目前,人形机器人在运动控制和模仿学习方面已取得显著进展。但现有研究大多集中于自由空间中的控制或与静态地面的交互(例如保持平衡、行走或模仿人类姿态),而面对动态环境中快速移动物体的交互仍是一项重要的挑战。
这类动态交互任务的难度高,不仅需要实现数十个关节的协同控制,还需在极短时间内构建感知-动作闭环。乒乓球运动正是这一挑战的典型体现,球速超过5米/秒时,反应时间是亚秒级,机器人系统需在数百毫秒内完成感知、预测、规划与击球。
与静态物体交互不同,乒乓球运动依赖于全身敏捷运动。机器人既要快速摆臂、旋转腰部,又要快速移动并迅速恢复平衡,以确保精准击球并为下一次对打做准备。因此,人形机器人的乒乓球运动成为该领域独特的测试平台。
为此,UC伯克利提出了分层系统HITTER。该系统将高层规划和底层控制分离,高层是基于模型的轨迹规划器,用于高精度估计球轨迹,并预测击球位置、速度与时机;底层是基于强化学习的全身控制器,用于执行类人击球动作。

将HITTER部署在宇树G1人形机器人上,在大量真实场景中验证了方法有效性。宇树G1与人类对打时连续击球次数高达106次,展示了敏捷的全身控制能力和亚秒级的反应能力。

论文标题:《HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning》
论文链接:https://arxiv.org/pdf/2508.21043
项目主页:
https://humanoid-table-tennis.github.io/
1
方法
1.1 系统概述
采用分层系统,将“基于模型的规划器”与“基于强化学习的机器人全身控制器”分离,如图2所示。使用了9台OptiTrack相机跟踪球的位置,动作捕捉系统采样频率为360hz,精度可达毫米级。估计的球位姿被输入基于模型的规划器,规划器能为宇树G1预测出击球位置、时间,并计算出击球瞬间所需的球拍速度。机器人搭载强化学习策略,该策略处理观测信息后,以50hz的频率输出29个关节的期望位置;这些关节位置设定值通过PD控制器转换为关节力矩。
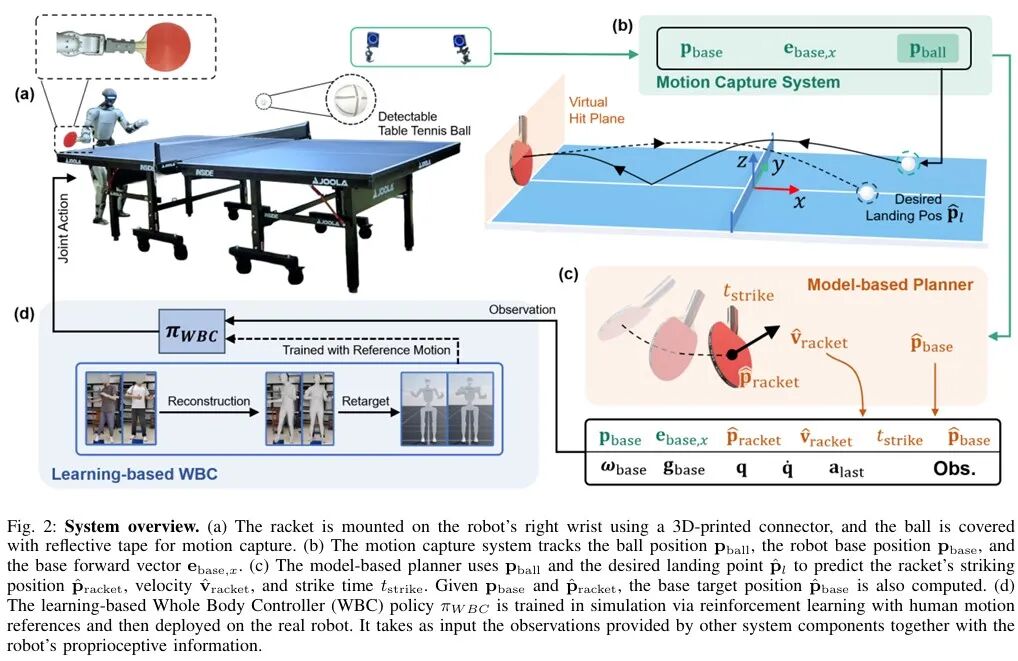
1.2 基于模型的规划器
基于模型的规划器在每个时间步接收球的位置信息,预测球拍的期望击球位置、速度与时机,并将这些预测结果传递给全身控制器以生成机器人动作。
在预测球轨迹前,需先估计球的速度,但动作捕捉系统无法直接获取速度信息,通过“二阶多项式最小二乘拟合”实现速度估计。当检测到球在球台上弹跳时,清空位置测量缓冲区,避免包含弹跳前的数据。当前时间步球的平滑位置与速度可通过计算及其导数得到。采用混合动力学模型预测乒乓球的轨迹,公式如下:

除实现球拍与球的接触外,还需成功回球,这要求确定击球瞬间时球拍的姿态与速度。假设击球瞬间球拍平面与速度向量垂直;与“精确控制落球位置”的方法不同,目标是实现“有效回球”,因此采用简化的碰撞后飞行模型与球拍-球交互模型。
1.3 基于强化学习的机器人全身控制器
基于模型的规划器预测球拍的期望击球位置、速度与时间,这些预测结果传递给了基于学习的全身控制器(WBC),生成人形机器人的全身动作。研究人员在Isaac Lab仿真环境中训练WBC策略,并以“零样本迁移”方式部署到真实机器人;策略采用无模型强化学习算法PPO进行端到端训练,关节PD增益参考现有研究通过启发式方法设定。
人类运动参考
为使机器人动作更接近人类,训练过程中融入了人类运动参考数据。采用正手与反手两种参考挥拍动作,均通过以下流程生成:
录制人类执行挥拍动作的视频片段;
通过GVHMR从视频中重建对应的SMPL运动片段;
通过GMR将运动片段迁移到人形机器人,得到30赫兹的基座姿态与关节位置数据。
参考BeyondMimic的方法,对运动数据进行改进以提升跟踪效果。处理后的每个运动片段包含94帧(1.88秒),击球动作发生在第43帧(0.86秒)。
马尔可夫决策过程(MDP)设置
基座与球拍的独立指令:不同于以“击球瞬间球拍全局位置与速度”作为指令的方法,研究人员将基座与球拍的指令分离,以提升训练效率。
为实现连续击球并不断切换挥拍类型,每回合持续10秒。完成挥拍后,均匀采样下一挥拍类型(正手/反手),并基于挥拍类型随机采样击球时刻的球拍目标位置、目标速度及基座目标位置。击球平面固定于机器人前方0.4米处,因此仅采样球拍目标位置的y、z坐标。正手与反手目标区域设为非重叠区。
奖励函数:为使机器人动作既模仿参考动作又跟踪指令目标,将总奖励定义为:

2
实验
实验针对以下三个关键问题进行评估:
基于模型的规划器预测精度如何?
专为乒乓球运动设计的全身控制策略敏捷性如何?
在真实场景中回球效果如何?能否与人类或人形机器人对打?
2.1 基于模型的规划器
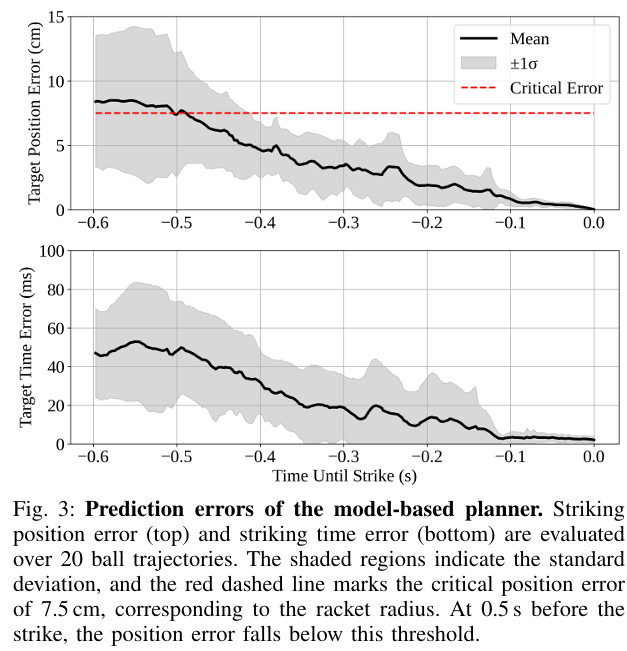
为评估规划器性能,收集20条乒乓球轨迹,计算击球位置与击球时间的预测误差,如图3所示。结果表明,预测误差随击球时候临近而减小,接触时刻降为零。这与“预测时域越长,累积误差越大”的直觉一致。击前0.5秒位置预测误差低于关键阈值7.5cm(球拍半径);击前0.3秒时间预测误差低于20ms(策略控制步长);击前0.1秒误差趋于最小。全程低误差为WBC策略提供稳定指令接口,奠系统整体精度的基础。
2.2 机器人全身控制
仿真环境
为评估全身控制策略的敏捷性,计算了“基座期望位置与实际基座位置的初始距离”与“到达附近1厘米范围所需时间”的关系。在仿真环境中进行1000次滚动实验,剔除了57个未达到1厘米阈值的案例,得到943个有效数据点,成功率为94.3%。实验结果如图4所示。

当初始距离小于0.75米时,几乎所有实验都能在0.8秒内收敛到附近1厘米范围,短于指令发出至击球的典型时长(0.86秒)。这表明几乎所有情况下机器人都能在击球动作完成前到达基座期望位置。
此外,收敛时间随初始距离增加而增加,符合预期;且左右方向位移的收敛时间分布高度对称。这些结果证明了在仿真环境中全身控制器(WBC)策略的敏捷性。
真实环境
在真实场景中,全身控制器(WBC)策略同样展现出敏捷性,如图5所示。

机器人初始站在球台右侧,当球飞向左侧时,机器人快速反应,可以从球台右侧快速转移到左侧,同时保持平衡并成功击球。这种迅速的动作是通过指令控制基座位置实现。相比之下,其他全身控制器(WBC)策略采用速度指令时,机器人通常需执行更慢的多步横向移动。
对于上身摆臂动作,结合人类运动参考的训练使机器人生成了与人类高度相似的击球行为,例如击球时的腰部旋转。

2.3 真机实验
将HITTER部署在宇树G1人形机器人上后,向机器人投掷26个球,这些球在虚拟击球平面上的投影覆盖广泛区域,如图7。

机器人成功回接24个球,1个球击中但未打回去,1个球未击中,对应的击中率为96.2%,回球率为92.3%。此外,机器人y<0对方向的球倾向于使用正手击球,对y>0方向的球倾向于使用反手击球,这与人类乒乓球运动的习惯一致。
此外,该人形机器人还能与人类对手进行长时间对打,连续击球次数可达106次。对打时长超过人类休闲对打水平,表明机器人不仅能够可靠地跟踪并回球,还能在连续击球过程中保持平衡并准备下一次击球。实验如下demo所示。
3
总结
本论文中,UC伯克利团队提出分层系统HITTER,实现真实环境中人形机器人的乒乓球对打。该系统将“基于模型的规划器”与“基于强化学习的机器人全身控制器”分离,实现了亚秒级反应时间下的敏捷类人击球动作。将HITTER部署在宇树G1人形机器人上对机器人投掷乒乓球,击中率为96.2%,回球率为92.3%。与人类对手对打时连续击球次数可达106次,两台人形机器人还可自主实现持续对打,充分证明了该系统的鲁棒性与通用性。
END
智猩猩矩阵号各专所长,点击名片关注