点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
0.这篇文章干了啥?
这篇文章提出了OpenM3D,一种无需人工标注的新型开放词汇多视图室内3D目标检测器。目前开放词汇(OV)3D目标检测领域中,基于图像的方法探索有限,而OpenM3D是首个将OV能力拓展到多视图3D目标检测的工作。它是单阶段3D检测器,采用来自ImGeoNet模型的2D诱导体素特征,通过聚合多个RGB特征得到体素特征。为支持OV,它结合了需要高质量3D伪框的无类别3D定位损失和需要多样化预训练CLIP特征的体素语义对齐损失进行联合训练。在训练时,文章提出一种使用图嵌入技术的3D伪框生成方法,将2D片段组合成连贯的3D结构,该方法生成的伪框在精度和召回率上超过了其他方法。在推理阶段,OpenM3D仅需多视图RGB图像作为输入,每场景推理时间为0.3秒。实验在ScanNet200和ARKitScenes数据集上进行,结果表明OpenM3D在3D伪框质量、无类别和多类别3D目标检测等方面均优于现有方法,包括基于点云的方法。同时,消融实验验证了OpenM3D在不同类别数量和不同提示下的性能,还展示了其在开放词汇3D目标检测中的有效性和鲁棒性。不过,预训练CLIP特征在对许多语义相似的家用物品进行分类时还有提升空间,这将是未来的研究方向。
下面一起来阅读一下这项工作~
1. 论文信息
论文题目:OpenM3D: Open Vocabulary Multi-view Indoor 3D Object Detection without Human Annotations 作者:Peng-Hao Hsu, Ke Zhang, Fu-En Wang等 作者机构:National Tsing Hua University,Amazon,Cornell University等 论文链接:https://arxiv.org/pdf/2508.20063v1
2. 摘要
开放词汇(OV)3D目标检测是一个新兴领域,但与基于3D点云的方法相比,通过基于图像的方法对其进行的探索仍然有限。我们推出了OpenM3D,这是一种无需人工标注即可训练的新型开放词汇多视图室内3D目标检测器。具体而言,OpenM3D是一种单阶段检测器,它采用了来自ImGeoNet模型的二维诱导体素特征。为支持开放词汇,它结合了一个需要高质量3D伪框的无类别3D定位损失和一个需要多样化预训练CLIP特征的体素 - 语义对齐损失进行联合训练。我们遵循OV - 3DET的训练设置,即给定有位姿的RGB - D图像,但没有3D框或类别的人工标注。我们提出了一种使用图嵌入技术的3D伪框生成方法,该方法将2D分割合并为连贯的3D结构。我们的伪框比包括OV - 3DET中提出的方法在内的其他方法实现了更高的精度和召回率。我们进一步从与每个连贯3D结构相关联的2D分割中采样多样化的CLIP特征,以使其与相应的体素特征对齐。训练高精度单阶段检测器的关键在于让这两种损失都朝着高质量目标学习。在推理时,OpenM3D是一种高效的检测器,只需要多视图图像作为输入,并且在ScanNet200和ARKitScenes室内基准测试中,与现有方法相比,它在准确性和速度(每个场景0.3秒)方面表现更优。我们在准确性和速度上都超过了一种强大的两阶段方法,该方法利用我们的无类别检测器和基于ViT CLIP的开放词汇分类器,以及一种结合了多视图深度估计器的基线方法。
3. 效果展示
OpenM3D在ScanNet200和ARKitScenes上的定性结果。给定多视角图像及其对应的相机姿态,OpenM3D可以通过任意文本提示进行开放词汇检测来识别物体。颜色编码的框对应于不同的物体类别。我们展示了一部分在ImageNet数据集中使用的文本提示和特定提示。

4. 主要贡献
OpenM3D是首个多视图开放词汇3D目标检测器,在ScanNet200和ARKitScenes数据集上达到了当前最优精度。 提出了一种新颖的体素 - 语义对齐损失,用于将3D体素特征与多视图CLIP嵌入对齐。该损失通过聚合来自多个视角的不同CLIP特征,捕捉物体在不同角度的外观,从而实现开放词汇分类。然后,OpenM3D作为单阶段检测器,结合定位损失和对齐损失进行联合训练,在V100上每个场景的运行时间为0.3秒。 为了进行定位损失监督,我们提出了一种新颖的3D伪框生成流程,该流程利用图嵌入将2D片段整合为连贯的3D结构,在实验中超越了现有方法。
5. 基本原理是啥?
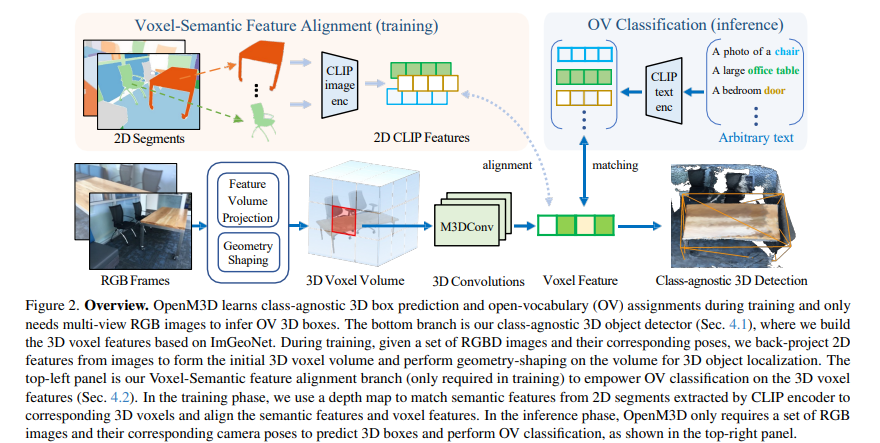
提出OpenM3D模型OpenM3D是一种无需人工标注训练的新型开放词汇多视图室内3D目标检测器。它是单阶段检测器,适配来自ImGeoNet模型的2D诱导体素特征。为支持开放词汇(OV),它联合训练了需要高质量3D伪框的类无关3D定位损失和需要多样化预训练CLIP特征的体素 - 语义对齐损失。 3D伪框生成方法
部分3D片段生成:利用现成的类无关2D实例分割方法从RGB图像中提取2D片段,然后根据相机位姿、内参和深度图将每个2D片段提升到3D,得到部分3D片段。 完整3D片段生成:将场景表示为图,每个部分3D片段作为一个节点,当两个节点的重叠率超过特定阈值时建立边。使用现成的图嵌入方法学习图表示,然后通过K - Means聚类相似节点,形成完整的3D片段。 网格分割细化:考虑基于网格的分割方法生成的3D片段,通过计算与图像生成的3D片段的重叠率,更新片段索引并合并,以细化原始的完整3D片段。 3D框生成:从完整3D片段计算轴对齐的3D边界框,计算框的中心、宽度、长度和高度,并对框的体积和包含的点数进行阈值处理,去除异常小或不太可见的框。

6. 实验结果
3D伪框评估
精度与召回率:在ScanNet200和ARKitScenes数据集上,OpenM3D生成的3D伪框在IoU@0.25和IoU@0.5的精度上均高于OV - 3DET和SAM3D。召回率方面,显著优于OV - 3DET,与SAM3D在多数情况下相当。例如在ScanNet200数据集上,OpenM3D(有Mesh Segmentation Refinement)的精度@25达到32.07%,召回率@25达到58.30%。 Mesh Segmentation Refinement(MSR)的影响:MSR能提升OpenM3D在两个数据集上的性能,但在ARKitScenes上提升效果因网格质量较低而不明显。
无类别信息场景:在ScanNet200数据集上,与OV - 3DET相比,OpenM3D的AP@25提高了37%(从19.53%提升到26.92%);与SAM3D相比,AP@25提高了13%,mAR@25分别超过SAM3D和OV - 3DET 3.3%和16%。 开放词汇场景:在ScanNet200数据集上,OpenM3D在mAP@25和mAR@25上均优于使用OV - 3DET和SAM3D伪框训练的模型。使用更好的分割模型(如CropFormer)时,mAP@25有显著提升(从4.23%提升到4.76%)。与S2D相比,OpenM3D作为单阶段检测器,mAP@25相当,但mAR@25更高,且推理时间仅为S2D的六分之一。在ARKitScenes数据集上,OpenM3D的mAR@25达到42.77,优于S2D的19.58。在ScanNetv2数据集上,OpenM3D的性能与基于点云的方法相当。
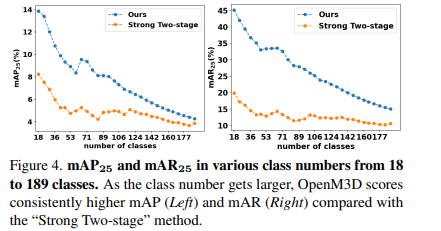
类别数量的影响:随着类别数量从18增加到189,OpenM3D的mAP和mAR始终高于“Strong Two - stage”方法。 不同提示的影响:使用Cifar100提示与使用ImageNet提示的性能差异极小,表明调整提示对性能提升不显著。
3D伪框可视化:OpenM3D的3D伪框能够准确定位场景中的各种潜在物体,包括新颖物体,验证了其定位能力。 基于重建的基线对比:基于VGGT和OVIR - 3D的重建管道在推理时间上达到300秒/场景,远高于OpenM3D的0.3秒/场景,且AP@25仅为5.97%,远低于OpenM3D的26.92%。 不同CLIP编码器的影响:使用不同的CLIP图像编码器(ViT - L/14、ViT - B/16、ViT - B/32)对mAP@25和mAR@25的影响极小,体现了OpenM3D开放词汇分类能力的鲁棒性。 使用CropFormer生成伪框的影响:在ScanNet200数据集上,使用CropFormer生成的伪框训练OpenM3D,mAP@25从4.23%提升到4.76%,表明更好的2D分割对3D伪框生成有积极影响。 ScanNetv2数据集上的检测结果:在ScanNetv2数据集上,OpenM3D使用自己的伪框训练,在AP@25、AP@50、AR@25和AR@50等指标上均优于使用SAM3D和OV - 3DET伪框训练的模型。


7. 总结 & 未来工作
总结
我们介绍了OpenM3D,这是一种新颖的单阶段开放词汇多视图3D物体检测器,无需人工注释进行训练。它利用了无类别区分的3D定位损失和体素 - 语义对齐损失,由高质量的3D伪框和多样化的CLIP特征引导。我们引入了一种基于图的3D伪框生成方法,在伪框质量方面,其精度和召回率优于OV - 3DET和SAM3D。在推理时,OpenM3D仅需要多视图图像,在ScanNet200和ARKitScenes数据集上,它的性能优于强大的两阶段方法以及使用OV - 3DET和SAM3D伪框训练的模型,同时在准确性和速度上也优于基于多视图深度估计的基线方法。
未来展望
无类别区分和开放词汇3D检测之间的差距表明,预训练的CLIP特征在对许多语义相似的家用物体进行分类时还有改进空间,我们将此作为未来的研究方向。
3D视觉硬件,官网:www.3dcver.com

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001