如您有工作需要分享,欢迎联系:aigc_to_future
转载自:机器之心
如有侵权,联系删稿
本文第一作者为新加坡国立大学博士生 张桂彬、牛津大学研究员 耿鹤嘉、帝国理工学院博士生 于晓航;通讯作者为上海人工智能实验室青年领军科学家 白磊 和 牛津大学博士后 / 上海人工智能实验室星启研究员 尹榛菲
过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。
为了突破这样的瓶颈,自 2025 年初 DeepSeek R1 及其背后的 GRPO 范式获得空前热度以后,一种新的训练范式 ——Agentic Reinforcement Learning(Agentic RL),愈发到社区关注。它试图让 LLM 从「被动对齐」进化为「主动决策」的智能体,在动态环境中规划、行动、学习。

论文标题:The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
arXiv 地址:https://arxiv.org/pdf/2509.02547
GitHub 地址:https://github.com/xhyumiracle/Awesome-AgenticLLM-RL-Papers
为了捋清这一新兴领域,一篇长达 100 页、由牛津大学、新加坡国立大学、伊利诺伊大学厄巴纳-香槟分校,伦敦大学学院、帝国理工学院、上海人工智能实验室等 16 家海内外顶级研究机构联合完成的最新综述论文,全面系统地梳理了作用于 LLM 的 Agentic RL 这一方向,覆盖 500 + 相关研究,构建了 Agentic RL 的理论框架、演化脉络与资源版图,并讨论了可信性、扩展性和复杂环境等未来挑战。
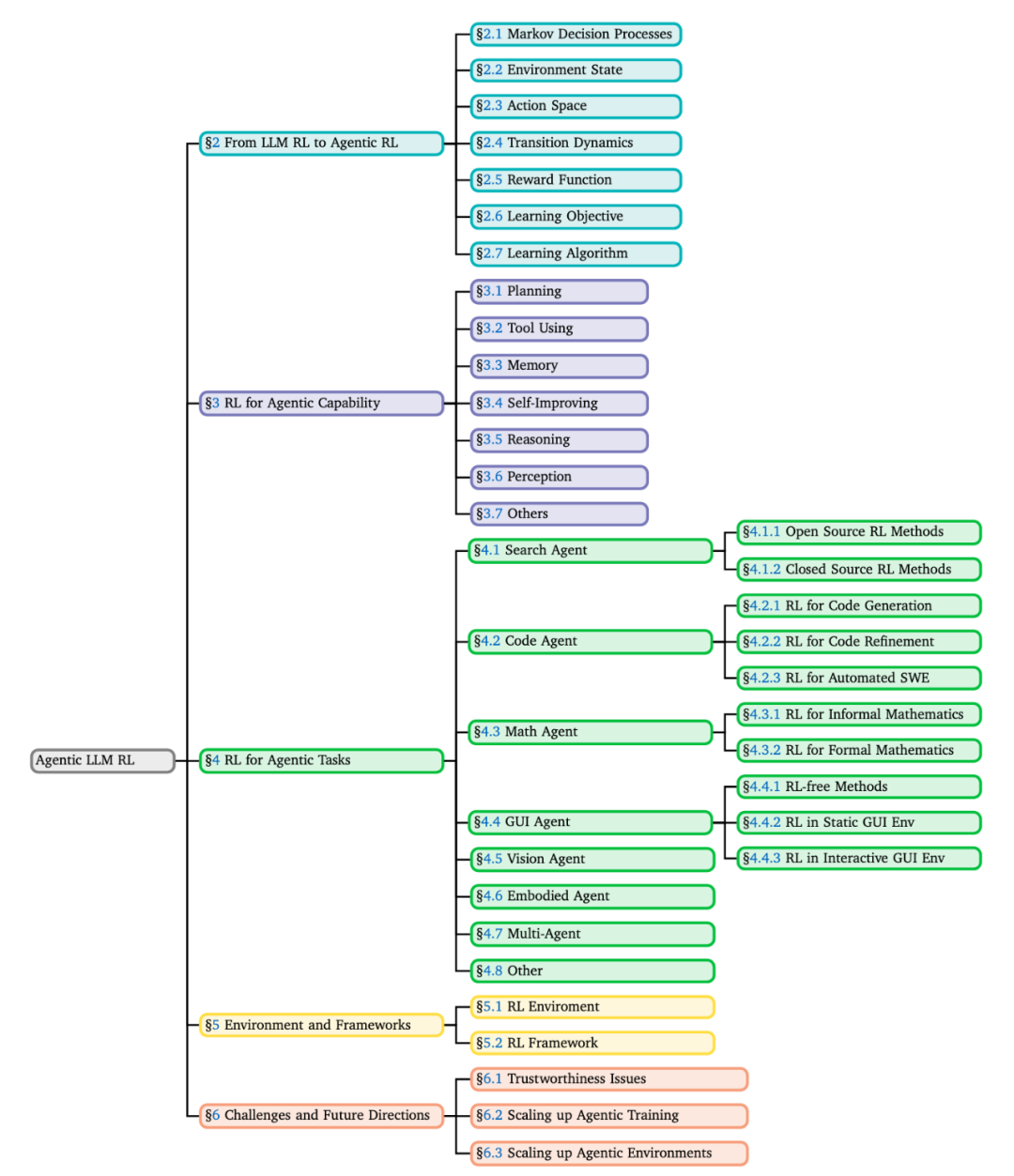
范式迁移:从 PBRFT 到 Agentic RL

从 LLM-RL 到 Agentic RL 范式迁移概览
该综述首先给出范式迁移的形式化定义:早期 RL 研究多基于 PBRFT 范式,可被视为退化的单步 MDP(单 prompt、一次性文本输出、立即终止),而 Agentic RL 则将 LLM 置于部分可观测马尔可夫决策过程(POMDP)下进行多步交互:

其中关键变化在于动作空间从单一文本扩展为「文本 + 操作」( );同时奖励从「单步评分」扩展为「时序反馈」,优化整条决策轨迹,把 LLM 从「文本生成器」推进为「可交互的决策体」。
);同时奖励从「单步评分」扩展为「时序反馈」,优化整条决策轨迹,把 LLM 从「文本生成器」推进为「可交互的决策体」。
一句话:PBRFT 让模型更会一次地说,Agentic RL 让模型更会长程地做。

在强化学习优化算法层面,当前实践形成了一条从通用策略梯度到偏好优化的谱系,Table 2 汇总比较了三类算法家族及其代表方法,便于读者快速对照「训练用什么算法」与「对齐目标/信号形态」 的对应关系。

六大核心能力:智能体的「内功」
要让 LLM 真正成为智能体,仅有动作空间还不够,它必须发展出一套完整的能力体系。该综述将其总结为六大核心模块,并对每个模块提出了前瞻性讨论:
1. 规划(Planning):为复杂任务设定子目标与多步行动序列。通过外部引导(外部打分生成奖励)或内部驱动(自主规划并修正)实现。
2. 工具使用(Tool Use):调用外部工具完成任务。从 ReAct 等静态提示模仿演进到 Tool-integrated RL (TIR),让智能体学会自主选择组合工具。
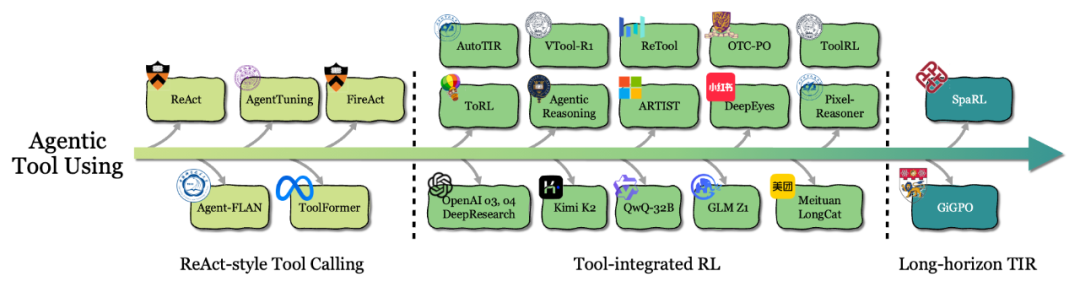
Agentic Tool Using 演化路径
3. 记忆(Memory):保持上下文连贯并积累知识,包括基于外部数据库检索记忆、Token 级别记忆和结构化记忆。其中,值得关注的工作包括来自字节跳动的 MemAgent 和麻省理工大学的 MEM1,他们都通过强化学习让 LLM Agent 拥有自行管理记忆窗口的能力。

4. 自我改进(Self-Improvement)同样是目前 Agent 最热门的发展方向。该综述高屋建瓴地将目前 Agent 自我提升的能力划分为以下三类:
基于语言强化学习,即类似于 Reflexion、Self-Critic 等风格的自我纠正;
通过强化学习训练内化自提升能力,譬如来自 MIT-IBM Watson AI Lab 的 Satori 便通过强化学习内化 Agent 在测试阶段自我纠正的能力;类似的工作还有来自上海 AI Lab 的 TTRL,Meta 的 SWEET-RL 等等;
通过迭代自训练,譬如来自清华的 Absolute Zero、来自斯坦福的 Sirius 等等。
5. 推理(Reasoning):解决复杂问题的推导能力,分为快速直觉推理(凭经验直觉迅速答题)和慢速缜密推理(多步演绎得出严谨结论)。
6. 感知(Perception):理解多模态输入的信息获取能力。模型从被动识别走向主动感知,可通过定位驱动(将推理锚定具体对象)、工具驱动(借助外部工具辅助)和生成驱动(生成图像草图辅助推理)等方式提升感知效果。

智能体与环境交互闭环示意
借助强化学习,这些能力由人工启发式转变为可学习的策略,规划不再依赖硬编码流程、工具使用也可由模型自主决定、端到端训练。

Agentic RL 6 大核心能力板块
任务落地与演化路径

不同任务领域的 Agent RL 进化树
Agentic RL 也在横向拓展应用边界,涌现出多种智能体雏形:
搜索与研究:优化多轮检索与证据整合策略,学会何时继续搜索、何时下结论;

代码:将编译错误与单元测试结果用作奖励,推动智能体能力从一次性代码生成进化到自动调试以及自动化软件工程流程;
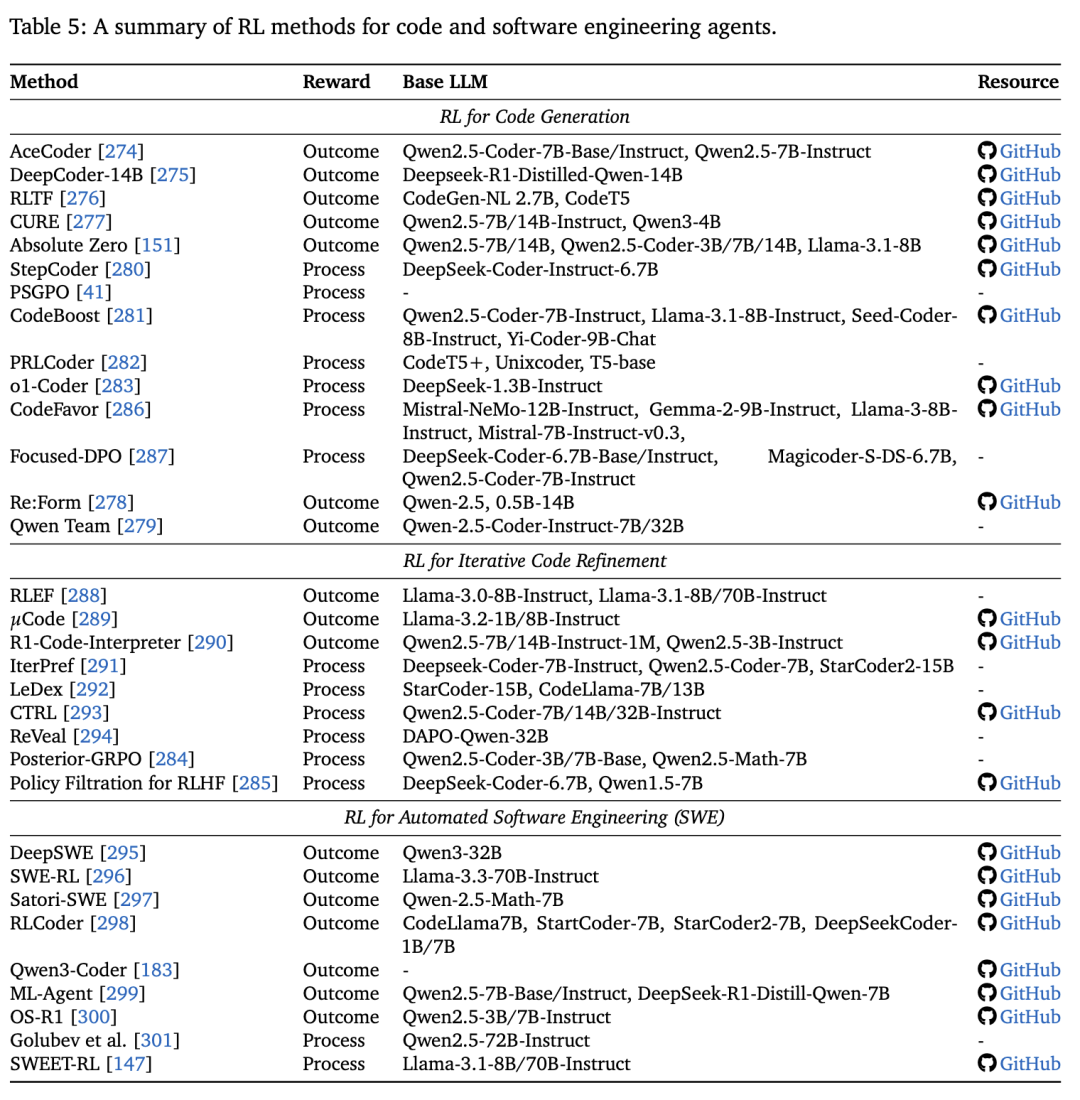
数学:在非形式化 (informal) 推理中,利用正确率或中间过程奖励来塑造推理轨迹;在形式化 (formal) 推理中,交互式定理证明器 (ITPs) 提供可验证的二值信号,使智能体能在严格规则下探索证明路径;

图形界面 (GUI):在网页和桌面环境中让智能体学习点击、输入、导航等操作,从静态脚本模仿走向交互式操作,提升对真实应用的适配性;
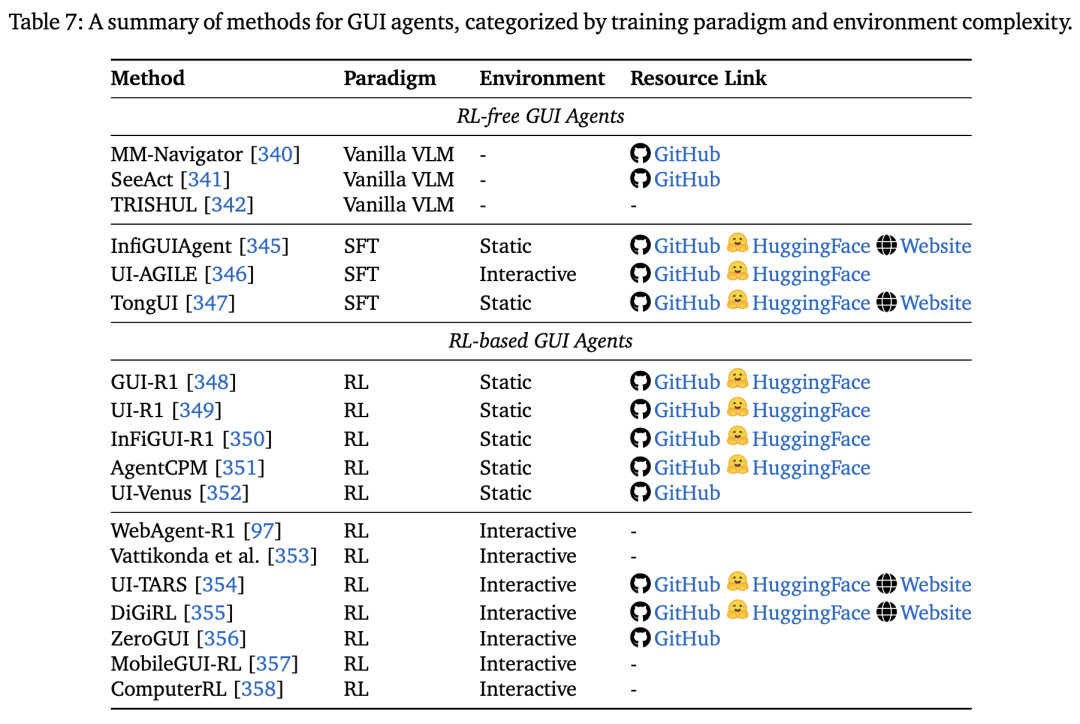
视觉与具身:融合视觉感知与决策规划,实现「看-思-做」的连续决策闭环,增强智能体在多模态问答、导航与机器人操作等任务中的表现;
多智能体系统:通过奖励设计促使多个模型在竞争或合作中逐渐涌现沟通与分工能力。

其他探索:RL 也被应用于数据分析、科学发现等场景,显示出 Agentic RL 在更多任务中的潜在适应性。
总体来看,Agentic RL 已在多个场景初步落地,并正从单一任务逐渐迈向更复杂、更贴近现实的任务生态。
环境与框架
Agentic RL 的发展离不开可复用的实验环境与工具链。现有工作已涵盖网页、GUI、代码、游戏等多种开源平台,并配套了相应的评测基准与框架,为研究者提供了开展实验和对比的基础设施。


此外,这份综述还整合了 500+ 篇相关研究,并在 GitHub 上开源了 Awesome-AgenticLLM-RL-Papers,将论文、环境、基准与框架一站式汇总,为后续研究提供了全景式的参考地图。
挑战与前瞻
尽管 Agentic RL 已展现出广阔潜力,但要真正走向稳健和实用,还存在若干核心挑战:
可信性与安全性:相比传统 LLM,Agentic RL 智能体集成了规划、工具调用和记忆等能力,攻击面显著扩大;同时,RL 的奖励驱动机制也可能导致 reward hacking,使不安全行为被强化,带来更持久的风险。
Scale Up 智能体训练:大规模 Agentic RL 训练面临算力、数据和算法效率的瓶颈。当前 RL 方法成本高昂,难以在长时程决策或复杂环境中稳定扩展,需要发展更高效的优化范式。
Scale Up 智能体环境:现有的交互环境难以覆盖真实世界的复杂性。未来应探索环境与智能体的「协同进化」,例如通过自动化奖励设计、课程生成和环境自适应优化,让环境在训练中发挥「主动教学」的作用,而不仅仅作为静态测试平台。
这些挑战构成了 Agentic RL 进一步发展的关键门槛,也为未来研究提供了明确方向。
结语
这篇综述系统化梳理了 Agentic RL 的理论框架、能力维度、任务应用与资源生态,确立了其作为 LLM 演进的重要训练范式。
综述强调:单步对齐已难以支撑复杂任务,LLM 训练范式由此进入 Agentic RL 的下半场,而强化学习是将规划、工具使用、记忆、推理等核心能力从启发式功能转化为稳健智能行为的关键机制。
未来,随着可信性、可扩展性和复杂环境等挑战的逐步突破,LLM 将有望真正从 「会说」迈向「会做」,成长为更通用、更自主的智能体。
技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!





![NexusPickit-S1!从零搭建一套无序抓取软件[源码]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-09-04/68b8c910135c9.jpeg)





