本文收录8月26日Hugging Face Daily Paper,解读由 Intern-S1、Qwen3 等 AI 生成可能有误。
在正式介绍 HF 论文前,插播一下 PaperScope 论文详细页已经支持 PDF 预览了,在 P 站能够解决大部分的论文阅读和论文问答需求了!!!
(1) TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling
论文来源:hf
Hugging Face 投票数:57
论文链接:
https://hf.co/papers/2508.17445
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17445
(2) CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics

论文简介:
由上海人工智能实验室等机构提出了CMPhysBench,该工作构建了一个包含520道研究生水平问题的基准测试集,旨在评估大语言模型在凝聚态物理领域的推理能力。CMPhysBench覆盖磁学、超导、强关联体系等核心子领域,强调开放式计算题型,要求模型独立生成完整解题步骤。为实现细粒度评估,研究团队提出Scalable Expression Edit Distance(SEED)指标,通过树状结构表达式匹配支持多类型答案的非二元评分,显著提升评估准确性。实验显示当前最优模型Grok-4在SEED评分中仅得36分,准确率28%,凸显大语言模型在前沿物理领域的显著能力差距。该基准测试的代码与数据已开源,为推动领域发展提供了重要工具。
论文来源:hf
Hugging Face 投票数:42
论文链接:
https://hf.co/papers/2508.18124
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18124
(3) VibeVoice Technical Report

论文简介:
由微软研究院等机构提出了VIBEVOICE,该工作设计了一种新型语音合成模型,通过引入next-token diffusion框架和高效连续语音tokenizer,实现了长达90分钟、支持最多4名说话人的高质量对话音频生成。核心创新在于开发了压缩率达3200倍(7.5Hz帧率)的因果语音tokenizer,在保持音质的同时将数据压缩效率提升80倍,并采用轻量级扩散头与大语言模型(LLM)结合的架构,通过混合语音表征建模和流式生成机制,突破了传统TTS在长序列多说话人场景下的合成瓶颈。
VIBEVOICE采用双tokenizer设计:基于σ-VAE的声学tokenizer(340M参数)实现高保真音频重建,其7.5Hz帧率在LibriTTS测试集上取得3.068 PESQ和4.181 UTMOS的领先指标;语义tokenizer则通过ASR任务学习文本对齐特征。模型将语音特征与文本脚本拼接输入LLM(Qwen2.5 1.5B/7B),由LLM预测隐状态并驱动扩散头逐token预测声学VAE特征,最终通过解码器恢复音频。该架构在保持简洁性的同时,通过课程学习策略支持65k上下文窗口训练。
实验显示,VIBEVOICE-7B在对话生成任务中主观评分(Realism 3.71/MOS)和客观指标(WER 1.29%)均超越Elevenlabs、Gemini等竞品,在SEED短句测试集上也保持竞争力(test-zh CER 1.16%)。模型支持跨语言合成且计算效率显著提升,但存在非英语内容输出不稳定、无法生成重叠语音等局限。研究强调该技术需谨慎用于研究场景,避免深度伪造等伦理风险。
论文来源:hf
Hugging Face 投票数:37
论文链接:
https://hf.co/papers/2508.19205
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19205
(4) VoxHammer: Training-Free Precise and Coherent 3D Editing in Native 3D Space

论文简介:
由北京航空航天大学、中国人民大学、清华大学和腾讯混元项目组提出了VoxHammer,该工作提出了一种无需训练的3D本地编辑框架,通过在原生3D空间中进行精确且连贯的编辑来实现高质量3D资产修改。该方法基于预训练的结构化3D潜在扩散模型,采用两阶段策略:首先通过精确的3D反转预测将输入3D模型映射到噪声空间并缓存潜码与键值对特征,随后在去噪编辑阶段通过替换未编辑区域的潜码和注意力键值对,实现几何结构与纹理细节的高保真保持。为解决现有数据集缺乏编辑区域标注的问题,研究团队构建了包含数百个样本的Edit3D-Bench基准数据集,通过定量实验和用户研究验证了VoxHammer在未编辑区域一致性(Chamfer距离降低40%以上)、整体质量(FID下降50%)和条件对齐度(CLIP-T提升10%)等方面均显著优于现有方法。该方法无需额外训练即可实现对网格、NeRF和高斯溅射等3D表示的局部编辑,在游戏开发和机器人交互等领域具有重要应用价值,同时为生成式3D建模的上下文学习奠定了数据基础。
论文来源:hf
Hugging Face 投票数:28
论文链接:
https://hf.co/papers/2508.19247
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19247
(5) OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation

论文简介:
由字节跳动智能创作实验室等机构提出了OmniHuman-1.5,该工作通过认知模拟为虚拟角色注入主动思维,构建了首个同时模拟人类"系统1"(快速反应)和"系统2"(深度推理)的认知框架。核心贡献体现在两个关键技术:1)利用多模态大语言模型生成结构化文本条件,通过链式推理提供语义级动作指导,突破传统方法仅依赖音频节奏的局限;2)创新多模态Diffusion Transformer架构,采用伪最后一帧策略解决身份图像与动态内容的模态冲突,实现音频、文本、视频三模态的深度融合。实验表明该方法在唇同步准确率、视频质量、动作自然度等指标上全面领先,并展现出卓越的语义一致性。特别在复杂多场景测试中,模型成功生成符合逻辑的多角色互动和非人类角色动作,验证了框架的泛化能力。这项研究开创性地将认知科学理论引入虚拟人生成领域,为构建具有真实行为逻辑的数字角色提供了全新范式。
论文来源:hf
Hugging Face 投票数:25
论文链接:
https://hf.co/papers/2508.19209
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19209
(6) Spacer: Towards Engineered Scientific Inspiration
论文来源:hf
Hugging Face 投票数:24
论文链接:
https://hf.co/papers/2508.17661
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17661
(7) UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning

论文简介:
由字节跳动等机构提出了UltraMemV2,该工作通过五项核心改进实现了内存层架构与8专家MoE模型的性能持平,同时保持低内存访问优势。研究团队通过在每个Transformer块中集成内存层、简化值扩展为单线性投影、采用PEER的FFN值处理、优化参数初始化策略以及调整内存与FFN计算比例,使模型在同等计算量下实现长上下文任务的显著提升。实验表明,UltraMemV2在长上下文记忆任务上提升1.6分,多轮记忆任务提升6.2分,在上下文学习任务提升7.9分,验证了其在内存密集型任务中的优势。通过扩展至1200亿参数规模的实验,研究发现激活密度(top-m值)对性能的影响大于总稀疏参数数量,为内存层架构设计提供了关键指导。该工作首次实现了内存层架构与顶尖MoE模型的性能对标,为高效稀疏计算提供了新范式,但同时也发现其在训练初期效果较弱、依赖高质量数据等局限性。
论文来源:hf
Hugging Face 投票数:21
论文链接:
https://hf.co/papers/2508.18756
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18756
(8) Pixie: Fast and Generalizable Supervised Learning of 3D Physics from Pixels

论文简介:
由宾夕法尼亚大学和MIT等机构提出了Pixie,该工作提出了一种从视觉特征中快速预测3D场景物理属性的监督学习框架。Pixie通过训练神经网络直接从3D视觉特征预测离散材质类型(如橡胶)和连续物理参数(如杨氏模量、泊松比、密度),结合高斯泼溅模型和物质点法(MPM)求解器实现逼真的物理模拟。研究团队构建了包含1624个3D资产和物理标注的PixieVerse数据集,采用CLIP视觉特征蒸馏和3D U-Net网络实现每场景2秒内的快速推断,相比传统优化方法速度提升3个数量级,且在视觉语言模型评估中实现1.46-4.39倍的现实感提升。该方法通过预训练视觉特征实现从合成数据到真实场景的零样本迁移,成功预测真实物体的物理属性并生成符合物理规律的动画效果,为虚拟世界构建和机器人仿真提供了高效解决方案。
论文来源:hf
Hugging Face 投票数:17
论文链接:
https://hf.co/papers/2508.17437
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17437
(9) CineScale: Free Lunch in High-Resolution Cinematic Visual Generation

论文简介:
由Nanyang Technological University、Netflix Eyeline Studios等机构提出了CineScale,该工作提出了一种新的推理范式,通过多尺度融合和频率域处理技术,首次实现预训练扩散模型在8K图像和4K视频生成上的突破性效果。研究针对扩散模型在超分辨率生成时出现的重复模式和质量退化问题,设计了定制化的自级联上采样、受限膨胀卷积和尺度融合模块,有效解决了UNet架构下的局部重复问题。同时通过NTK-RoPE位置编码和注意力缩放技术,将方法扩展至DiT架构,在仅需少量LoRA微调的情况下,成功生成4K分辨率视频。实验表明,该方法在图像生成中达到FID 44.723(2048²)和49.796(4096²)的最优指标,视频生成在FVD、动态程度等指标上全面领先基线方法。值得注意的是,该方法支持灵活的局部语义编辑和动态程度控制,用户研究显示其在图像质量、结构合理性等维度获得70%以上的用户偏好。最终实现了在保持预训练模型参数不变的前提下,将图像生成分辨率提升64倍(8K)、视频生成分辨率提升9倍(4K)的技术突破。
论文来源:hf
Hugging Face 投票数:14
论文链接:
https://hf.co/papers/2508.15774
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15774
(10) Autoregressive Universal Video Segmentation Model

论文简介:
由NVIDIA、延世大学、CMU和台湾大学等机构提出了Autoregressive Universal Video Segmentation Model(AUSM),该工作通过自回归建模统一了提示性与非提示性视频分割任务,实现了单架构处理多场景需求。AUSM借鉴语言模型的序列预测思想,将视频分割转化为逐帧掩码预测问题,通过History Marker和History Compressor模块实现历史信息的细粒度保留与时空压缩,在DAVIS、YouTube-VOS等7个基准测试中超越现有通用模型,同时支持16帧序列下2.5倍的训练加速。
核心创新点在于:1)提出视频分割的自回归统一框架,通过调整初始化策略兼容提示性(如VOS)与非提示性(如VIS)任务;2)History Marker模块采用Token Mark技术将实例掩码解构为空间特征,避免传统向量化带来的细节丢失;3)History Compressor结合Mamba和自注意力机制,将时空信息压缩为固定维度状态,实现任意长度视频的恒定内存推理;4)并行训练架构突破传统逐帧迭代模式,通过预处理构建跨帧监督信号,在16帧序列训练中展现2.5倍速度提升。
实验表明,AUSM在保持单模型架构的前提下,Swim-B版本在DAVIS17(81.6)、MOSE(62.1)、YouTube-VIS21(58.6)等数据集上全面超越UniVS等通用模型,尤其在复杂遮挡场景OVIS数据集达到45.5AP。通过伪视频预训练、多源短片段训练到长片段适配的三阶段策略,模型在16帧长序列训练中对MOSE和OVIS的性能提升分别达4.52和5.2AP。该工作验证了自回归建模在视频理解领域的有效性,为构建统一视频感知模型提供了新范式。
论文来源:hf
Hugging Face 投票数:11
论文链接:
https://hf.co/papers/2508.19242
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19242
(11) DrugReasoner: Interpretable Drug Approval Prediction with a Reasoning-augmented Language Model

论文简介:
由伊朗伊斯法罕医科大学联合伊斯法罕神经科学研究中心及伊斯法罕理工大学提出了DrugReasoner,该工作基于LLaMA架构开发了可解释的药物审批预测模型,通过组相对策略优化(GRPO)微调并融合链式推理(CoT)机制,实现小分子化合物审批概率预测及决策逻辑可视化。DrugReasoner创新性地整合分子描述符与结构相似化合物的对比推理,输入候选分子特征后,模型同步输出审批预测标签、置信度评分及分步推理依据。在2255对已批准/未批准分子数据集上训练后,模型在验证集取得0.732 AUC和0.729 F1值,测试集保持0.725 AUC和0.718 F1值,显著优于逻辑回归、SVM、KNN等传统基线模型,并与XGBoost性能相当。在ChemAP研究使用的外部独立数据集(17批准/8未批准药物)上,DrugReasoner以0.728 AUC和0.774 F1值超越ChemAP(0.64 AUC)及所有基线模型,同时保持0.857高精度和0.720平衡准确率。该模型通过分子特征而非SMILES直接输入的设计规避数据泄露风险,采用GRPO强化学习框架优化多目标奖励函数(含预测准确性、格式合规性、可解释性及置信度校准),在4-bit量化和LoRA适配下完成8B参数模型训练。研究证实推理增强型大语言模型在药物审批预测中兼具预测效能与决策透明度优势,为早期药物研发投资决策提供新型AI工具。
论文来源:hf
Hugging Face 投票数:10
论文链接:
https://hf.co/papers/2508.18579
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18579
(12) Wan-S2V: Audio-Driven Cinematic Video Generation

论文简介:
由HumanAIGC Team Tongyi Lab, Alibaba提出了Wan-S2V,该工作通过结合文本引导的全局运动控制与音频驱动的细节控制,在复杂影视场景中实现更具表现力和一致性的角色动画生成。针对现有音频驱动模型在多角色交互、真实肢体动作和动态镜头控制等场景中的局限性,研究团队基于Wan文本到视频生成框架构建了支持长视频生成的音频驱动模型。核心创新包括:1)构建包含影视级数据的混合数据集,通过精细化标注与多维度质量筛选提升数据有效性;2)采用FSDP与上下文并行的混合训练策略,实现14B参数模型的高效训练;3)提出基于FramePack的运动帧压缩方法,在降低计算成本的同时增强长视频时空一致性;4)设计分阶段训练流程,在语音视频预训练基础上进行影视数据微调,平衡文本控制与音频同步能力。实验显示,该方法在FID、FVD等指标上优于Hunyuan-Avatar、Omnihuman等SOTA模型,尤其在动态场景保持、多角色交互和长时一致性方面表现突出。研究还验证了模型在影视级长视频生成、精确唇同步编辑等场景的应用潜力,为复杂视听内容创作提供了新的技术路径。
论文来源:hf
Hugging Face 投票数:10
论文链接:
https://hf.co/papers/2508.18621
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18621
(13) ReportBench: Evaluating Deep Research Agents via Academic Survey Tasks

论文简介:
由 ByteDance 等机构提出了 ReportBench,该工作通过构建系统化评估框架,针对大语言模型生成的研究报告内容质量进行多维度评测。研究聚焦两个核心维度:引用文献的质量与相关性,以及报告陈述的忠实性与真实性。通过逆向提示工程将 arXiv 高质量综述论文转化为领域特定提示,形成包含 100 个学术调研任务的评估语料库,并开发自动化评估框架实现三重验证:基于引用文献的语义一致性匹配、非引用陈述的多模型投票验证,以及引用覆盖率与陈述事实性的量化分析。实验表明,商业级研究代理(如 OpenAI Deep Research 和 Google Gemini)在内容覆盖和事实校准方面显著优于基础模型,但存在过度引用、引用幻觉和陈述偏差等问题。该基准通过可复现的数据构建流程和模块化评估体系,为学术调研类 AI 系统的可靠性监测提供了标准化工具,相关代码与数据已开源。
论文来源:hf
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.15804
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15804
(14) FastMesh:Efficient Artistic Mesh Generation via Component Decoupling
论文来源:hf
Hugging Face 投票数:8
论文链接:
https://hf.co/papers/2508.19188
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19188
(15) ThinkDial: An Open Recipe for Controlling Reasoning Effort in Large Language Models
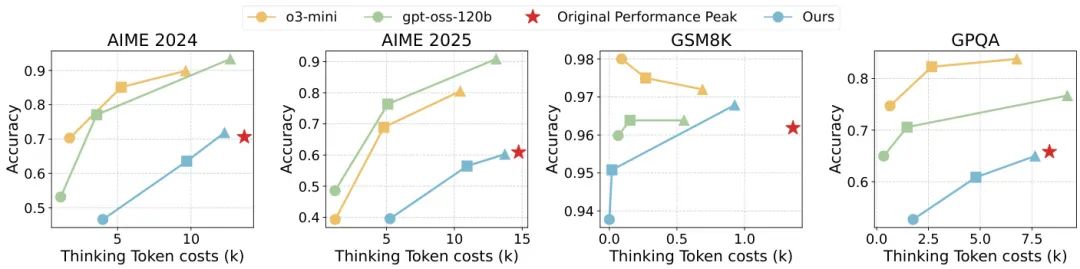
论文简介:
由 ByteDance Seed、复旦大学、上海交通大学和清华大学等机构提出了 ThinkDial,该工作首次实现了开源框架下类似 OpenAI gpt-oss 系列的可控推理能力。核心贡献在于构建了一个端到端训练范式,通过预算模式监督微调(Budget-Mode SFT)和两阶段预算感知强化学习(RL),使模型能够无缝切换三种推理模式:High 模式保持完整推理能力,Medium 模式减少 50% token 且性能下降 <10%,Low 模式减少 75% token 且性能下降 <15%。技术上,SFT 阶段通过构建多模式训练数据建立稳定的输出分布,RL 阶段采用自适应奖励塑形策略,针对不同模式设计响应长度奖励,并引入泄漏惩罚(Leak Penalty)防止推理内容溢出到答案部分。实验在数学推理基准(AIME、GSM8K)和跨领域任务(GPQA)上验证,ACT 评分显示模型在保持性能阈值的同时实现阶梯式 token 减少,且具备跨任务泛化能力。对比实验表明,该方法显著优于直接截断或无模式微调的基线,成功复现了闭源系统的可控推理曲线,为开源社区提供了首个可复现的离散推理控制方案。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.18773
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18773
(16) Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks

论文简介:
由东京工业大学等机构提出了Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks,该工作系统研究了MoE语言模型稀疏性对推理任务的影响。研究发现:在固定计算预算下,增加专家数量虽能降低预训练损失,但推理任务(如GSM8K数学题)的准确率会在参数规模超过阈值后出现明显下降,而记忆类任务(如TriviaQA)则持续提升。实验通过控制变量法验证了top-k路由策略本身对推理性能影响有限,关键在于活跃参数量与总参数量的平衡。当活跃参数量较高时,反而需要降低稀疏度(提高模型密度)才能获得最佳推理表现。有趣的是,测试时增加采样次数(Self-Consistency)或强化学习微调(GRPO)等后处理手段,并不能消除这种由架构稀疏性导致的性能下降。研究还揭示了tokens per parameter(TPP)对任务的敏感性:记忆任务偏好低TPP(更多参数),而推理任务存在约20的最优TPP值。代码生成任务(HumanEval)也表现出与数学推理类似的稀疏性敏感特征。这些发现挑战了"专家越多越好"的传统认知,表明在MoE架构中,推理能力的提升需要更精细的稀疏度控制,尤其在高计算预算下需转向更密集的专家配置。相关代码和模型已开源,为后续MoE架构设计提供了重要参考。
论文来源:hf
Hugging Face 投票数:6
论文链接:
https://hf.co/papers/2508.18672
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18672
(17) MovieCORE: COgnitive REasoning in Movies
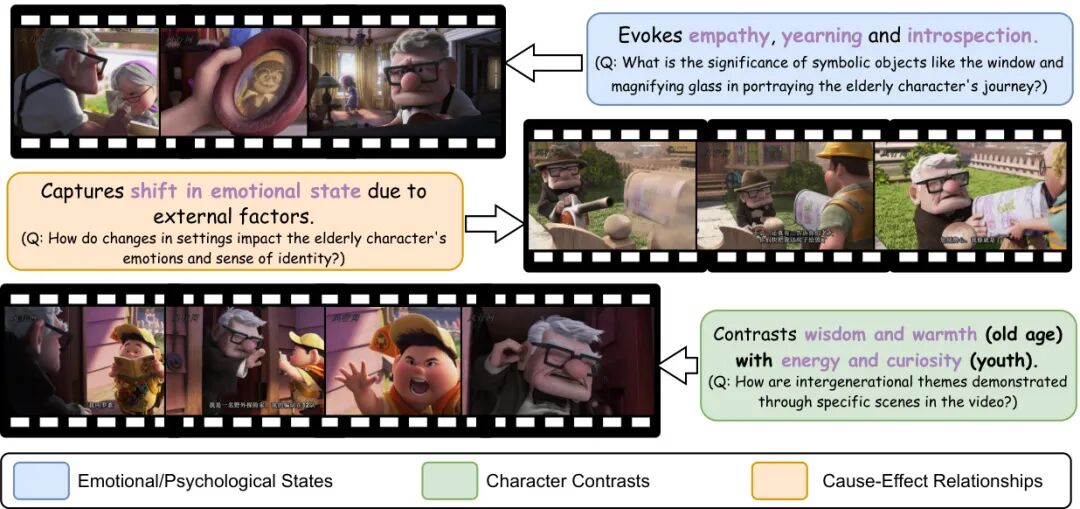
论文简介:
由台湾大学、NVIDIA、清华大学、政治大学等机构提出了MovieCORE,该工作构建了一个面向电影深层认知理解的视频问答数据集,通过多智能体协作生成高阶思维问题,并提出ACE模块提升现有模型推理能力,推动视频理解向人类级叙事分析迈进。
MovieCORE数据集包含986个电影片段及其对应的4930个问答对,聚焦于角色心理、情感共鸣和因果推理等深层认知维度。研究团队创新性地采用多智能体协作的标注流程:首先利用MiniCPM-v2.6提取视频上下文,再通过Critique Agent协调VQA专家、怀疑论研究者、侦探和元评审等AI代理进行多轮讨论,最终生成平均句法复杂度达5.88、认知层级达4.9(Bloom分类)的高质量问答对,其中99.2%的问题属于高阶认知范畴。
针对现有VLM模型在深层推理上的不足,团队提出ACE(Agentic Choice Enhancement)插件,在推理阶段通过轻量级语言模型(如Llama-3.2-1B)对候选答案进行二次筛选,使InstructBLIP等模型在MovieCORE上的综合评分提升25%。实验表明,当前主流模型在MovieCORE上表现显著低于专为表层理解设计的MovieChat-1k数据集,即使经过全监督训练,最优模型HERMES的深度推理得分仅3.52(满分5),凸显现有技术在叙事理解上的局限性。
该工作通过构建认知挑战基准和多智能体协作范式,为视频理解领域开辟了系统2思维研究的新方向,相关数据集、代码和评估框架已开源。
论文来源:hf
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.19026
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19026
(18) ObjFiller-3D: Consistent Multi-view 3D Inpainting via Video Diffusion Models

论文简介:
由南京大学等机构提出了ObjFiller-3D,该工作提出了一种基于视频扩散模型的多视角一致3D补全方法,通过适配视频编辑模型解决3D场景补全中的跨视角不一致问题。现有方法依赖多视角2D图像补全,但存在纹理模糊和空间不连续等缺陷。ObjFiller-3D创新性地将视频扩散模型VACE引入3D补全任务,通过分析3D与视频数据的表征差异,采用低秩适应(LoRA)技术将视频模型迁移至3D领域,并设计了360度循环视频生成策略。方法通过渲染3D物体为多视角视频序列,利用视频模型的时序一致性保持几何和纹理的跨视角连贯性,同时支持参考图像引导的条件生成。实验显示,在Objaverse等数据集上,ObjFiller-3D在PSNR(26.6 vs 15.9)和LPIPS(0.19 vs 0.25)等指标上显著超越NeRFiller和Instant3dit等现有方案,重建时间缩短至10分钟内。该方法还拓展至3D场景补全和对象编辑任务,在文化遗产修复等场景展现应用潜力,为高质量3D内容生成提供了新范式。
论文来源:hf
Hugging Face 投票数:4
论文链接:
https://hf.co/papers/2508.18271
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18271
(19) Select to Know: An Internal-External Knowledge Self-Selection Framework for Domain-Specific Question Answering

论文简介:
由中科大、百度等机构提出了Select2Know(S2K),该工作提出了一种基于内部-外部知识自选择策略的领域问答增强框架。针对大语言模型在领域问答中知识掌握不全、检索增强易引入噪声、持续预训练成本高等问题,S2K通过三个创新模块实现高效领域适应:首先采用token-level自选择机制融合模型内部参数知识与外部文档知识,构建高质量训练数据;其次设计选择性监督微调(Selective SFT),基于预测不确定性动态调整训练权重,重点优化未掌握知识;最后引入结构化推理数据生成流程和GRPO强化学习,提升复杂推理能力。实验在医学(MedQA)、法律(JECQA)、金融(FinanceIQ)三大领域验证,S2K在Avg@5、Cons@5等指标上全面超越检索增强(如Self-RAG)、强化学习(如PPO)等方法,性能比肩BioMistral等百亿级领域预训练模型,但训练数据量减少2-3个数量级。该框架通过显式建模知识融合过程,在保持低训练成本的同时实现跨领域泛化能力,为垂直领域知识增强提供了新范式。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.15213
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.15213
(20) Training Language Model Agents to Find Vulnerabilities with CTF-Dojo

论文简介:
由Monash大学和AWS AI Labs联合提出的CTF-Dojo是一个面向网络安全任务的大规模可执行环境,首次提供了658个完全功能化的CTF挑战,通过容器化技术实现可复现的训练环境。该工作核心贡献在于开发了CTF-Forge自动化管道,能够将公开的CTF资源在数分钟内转换为Docker镜像,效率较人工配置提升98%,解决了传统漏洞检测环境配置耗时的问题。研究团队通过结合CTF解题指南作为推理提示、动态环境参数扰动以及多教师模型轨迹融合等关键技术,仅用486条高质量执行轨迹便使Qwen系列模型在InterCode-CTF、NYU CTF Bench和Cybench三大基准测试中取得显著提升,其中32B模型达到31.9%的Pass@1成绩,超越Claude-3.5-Sonnet等前沿模型,创下开源模型新纪录。实验表明,CTF-Dojo训练的模型在密码学、逆向工程和二进制漏洞利用等任务中表现突出,特别是通过环境多样性增强(如端口随机化、路径扰动)使挑战解决率提升24.9%。该研究证实了基于真实执行反馈的代理训练范式在网络安全领域的有效性,为构建自主渗透测试系统提供了可扩展的解决方案。
论文来源:hf
Hugging Face 投票数:3
论文链接:
https://hf.co/papers/2508.18370
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18370
(21) QueryBandits for Hallucination Mitigation: Exploiting Semantic Features for No-Regret Rewriting

论文简介:
由摩根大通AI研究部等机构提出了QueryBandits,该工作提出了一种基于多臂赌博机框架的查询重写策略,通过分析输入查询的17个语言特征来动态优化重写方案,从而主动降低大语言模型的幻觉生成。研究发现,静态提示策略(如Paraphrase和Expand)可能加剧幻觉问题,而QueryBandits通过上下文感知的Thompson Sampling算法,在13个QA基准测试中实现了87.5%的胜率提升,显著优于无重写基线和静态提示方法(分别高出42.6%和60.3%)。实验表明,不同查询特征与最佳重写策略存在强关联性,例如领域专有性特征更适配Expand策略,而语用特征则适合Simplify策略。该方法通过纯前向传播机制实现,无需模型微调,为提升LLM可信度提供了高效解决方案。
论文来源:hf
Hugging Face 投票数:2
论文链接:
https://hf.co/papers/2508.16697
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.16697
(22) Demystifying Scientific Problem-Solving in LLMs by Probing Knowledge and Reasoning
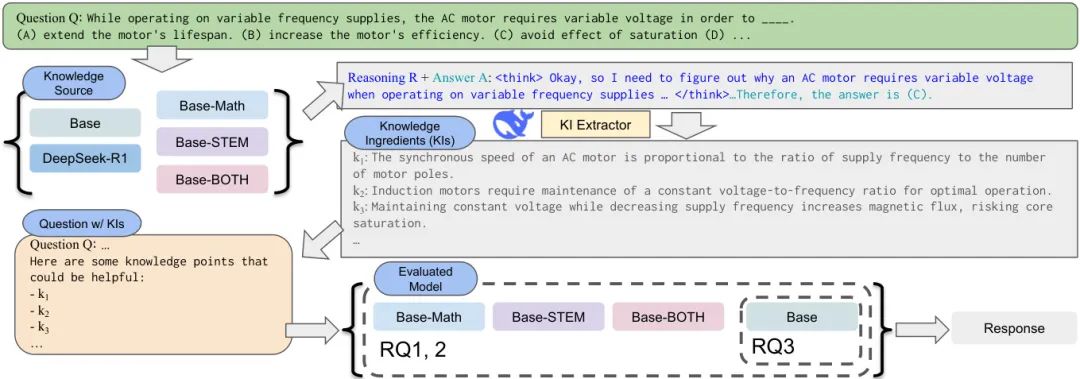
论文简介:
由耶鲁大学、哈佛大学、西北大学和Allen Institute of AI等机构提出了SCIREAS和KRUX,该工作构建了首个跨领域的科学推理统一评估基准,并通过知识控制实验揭示了大模型科学问题解决中知识检索瓶颈及推理增强机制。
################# 分割行,以下为论文原始材料 #############
该研究针对科学问题解决中知识与推理能力的协同作用展开系统性分析。首先构建了包含10个主流科学基准的SCIREAS套件,覆盖物理、化学、生物等8大学科,支持多模态问题形式;并从中筛选出高推理密度的SCIREAS-PRO子集,通过对比不同推理预算下的模型表现,发现顶尖模型在复杂推理任务上仍存在显著性能差距。研究团队进一步提出KRUX分析框架,通过从推理链中提取"知识要素"(KIs)并注入上下文,首次实现了对模型知识利用能力的可控评估。关键发现包括:1)提供高质量外部知识可使基础模型性能超越推理增强模型,表明知识检索是当前瓶颈;2)推理模型在获得相同外部知识后仍能持续提升,验证了知识增强的互补性;3)数学推理微调能显著提升基础模型对科学知识的提取能力,证明链式推理可优化知识激活路径。实验还表明,数学与STEM数据混合微调的Qwen-BOTH模型在科学推理任务上表现最优。研究最后发布了8B参数的SCILIT01基线模型,为开源科学推理研究提供基准。这些发现为构建兼具深度知识与复杂推理能力的科学辅助系统提供了重要设计依据。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.19202
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.19202
(23) Steering When Necessary: Flexible Steering Large Language Models with Backtracking

论文简介:
由南京大学等机构提出了Steering When Necessary: Flexible Steering Large Language Models with Backtracking,该工作提出了灵活激活干预与回溯机制(FASB),通过动态追踪大语言模型(LLMs)内部状态实现精准行为控制。现有方法普遍采用无差别干预或仅依赖问题内容判断干预强度,易导致过度干预或校正不足。FASB创新性地在生成过程中实时评估生成内容与目标行为的偏差,结合问题和已生成内容动态调整干预强度,并引入回溯机制修正已偏离的token序列。具体而言,该方法通过探针技术识别与目标行为相关的注意力头,构建分类器和引导向量;在生成阶段,每步生成后利用分类器评估偏差概率,当超过阈值时回溯指定步数重新生成,并根据偏差程度自适应调整干预强度。实验表明,在TruthfulQA开放生成任务中,FASB的TruthInfo指标达80.56%,较基线提升21.18%,在COPA、StoryCloze等六项多选任务中平均准确率提升13.7%。消融实验验证了自适应强度和回溯机制的有效性,当移除回溯功能时TruthInfo骤降至62.11%。该方法在LLaMA2-7B、Qwen2.5-7B等六种模型上均显著提升表现,且在Natural Questions等跨领域数据集展现良好泛化能力。研究同时揭示了干预强度与信息量的权衡关系,当干预强度α=60时取得最优平衡点。代码和数据将开源,为可控文本生成提供了高效解决方案。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.17621
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17621
(24) Unraveling the cognitive patterns of Large Language Models through module communities

论文简介:
由 Rensselaer Polytechnic Institute 和 IBM Research 等机构提出了通过模块社区揭示大型语言模型认知模式的网络分析框架,该工作构建了连接认知技能、数据集和模型模块的多层网络,发现 LLMs 的模块社区在技能分布上虽未严格遵循生物系统的局部专业化特征,但展现出类似鸟类和小型哺乳动物大脑的分布式互联认知组织模式。研究通过 Louvain 社区检测揭示技能与模块的非对齐性,发现技能分布与预定义认知功能统计独立,模块社区通过跨区域动态交互和神经可塑性显著提升技能获取效率。通过对比生物系统的强局部化、小世界和弱局部化架构,验证了 LLMs 的分布式知识表征特性,实验表明社区导向的微调虽引发更大参数变化,但未带来精度优势,而全模块微调效果最佳,印证了模型依赖全局协作而非严格模块化分工的特性。该研究为模型可解释性提供了神经科学启发的新视角,建议优化策略应聚焦分布式学习动态而非刚性模块干预,为理解 LLMs 的认知机制和改进微调方法提供了重要理论依据。
论文来源:hf
Hugging Face 投票数:1
论文链接:
https://hf.co/papers/2508.18192
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18192
(25) Forecasting Probability Distributions of Financial Returns with Deep Neural Networks

论文简介:
由 Jakub Michankow 等来自 TripleSun 的研究者提出了 Forecasting Probability Distributions of Financial Returns with Deep Neural Networks,该工作系统评估了深度神经网络在金融收益概率分布预测中的应用。研究采用1D卷积神经网络(CNN)和长短期记忆网络(LSTM)架构,通过自定义的负对数似然损失函数直接优化正态分布、学生t分布及偏斜学生t分布的参数,对S&P 500、BOVESPA、DAX等六大股指的历史数据进行分布预测。实验表明,深度学习模型在概率预测指标(LPS、CRPS、PIT)上表现优异,其中LSTM结合偏斜学生t分布(LSTM-SSTD)在捕捉金融收益的厚尾和非对称性特征方面效果最佳,其预测分布的校准质量(PIT p值)和风险价值(VaR)估计精度均优于传统GARCH模型。研究进一步验证了深度学习方法在风险管理和投资组合优化中的实用性,为金融时间序列建模提供了替代传统计量经济模型的新范式。
论文来源:hf
Hugging Face 投票数:0
论文链接:
https://hf.co/papers/2508.18921
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.18921
(26) ClaimGen-CN: A Large-scale Chinese Dataset for Legal Claim Generation

论文简介:
由浙江大学等机构提出了ClaimGen-CN,该工作构建了首个中文法律主张生成数据集并提出针对法律文本生成的评估指标。论文聚焦民事诉讼中的原告主张生成任务,指出当前法律AI研究多关注法庭场景而缺乏对非专业人士的支持。研究者从中国裁判文书网收集20万份民事案件构建数据集,涵盖100类案由并标注事实与主张的对应关系。为评估模型性能,团队设计了事实性与清晰度双维度指标,通过GPT-4o对Claude3.5、DeepSeek-R1等大模型进行零样本评测,发现现有模型在事实准确性和主张明确性方面存在显著不足。实验显示DeepSeek-R1在人工评价中得分最高,但所有模型均存在法律知识缺失、法条逻辑断裂等问题。研究建议未来可探索大小模型协作、长链推理和强化学习等方向提升生成质量,同时强调需加强法律AI的可解释性与伦理规范。该数据集的公开将推动法律文本生成领域的进一步发展。
论文来源:hf
Hugging Face 投票数:0
论文链接:
https://hf.co/papers/2508.17234
PaperScope.ai 解读:
https://paperscope.ai/hf/2508.17234










