9 条新鲜资讯
3 个有用工具
1 个有趣案例
3 个鲜明观点🤯 Meta 投资 Scale AI 遭遇波折:高管离职、数据质量受质疑,AI 部门陷入动荡今年 6 月,Meta 向 Scale AI 投资了 143 亿美元,并邀请其 CEO Alexandr Wang 以及部分高管加入,负责运营 Meta 超级智能实验室(MSL)。然而,据 TechCrunch 报道,Wang 带来的高管之一——Scale AI 前 GenAI 产品与运营高级副总裁 Ruben Mayer——仅在 Meta 工作两个月便离职。据消息人士称,他在 Meta 短暂任职期间,负责管理 AI 数据运营团队,但并未加入 TBD Labs——Meta 内部专门研发 AI 超级智能的核心部门。不过,Mayer 否认了其中一些细节。他表示,他的初始角色是「帮助实验室建立起来,做任何需要的事情」,并强调自己「从第一天起就是 TBD Labs 的一员」,而不是被排除在核心部门之外。他还澄清自己并未直接向 Wang 汇报,并表示在 Meta 的经历非常愉快,离职是因为「个人原因」。此外,多位消息人士称,TBD Labs 的研究人员认为 Scale AI 的数据质量不佳,更倾向于使用 Scale AI 竞争对手 Surge 和 Mercor 的服务。与此同时,自从 Wang 和一批顶尖研究人员加入后,Meta 的 AI 部门变得更加混乱。来自 OpenAI 和 Scale AI 的新员工对大公司内部的繁琐流程感到不满,而 Meta 原有的 GenAI 团队也被边缘化。据 Business Insider 报道,MSL 已经启动了下一代 AI 模型的研发,并计划在今年年底前推出。但据知情人士透露,Meta AI 领导层讨论过使用 Google 的 Gemini 模型,为用户在 Meta AI 中输入的问题提供对话式文字回答。另一位知情人士表示,这些领导者还讨论过用 OpenAI 的模型来支持 Meta AI 及其在社交应用中的其他 AI 功能。🔗 https://www.theinformation.com/articles/metas-ai-leaders-discuss-using-google-openai-models-apps?rc=qmzset⚒️ 马斯克 xAI 起诉前员工跳槽 OpenAI 时盗取商业机密据 The Information 报道,马斯克旗下的人工智能公司 xAI 近日将矛头对准了一名前员工,指控其在跳槽至竞争对手 OpenAI 时窃取了公司核心技术机密。根据当地时间周四在加利福尼亚州北部地区联邦法院提交的诉状,xAI 指控前工程师 Xuechen Li 在今年 7 月正式离职前数天,私自下载了公司内部关于「比 ChatGPT 功能更先进的尖端 AI 技术」的机密信息。诉状显示,Xuechen Li 在获取这些敏感技术资料后不久即离开 xAI,并出售了价值 700 万美元的 xAI 股票,随后则加入了 OpenAI 担任工程师职位。而此前,马斯克个人已对 OpenAI 及其首席执行官萨姆·奥特曼提起诉讼,质疑该公司的非营利组织地位,相关案件中马斯克预计将在未来几周内接受法庭询问。🔗 https://www.theinformation.com/briefings/elon-musks-xai-sues-ex-employee-allegedly-taking-secrets-openai?rc=qmzset💵 被 OpenAI 开除的 23 岁天才少年:一年募资 15 亿美元创投资传奇据《华尔街日报》报道,去年被 OpenAI 解雇的前员工 Leopold Aschenbrenner 仅用一年时间就将自己创立的 AI 投资基金规模做到 15 亿美元,今年上半年回报率更是达到 47%。
作为对比,同期标普 500 指数回报率仅为 6%,科技对冲基金指数也只有 7%。这意味着该基金的表现是华尔街平均水平的 7 倍左右。

Leopold 的投资理念很直接:全面押注 AI 领域。基金主要投资 AI 半导体、基础设施和能源公司,同时也向包括 Anthropic 在内的少量 AI 初创企业投资。为控制风险,他还计划通过做空一些可能被 AI 淘汰的传统行业来对冲。
据悉,Leopold 出生于德国,19 岁从哥伦比亚大学毕业,拥有数学、统计学和经济学三个学位。2023 年,他加入 OpenAI 的 Superalignment 团队,在 Ilya Sutskever 指导下研究 AI 安全问题。
2024 年 4 月,Leopold 因泄漏 OpenAI 内部安全漏洞被解雇。一个月后,他所在的超级对齐团队解散,指导老师 Ilya Sutskever 也离开了 OpenAI。
被迫离职后,Leopold 发布了 165 页的研究报告《Situational Awareness》,预测 AGI 将在 2027 年实现。这份报告在业内引起广泛关注,也成为他基金的名称来源。在报告最后,他写下了「献给 Ilya Sutskever」的致谢。
🔗 https://www.wsj.com/finance/investing/billions-flow-to-new-hedge-funds-focused-on-ai-related-bets-48d97f41
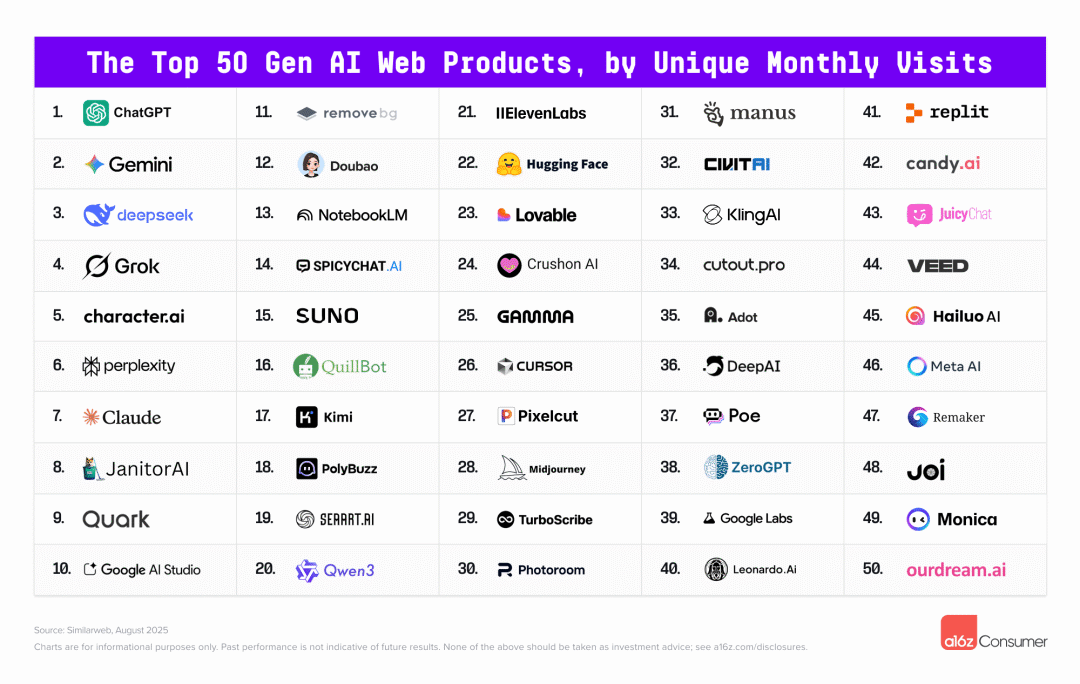
🍜 威尔·史密斯被指用 AI 「造假」粉丝,真相比想象更复杂「好莱坞明星威尔・史密斯吃意大利面」视频,堪称 AI 视频模型的图灵测试,而在近日,他在社交媒体上发布的一段欧洲巡演视频却因为 AI 而引发了广泛争议。史密斯在视频配文中写道:「巡演中我最喜欢的部分就是能近距离见到你们,也感谢你们来看我。」视频显示,在人山人海的演唱会现场,粉丝们举着各种标语表达对史密斯的喜爱。其中一位粉丝甚至表示,史密斯的音乐帮助自己战胜了癌症。乍看之下,画面显得真实可信,但仔细观察后却能发现诸多异常:面部特征经过数字化处理的痕迹、不合理的手指位置以及明显经过人工增强的面部特征。这些细节让人产生了强烈的违和感。注意到了这些异常的粉丝们,纷纷在网络上指控该视频使用了 AI 技术生成人群镜头。不过,科技博主安迪·巴约通过深入调查发现,这些粉丝很可能是真实存在的。他指出,史密斯在巡演期间发布的其他照片和视频中出现了与争议视频相同的粉丝和标语。这些早期发布的内容并无任何 AI 生成的迹象,但当它们出现在新视频中时,却呈现出明显的 AI 生成特征。分析人士认为,史密斯的团队很可能将真实的演唱会片段与使用真实人群照片作为素材生成的 AI 视频进行了拼接。🔗 https://techcrunch.com/2025/08/28/ai-or-not-will-smiths-crowd-video-is-fresh-cringe-2/🏆 《时代》公布 AI 百大人物:任正非梁文锋王兴兴入选8 月 29 日,《时代》周刊发布了 2025 年度 AI 领域最具影响力的 100 人名单。当中像 Sam Altman、黄仁勋、马斯克这些几乎天天霸占头条的 AI 明星自不必说,而 OpenAI 、Meta、Google 这些大厂还有多位员工入选。今年也有多了不少中国面孔,包括 DeepSeek CEO 梁文锋,华为创始人任正非、宇树科技 CEO 王兴兴、小马智行 CEO 彭军等等。值得一提的是,在一众技术背景强大的大神中,也有并非身处 AI 行业的,比如华人记者 Karen Hao ,她花了 7 年调查,在新书中揭开了 OpenAI 的大量内幕。比起谁上榜了,谁没上榜可能更值得玩味。比如前 OpenAI 首席科学家 Ilya Sutskever,他创办的公司 SSI ,在没有推出任何产品的情况下,估值已经达到 320 亿美元。此外,机器学习之父 Hinton 和 DeepMind CEO 、诺奖得主 Demis Hassabis,也没出现在这份榜单。🍎 外媒:苹果对大型交易的抵触可能会阻碍自身 AI 发展日前,The Information 报道称,苹果虽然 AI 领域已经出现落后情况,但其对重大类型或 AI 领域的交易仍表现出「不太感兴趣」的态度。报道指出,鉴于人工智能的重要性,以及公司在该技术方面已被打上「落后于竞争对手」的普遍看法,苹果对交易的回避可能会具有风险。据知情人士透露,苹果内部并非没有讨论过交易或收购其他 AI 公司。苹果服务部门负责人 Eddy Cue 作为公司内部对 AI 交易最坚定的支持者,其曾讨论过潜在的交易目标:对标 OpenAI 的 Mistral AI、AI 搜索引擎大户 Perplexity。报道也分析称,大型的收购、交易可能会适得其反 —— 导致新合并的组织之间出现文化冲突。值得一提的是,苹果 CEO 库克曾在 7 月的财报电话会中回应了公司的收购策略,其称苹果对收购各种规模的公司持开放态度,并表示非常欢迎加入。而据知情人士表示,苹果目前计划是坚持在人工智能领域,专注于小型交易。🔗 https://www.theinformation.com/articles/apples-aversion-big-deals-thwart-ai-push?rc=qmzset🤖 特斯拉改变了其 Optimus 训练策略,只用纯视觉训练据 Business Insider 报道,特斯拉 6 月底改变了人形机器人 Optimus 的训练方式。据知情人士透露,特斯拉不再使用动作捕捉设备,转而让工人录制视频来训练机器人。新方法要求员工戴着装有 5 个摄像头的头盔和背包,录制折叠 T 恤、捡物品等动作。特斯拉表示这样能更快收集数据。马斯克一直坚持用摄像头训练 AI 的理念。特斯拉自动驾驶也是主要靠摄像头,而非其他公司使用的激光雷达。马斯克还说机器人最终能通过看 YouTube 视频学会新技能。动作捕捉和远程操作是行业标准做法,波士顿动力等公司都在使用。特斯拉此前也雇佣「数据收集员」穿动作捕捉服录制家务动作,但由于设备故障排查工作占用了大量时间,限制了团队的数据收集效率。而在今年 1 月份的财报电话会议上,马斯克表示 Optimus 人形机器人的训练需求最终可能至少是汽车所需训练需求的 10倍。🔗 https://www.businessinsider.com/tesla-musk-optimus-humanoid-robot-training-motion-capture-cameras-2025-8?utm\_source=robotnews.therundown.ai&utm\_medium=newsletter&utm\_campaign=nvidia-s-palm-sized-robot-brain🤯 全球 AI 百大应用榜:ChatGPT 王座不保8 月 28 日,硅谷顶级风投 a16z 发布了新一期的 AI 应用百大榜单,而我们也为你快速总结了此次榜单的几点趋势:ChatGPT 依旧稳坐第一,但这个宝座越来越不安全了。Google 的 Gemini 用户数已经追到它的一半,它俩现在是两大顶级的新一代人工智能平台。马斯克的 Grok 靠着一款二次元虚拟伴侣 Ani,硬是从 0 干到 2000 万月活。DeepSeek 在年初爆火后月活跃用户大幅下降,移动端下降了 22%,网页端更是达到了 40%。国产应用表现继续亮眼,移动端 Top 50 的应用中,估计有 22 款是由中国团队开发的。Kimi、豆包、夸克直接闯进了全球前 20。另外,本次新增的 11 个网页 AI 产品,包含 Qwen、Manus、Lovable 等今年上半年的热门工具。纵观这份报告,可以看到 AI 消费应用的生态已经进入细分和稳定阶段,创新开始变得越来越困难。🍌 Google 发布新图像生成模型 nano banana本周,Google 正式提出了其最先进的图像生成与编辑模型——Gemini 2.5 Flash Image(又名 nano banana)。
据官方介绍,Gemini 2.5 Flash Image 的主要特点包括下面几点:充分保持角色的一致性:它可以轻松地将同一个角色置于不同的环境中,或者从多个角度展示同一款产品,同时完美地保持其核心主体不变。基于提示的图片编辑:允许用户通过简单的自然语言指令,对图片进行精准的局部修改 。利用 Gemini 的现实世界知识:模型可借助 Gemini 强大的世界知识库,让图像生成变得更加「智能」。多幅图像融合:可以将一张图片中的物体「放」进另一张图片的场景里,整个过程只需一条提示指令就能完成。性能表现上,Gemini 2.5 Flash Image 在多项基准测试上均为第一名,超越 OpenAI ChatGPT 4o(GPT Image 1 high)、Qwen Image Edit 等模型。关于调用 API,具体的定价是每百万输出 token 30 美元,官方介绍,生成一张图片大约消耗 1290 个输出 token,也就是说,每张图片的成本约为 0.039 美元,换算下来人民币不到 3 毛钱。目前,Gemini 2.5 Flash Image 已经可以通过 Gemini APP、Gemini API、Google AI Studio 和 Vertex AI 进行访问。更多有趣的「邪修」玩法回应回看 APPSO 此前文章:当地时间 8 月 28 日,马斯克旗下的 xAI 宣布推出全新编程类推理模型 Grok Code Fast 1。据介绍,Grok Code Fast 1 拥有 256k 的上下文窗口长度,号称「快速响应+经济价格」。xAI 方面表示,在用户读完思考轨迹的第一段之前,模型就已调用了数十种工具;团队还投入了快速缓存优化,缓存命中率通常超过 90%。官方还表示,Grok Code Fast 1 擅长 TypeScript、Python、Java、Rust、C++ 和 Go,并且能在极少监督下完成常见的编程任务 —— 从构建零到一的项目,和提供有见地的代码库问题答案,到执行精准的 Bug 修复。价格方面,百万输入 tokens 为 0.2 美元(约合人民币 1.43 元),百万输出 tokens 为 1.5 美元(约合人民币 10.70 元),每百万缓存输入 tokens 为 0.02 美元(约合人民币 0.14 元)。性能表现上,Grok Code Fast 1 在内部基准测试的 SWE-Bench-Verified 完整子集上获得 70.8% 的成绩,超越 Google Gemini 2.5 Pro、OpenAI o3 等模型,但仍未能达到 OpenAI Codex-1、Claude 4 家族。🔗 https://x.ai/news/grok-code-fast-18 月 28 日,腾讯混元宣布开源端到端视频音效生成模型 HunyuanVideo-Foley,号称「只需输入视频和文字,就能为视频匹配电影级音效」。据介绍,HunyuanVideo-Foley 拥有以下亮点:泛化能力好:可适配人物、动物、自然景观、卡通动画等各类视频,生成与画面精准匹配的音频。多模态语义均衡响应:得益于创新的结构设计,HunyuanVideo-Foley既能理解视频画面,又能结合文字描述,自动平衡不同信息源,生成层次丰富的复合音效,不会因为过度依赖于文本语义而只生成部分音效。专业级音频保真度:团队引入表征对齐(REPA)损失函数,利用预训练音频特征为建模过程提供语义与声学指导,显著提升了音频生成质量和稳定性。此外,得益于强大的音频 VAE 和高质量数据,HunyuanVideo-Foley 极大程度抑制了底噪和不一致的音效瑕疵的出现,保证了专业级的音频保真度。在多个权威评测基准上,HunyuanVideo-Foley 的性能表现全面领先,在音频保真度、视觉语义对齐、时间对齐和分布匹配等维度均达到了新的 SOTA 水平,超越了所有开源方案。即日起,用户可在 Github、HuggingFace 下载 HunyuanVideo-Foley,也可以在混元官网直接体验。体验入口:https://hunyuan.tencent.com/video/zh?tabIndex=0
技术报告:https://arxiv.org/abs/2508.16930HuggingFace:https://huggingface.co/tencent/HunyuanVideo-Foley🔈 OpenAI 发布语音 Agent 多模态模型8 月 29 日,OpenAI 正式发布了专用于语音 Agent 的多模态模型 GPT-realtime。官方介绍,新模型在遵循复杂指令、精确调用工具以及生成更自然、更具表现力的语音方面表现优秀,譬如在重复字母/数字、逐字阅读免责声明脚本、句子之间无缝切换语言等场景。值得一提的是,GPT-realtime 拥有出色的理解能力,能够捕捉到非语言类线索(如笑声),并且能实时在呈现的语音中调整语气。根据内部评估,GPT-realtime 在其他语言(包括西班牙语、中文、日语和法语)中检测字母数字序列(如电话号码、VIN 等)的准确性也更高。在衡量推理能力的 Big Bench Audio 基准测试中, GPT-realtime 的准确率达到了 82.8%,超越了 2024 年 12 月发布的 GPT-4o-realtime(65.6%)。其他方面,GPT-realtime 新增了「Marin」和「Cedar」音色。并且 GPT-realtime 还支持图像输入。另外,OpenAI 还上线了 Realtime API 的多项全新功能:在 Realtime API 会话中,开发者只需在会话配置中轻松传入远程 MCP 服务器的 URL,即可快速启用 MCP 支持。Realtime API 能够直接与公共电话网络、专用分组交换机系统、桌面电话及其他 SIP 终端建立连接。🔗 https://openai.com/index/introducing-gpt-realtime/🐟 与视觉模型斗智斗勇,病毒式 AI 绘画游戏「画鱼」走红一款名为「Draw a Fish」(画鱼)的 AI 绘画游戏本周在社交媒体上意外走红。该游戏的玩法颇具创意:用户使用数字画笔绘制鱼类图案,但关键在于必须「说服」AI 视觉模型认可自己的作品确实是一条鱼。只有通过 AI 审核的鱼类作品才能获得「生命」,被投放到全球共享的虚拟鱼缸中与其他玩家的作品一同「游泳」。用户可以在虚拟鱼缸中「捕捉」其他人创作的鱼类,并对这些作品进行点赞或差评。游戏平台还提供了排行榜功能,展示所有用户创作的鱼类作品。🔗 https://x.com/venturetwins/status/1961835208233345330🌗 月之暗面 CEO 杨植麟:全球只会剩几家 AI 头部公司时隔一年半再次接受张小珺深度访谈,月之暗面创始人杨植麟分享了对 AI 技术演进、模型开源、创业心路的最新思考杨植麟将过去一年全球大模型发展总结为两个重要范式:长思考推理模型和基于多轮交互的 Agent 模型。前者以 OpenAI 的 o1 为代表,让模型通过内部反思和验证提升能力,但仍是「缸中之脑」式的封闭思考;后者则让模型能够与外界交互,通过调用工具、执行代码等方式完成复杂任务。对于选择开源 K2 模型,杨植麟坦承这既有技术信仰也有市场策略的考量。他修正了去年「领先者不会开源」的观点,认为在当前阶段,开源能够赋能下游应用开发更好的专用 Agent。关于中国公司普遍选择开源的现象,杨植麟认为确实存在市场博弈因素,但这对技术社区是有益的。长期来看,全球可能只会剩下几家头部模型公司,市场正在趋向集中。「几个,或许是最终稳定数量,现在看是大概率的事。」谈及未来技术发展方向,杨植麟认为 Agent 的泛化能力是最重要的技术里程碑。只有当通用 Agent 能够泛化到长尾工具和场景时,各种垂直领域的专用 Agent 需求才会减少。在技术路径上,月之暗面将继续投入多模态能力和长上下文支持的研究。杨植麟特别强调,多模态不能仅仅是不损伤模型「智商」,而要让多模态和文本模式共用同一个「大脑」,避免割裂式的能力发展。对于 Scaling Law 是否放缓的讨论,杨植麟认为虽然面临数据墙限制,但通过提升 Token 效率和强化学习扩展,模型改进速度并未减缓,甚至在加速。🔗 https://mp.weixin.qq.com/s/uqUGwJLO30mRKXAtOauJGA💡 微软 AI CEO:避免在无意义的 token 上浪费算力本周,微软 AI 发布了其首批全自研大模型,分别为端到端训练的基础模型 MAI-1-preview 和语音生成模型 MAI-Voice-1。具体来看,MAI-1-preview 为一款混合专家模型,大约在 1.5 万颗英伟达 H100 GPU 上完成了预训练和后训练,主打指令遵循和日常问题解答等能力;而 MAI-Voice-1 则是一款高质量、反应快的音频模型。有趣的是,微软「死党」OpenAI 也在同日发布了一款语音模型 —— GPT-realtime。而在模型发布之前,微软 AI CEO Mustafa Suleyman 接受了「Semafor」的采访。采访中,Suleyman 大方回答了「为何不用 OpenAI 等公司的模型」这一问题:我们(微软)是世界上最大的公司之一,而 AI 是未来,不仅是技术未来,更是在将来几十年中,进行交易、开展业务、创造价值的方式。Suleyman 补充说道,AI 对微软的业务来说具有根本性的意义,「必须具备内部的专业能力,去打造世界上最强大的模型。」Suleyman 也并没有在采访中直接否定掉「第三方」,他指出,「我们希望确保微软始终有多种选择 —— 会继续使用第三方开发者的模型,当然也会长期使用 OpenAI 的模型。同时我们也在用开源模型,并会坚持这样做。」同时,Suleyman 也在采访中揭示了一些技术路线。其表示,通过 MAI-1-preview 证明,小规模性能训练出来的模型,同样也能拥有世界级的表现。Suleyman 认为,MAI-1-preview 还只是个开始。「一旦模型进入生产环境,开始收集反馈,迭代过程将显著提升性能。」值得一提的是,微软正在构建世界上最大规模的 GB200、GB300 集群之一。而 Suleyman 透露,这一集群会为 OpenAI 提供支持,也会服务于 MAI 以及微软的付费推理合作伙伴。Suleyman 大方表示,「规模固然重要,但效率同样关键。这意味着要精挑细选高质量训练数据,让每一次浮点运算、每一次 GPU 迭代都物尽其用。」避免在无意义的 token 上浪费算力。🔗 https://www.theverge.com/news/767809/microsoft-in-house-ai-models-launch-openai💰 SemiAnalysis 创始人:GPT-5 智能路由破解 AI 变现难题知名风投机构 a16z 近日与半导体分析公司 SemiAnalysis 创始人 Dylan Patel 展开了一场深度对话。Dylan Patel 指出,GPT-5 的核心突破并非参数规模的扩大,而是引入了智能路由机制。这套系统能够根据查询的价值和复杂度,自动将用户请求分配给不同性能级别的模型。「当用户询问『天空为什么是蓝色』这类简单问题时,系统会调用轻量级模型处理,但如果用户需要寻找『本地最佳醉驾辩护律师』,系统就会启动高性能模型,分析胜诉率和法庭记录,甚至直接为用户预订法律服务。」Dylan 解释道。这种路由机制为 OpenAI 解决了免费用户变现的核心难题。传统消费应用通过广告实现免费用户盈利,但这与 AI 助手的交互体验存在根本冲突。通过智能路由,OpenAI 能够在不影响用户体验的前提下,将高价值查询导向可抽佣的商业闭环,真正实现免费用户的现金流转化。此外,前谷歌云专家 Guido Appenzeller 观察到,这是首次以成本控制为核心亮点的模型发布。风投人 Erin Price-Wright 指出,企业客户真正需要的是成本可预测性,而非灵活的按量计费。「客户宁愿承诺较高额度的预付支出以避免按量计费的不确定性,真正推崇按量计费模式的,其实是模型提供商自身。」AI 的价值创造已经显现,但如何转化为产业效益则复杂得多。Dylan 估算,OpenAI 通过 ChatGPT 创造的价值中,实际捕获率不足 10%。他以自己公司为例说明:「仅用四名开发者就实现了自动化监管审查,通过 Gemini API 分析数据中心的许可文件与卫星影像,成本极低但收益可观,而提供技术的公司反而几乎未能分享收益。」🔗 https://www.youtube.com/watch?v=xWRPXY8vLY4Prompt:Soft and plush 3D model of a [subject] with a [key detail], rendered in a cute, stylized aesthetic. The texture is velvety and squeezable, emphasizing the charm of animated [object type] designs. Clean background, centered composition链接:https://x.com/azed\_ai/status/1961020464182247838欢迎加入 APPSO AI 社群,一起畅聊 AI 产品,获取#AI有用功,解锁更多 AI 新知👇✉️ 邮件标题「姓名+岗位名称」(请随简历附上项目/作品或相关链接)