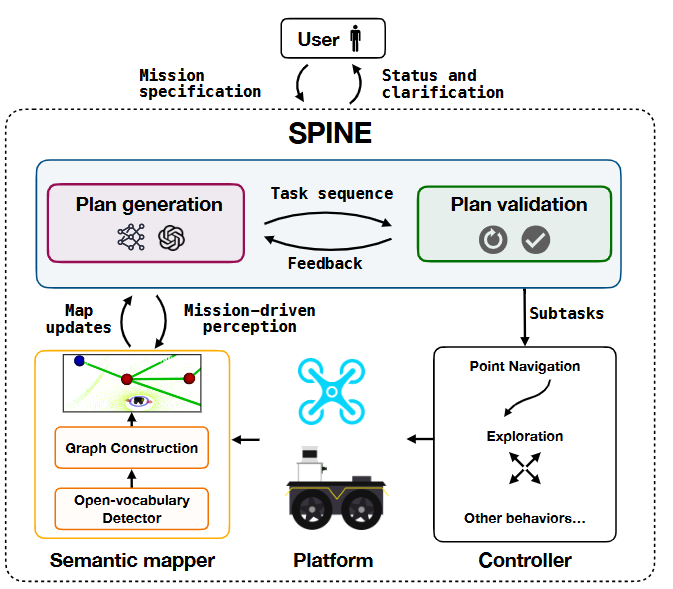
▲图4|一种体现了模块化思想的VLN架构:采用大模型来处理自然语言指令和环境信息,但机器人本体的运动和路径规划仍然由控制器来执行和完成©️【深蓝具身智能】编译
具体做法:
大模型负责解析自然语言任务、推理目标地点与行为序列,输出一系列“函数调用”(如 goto(park)、explore(region));这些调用由传统控制栈中的子模块执行,如路径规划、障碍避让、地图更新等。
同时,系统一般会内置了一套计划验证机制,实时评估 LLM 生成内容是否可行(如目标是否可达,路径是否可行),并反馈修正。
这一设计在实际任务中展现出极强的鲁棒性——
哪怕大模型出现错误判断,也不会直接“误导”机器人做出错误行为,因为每一步都会被控制模块审查。
要点总结:
模块化不是“分工合作”那么简单,它提供了一个语义到动作之间的 “防抖”结构,是将 LLM 纳入机器人系统的关键。
云边协同:不是完全断开,而是“断了也能跑”
虽然本地模型已具备一定能力,但一些任务仍需要调用远程大模型支持,尤其是在任务链条较长、语言指令不清晰时。
为此,论文²中采用了边缘+云协同架构:机器人本体运行轻量模型,云端保留 GPT-4o 等大模型作为“后援”,两者通过 mesh 网络持续同步。
更关键的是,系统并不依赖通信维持“生命线”。一旦网络中断,机器人依然可以在已有任务指令下独立执行,并在恢复通信后同步状态,继续任务。
这种设计兼顾了大模型的能力优势和现实世界中的通信不可控性。
▲图5|云地协同思想的大模型本地化架构©️【深蓝具身智能】编译
但是这种方法的通信链路部署具备相当的工程复杂性(如中继节点布设、5G与卫星备份等),侧面反映出完全依赖远程服务在野外部署中是不可持续的,只能够作为一个暂时的解决方案。
要点总结:
本地部署≠拒绝联网,关键是设计出“网络好时很聪明,断网时也能干活”的系统。

总结
将大模型集成到机器人中,曾被认为是打开“通用智能”大门的一把钥匙。然而,理想中的能力必须面对现实中的环境——缺图、弱网、算力紧张、语义模糊……
这些问题不是模型能力所能一一克服,而是系统能力必须共同支撑。
本文梳理了当前主流的大模型本地部署路径:
通过蒸馏压缩提取关键能力
通过模块化结构实现安全控制
通过云边协同兼顾灵活性与稳定性
这些方法共同构成了“让大模型真正走上机器人”的现实落地方案。
而这些探索的背后,其实正是具身智能所面临的终极挑战:不只是“看得懂”和“听得清”,而是在真实世界中感知、理解、行动,并自主应对复杂变化的能力。
这一步,不能只靠大脑(模型),还必须让大脑“接地气”——也就是在资源受限、通信不稳定、知识不完整的环境中依然能完成任务。
从这个意义上讲,大模型的本地化,不只是性能问题、工程问题,更是具身智能能否真正走向应用的试金石。
你认为未来机器人在实际环境中部署大模型,最难的挑战是什么?
编辑|阿豹
审编|具身君
参考文献
1. Deploying Foundation Model-Enabled Air and Ground Robots in the Field: Challenges and Opportunities
2. Deploying Foundation Model Powered Agent Services: A Survey
 【深蓝具身智能读者群】-参观机器人:
【深蓝具身智能读者群】-参观机器人:

我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇



点击❤收藏并推荐本文










