
前不久,我们整理过一篇关于视觉-语言模型(VLM)的盘点,有朋友留言说希望能看看“VLM 在机器人里的下一步”。
其实这一步正是Vision-Language-Action(VLA):在 VLM 的感知与理解能力之上,进一步打通机器人真正的“手脚”,让它们不仅“能看能听”,还能“会做会执行”。

今天要和大家深入探讨的,正是今年8月刚发表的一篇聚焦大规模 VLM 驱动 VLA 模型的重磅综述,专门梳理了大规模 VLM 驱动的 VLA 模型,把两者结合起来讨论。
文章将现有研究划分为不同架构类型,并总结了它们如何在强化学习、世界模型、人类视频学习等方向上拓展。从谷歌DeepMind的RT系列,到MIT、斯坦福的各种创新探索——进行了系统的归纳、整理和提炼,
本文将会把视线聚焦在“VLM 如何成为 VLA 的地基”上:
VLM 提供了开放世界的感知和语义对齐能力,VLA 则把这些能力延伸到规划与控制,最终落到机器人操作。
接下来,我们就结合具身智能视角,一起拆解这份 “VLM+VLA 技术地图”。

总览
接下来,我们按照:基于 VLM 的 VLA 模型在机器人操作领域的发展脉络,展开盘点。

▲图2|基于大型 VLM 的视觉-语言-动作(VLA)模型在机器人操作领域的重要发展时间线。时间线突出了单体模型(绿色)与分层模型(黄色)的代表性里程碑,展示了该领域近阶段的关键进展©️【深蓝具身智能】编译
整体上,大规模 VLM 驱动的 VLA 模型主要可以分为两条技术路线:
1. 单体模型(Monolithic):强调端到端的一体化,把 VLM 的语义理解直接延伸到动作生成;
2. 层级模型(Hierarchical):把“规划”与“执行”显式拆开,用可解释的中间表示衔接认知与控制。
在此基础上,还有几条值得关注的扩展方向,比如:
如何用强化学习增强泛化?
如何借助人类视频来弥补数据缺口?
如何把世界模型引入 VLA 来提升长时序推理能力?
这里,我们再一起看看未来值得突破的新趋势。

▲图1|大型 VLM 驱动的视觉-语言-动作(VLA)模型在机器人操作中的核心优势示意图。基于大型视觉-语言模型(VLM)的 VLA 模型充分利用了 VLM 的能力,包括:(1) 开放世界的泛化能力;(2) 分层任务规划;(3) 知识增强型推理;(4) 丰富的多模态融合。这些能力为多种类型的机械臂提供支持,并显著提升了机器人的智能水平©️【深蓝具身智能】编译

VLM 驱动的 VLA 模型
单体模型
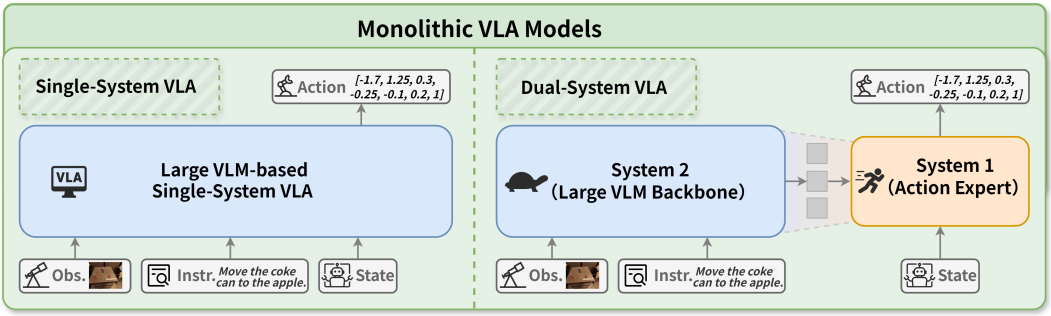
在所有 VLM+VLA 的探索中,单体模型(Monolithic)算是最直接的一条路线。
它的思路很简单:把视觉输入、语言指令和机器人状态统一送进一个大模型里,在同一个语义空间里完成“理解—推理—行动”的闭环。
这种方式继承了 VLM 的强大语义理解力,同时避免了复杂的模块拼接,看上去更“纯粹”,也更接近端到端的具身智能。
两种主要形态
单系统(Single-system):
所有信息都交给一个大模型处理,由它直接输出动作序列。RT 系列(RT-1、RT-2)就是经典代表:
它们把连续动作离散成 token,让语言、视觉和动作在同一个序列里建模;
再比如 OpenVLA,用更轻量的视觉编码器结合大规模机器人数据,降低了训练和部署门槛。
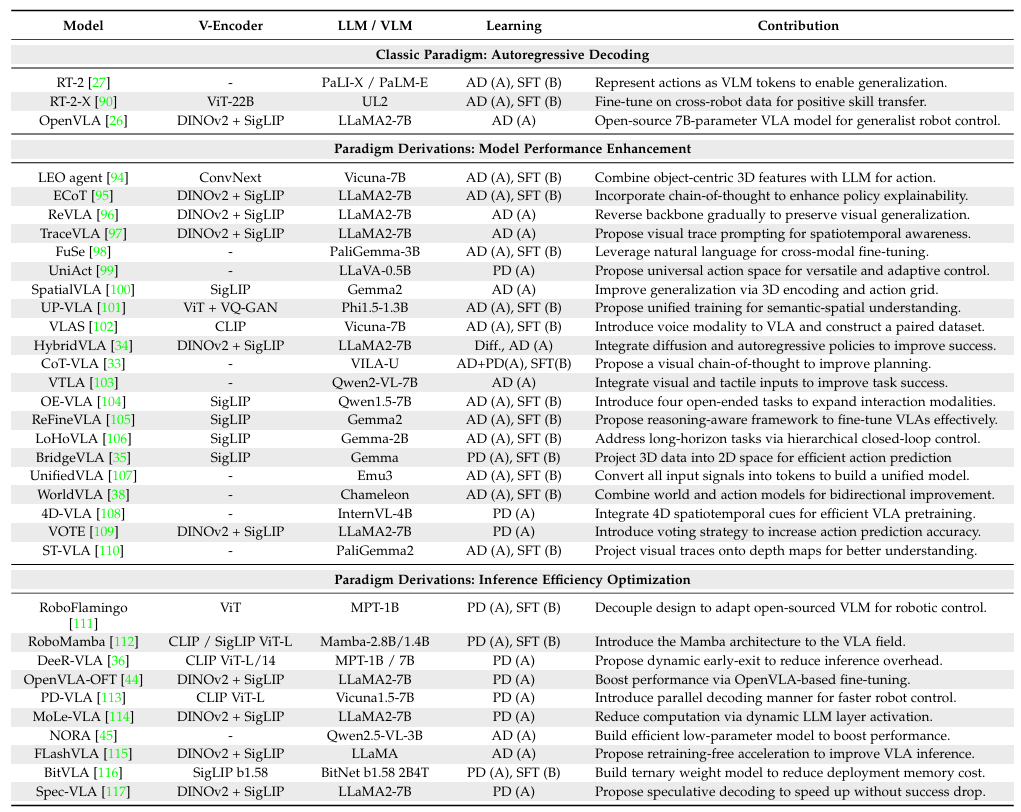
▲图3|单系统 VLA 模型代表作及其架构汇总;在 Learning 一栏中:“AD” 表示 自回归解码(Autoregressive Decoding);“PD” 表示 并行解码(Parallel Decoding);“SFT” 表示 微调(Supervised Fine-Tuning),与动作预测模仿学习不同,诸如图像描述(captioning)、视觉问答(VQA)、推理等任务都属于 SFT;括号中的 “A” 和 “B” 分别表示在动作头(Action head)或骨干网络(Backbone)中使用的学习方法©️【深蓝具身智能】编译
双系统(Dual-system):
在大模型之外挂一个轻量级的动作专家。大模型(System 2)负责语义理解和推理,动作专家(System 1)负责高频、低延迟的控制。
这样的组合既保留了 VLM 的强大认知能力,又能保证机器人在真实场景里不“卡顿”。

▲图4|双系统 VLA 模型代表作及其架构汇总;System1代表动作专家模型,System2代表大模型©️【深蓝具身智能】编译
三个关键提升方向
在单体模型的框架下,研究者们不断强化它的能力,主要集中在三个方面:
(1)感知能力升级
从二维走向三维:通过 Ego3D、点云、RGB-D 融合等方式,让模型拥有对真实空间的立体理解;
向四维拓展:结合轨迹、时间信息,把动作过程纳入推理,让模型能“看到物体在未来会怎么动”;
多感官输入:触觉、语音也被编码成 token 融入序列,机器人逐渐具备“多感官融合”的能力。
(2)推理能力增强
显式推理链(Chain-of-Thought):在执行动作前,先生成中间推理或视觉目标,减少短视与幻觉;
层级闭环控制:比如 LoHoVLA 采用分层反馈机制,能更好地处理长时序和外部干扰;
这些改进让单体模型从“反应型”逐渐走向“思考型”,更符合具身智能的长时序需求。
(3)泛化能力拓展
跨机器人泛化:通过统一动作码本(Universal Action Codebook),不同平台的动作都能在同一空间里对齐;
跨场景迁移:引入世界模型,让机器人学会物理规律,从而在新环境里少走弯路;
鲁棒性提升:引入动作投票、混合解码等机制,减少单次预测的偶然性,让动作更稳定。
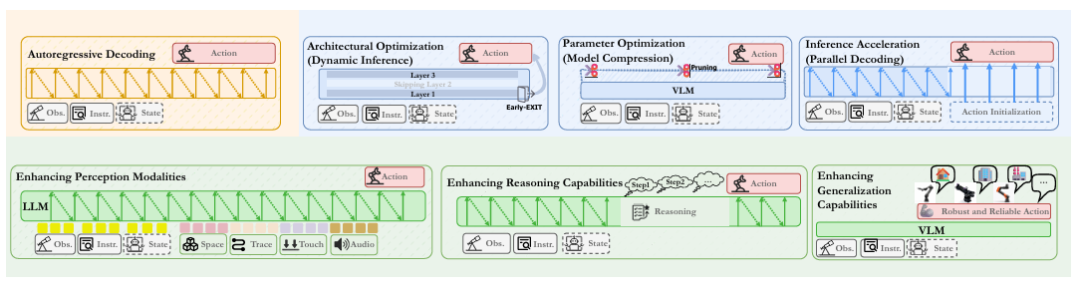
▲图5|单体模型框架提升方法举例;黄色展示了经典自回归解码的模型示意图,箭头表示信息流向。蓝色部分介绍了通过引入额外模态、利用链式推理(chain-of-thought)以及增强泛化能力等方式提升模型能力的方法。绿色部分介绍了通过架构优化、参数设计和解码策略等手段提升推理效率的结构©️【深蓝具身智能】编译
效率与部署的现实挑战
不过,单体模型也有“设计偏向理想化”的一面:模型庞大、推理速度慢,而机器人对实时控制的要求极高。
为此,很多工作尝试:
架构优化:动态路由、层级早退,减少不必要的计算;
模型压缩与量化:BitVLA 等通过 1-bit 权重压缩,把超大模型压缩到更易部署的版本;
解码加速:并行解码、投机解码等方法,把原本逐 token 的动作预测加速成“一次性生成”。
小结
单体模型就像具身智能的“理想派”:
追求统一,追求纯粹,力图用一个大模型覆盖感知—语言—动作的全链路。
它展示了 VLM 如何直接进化为 VLA,让机器人第一次拥有“看懂就能做”的可能性。但要真正走进日常应用,还需要在效率、可控性和安全性上继续补课。

层级模型
和单体模型的“端到端”不同,层级模型(Hierarchical)更强调把“想”和“做”拆开。
它通常由两个模块组成:高层的 Planner(规划器) 和低层的 Policy(控制器)。
Planner 接收视觉和语言输入,先生成人类可解释的中间表示,比如关键点、子任务、或程序片段;
Policy 再把这些中间表示转化为轨迹和动作,从而完成执行。

▲图6|层级模型的示意图;这些模型根据其结构分为两大类:仅规划器(Planner-Only)和规划器+策略(Planner+Policy)。根据中间表示类型的不同,其中一类模型还可以进一步细分为三种:基于子任务的(S,subtask-based)基于关键点的(K,keypoint-based)基于程序的(P,program-based)©️【深蓝具身智能】编译
这种设计方式的意义在于:
VLM 的角色更清晰:
它主要承担高层认知和推理任务,把复杂的自然语言和视觉信息转化为结构化的中间表达;至于低层的高频控制,则交给更轻量、更高效的模块。
这样既能利用 VLM 的“世界知识”,又能保证机器人在真实环境下的反应速度。
可解释性与安全性更强:
中间表示往往是人类可以直接理解的,比如“找到杯子—抓住把手—放到架子上”。这使得整个流程透明可控,方便调试,也能和传统机器人流水线(规划器+控制器)很好衔接。
根据中间表示的不同,层级模型主要有三类:
程序型
直接生成代码或 API 调用。
比如一些模型会输出 Python 程序来调动机器人动作库,或者生成辅助性程序结构,交给执行模块去解析。
这类方法和软件工程结合紧密,可扩展性好。
关键点型
生成目标位置、接触点或轨迹关键帧。
比如模型能从“打开抽屉”的指令中识别出把手的位置,并生成一条可执行的路径。
这类方式天然贴近机器人操作中的“空间语义”,对复杂三维场景尤其实用。
子任务型
把高层目标拆解为一系列可执行的小任务。
例如“收拾桌子”会被拆解为“拿起杯子—放入水槽—整理书本”。
这种方式适合长时序、多阶段的任务,能显著提升完成率。
在一些更进阶的设计中,Planner 和 Policy 是紧密结合的,即 Planner+Policy 结构。Planner 生成子任务或关键点,Policy 直接据此执行。
比如 HiRobot 会先把开放指令分解成原子级命令,再由 Policy 完成动作;DexVLA 和 PointVLA 则通过加入点云和扩展感知能力,让低层执行器在复杂几何环境下也能准确跟随 Planner 的意图。
相关阅读:美的最新成果|PointVLA代码+原理解析:超轻量VLA融合3D点云新范式,成功率提升50%!

▲图7|层级式 VLA 模型代表作及其架构汇总©️【深蓝具身智能】编译
在 “Type” 一栏中表示规划器(planner)的输出类型:
“K” 表示 关键点(Keypoint);“S” 表示 子任务(Subtask);“P” 表示 程序(Program);
在 “Learning” 一栏中表示模型采用的学习方法:
“SFT” 表示监督微调(Supervised Fine-Tuning);“RL” 表示强化学习(Reinforcement Learning);“IM” 表示模仿学习(Imitation Learning);“API” 为特殊情况,表示调用已有模型(pre-existing models) 的方法
小结
层级模型更像是具身智能的“工程派路线”:
它追求透明、稳健、可扩展。
对安全性要求高的场景(工业装配、医疗机器人),或对长时序任务有要求的应用(家庭服务、复杂协作),层级模型都更有优势。

相比之下,单体模型适合做能力探索,而层级模型则更容易走向真实落地。

其他前沿方向
除了单体模型和层级模型,还有一些探索方向正在快速涌现,它们让 VLM+VLA 框架逐渐具备更强的泛化力和更贴近现实的操作能力。
这些方向上的一些代表作我们在往期的文章中也有过详细的解读,下文一并为大家附上了链接,感兴趣的读者可以进一步作延伸阅读~
强化学习(RL)的加持
单靠模仿学习,模型很容易在长时序任务里“半途而废”。
于是研究者尝试用 RL 给 VLA 增强“试错”能力:比如设计更密集的奖励信号、结合人类反馈,甚至把 VLM 当作“奖励模型”,为机器人提供更智能的评判。
这让机器人在复杂环境里学会自我纠错,执行任务更稳健。
相关阅读:突破传统 RL 局限!首个新型强化学习框架:靠隐式反馈革新「人机协作」

无训练的轻量改进
有些方法并不重新训练大模型,而是通过架构优化或推理调度来提速。
比如剪枝、缓存、动态早停,甚至只在任务关键帧运行完整推理,其余时候走轻量路径。这类方法虽然不改变模型能力,但极大降低了部署成本,让 VLM+VLA 更容易跑在资源有限的机器人上。
学习人类视频
人类每天的操作视频就是“免费教材”。
通过对齐人类与机器人的交互模式,VLA 模型能够在海量视频里学到泛化的操作逻辑——比如“如何端起杯子”“如何开关抽屉”。
这类方式帮助机器人跨越“具身差距”,哪怕真实机器人数据有限,也能借助人类经验快速提升。
OpenDriveLab团队负责人李弘扬老师,将在ARTS 2025对UniVLA工作展开进一步报告分享


相关阅读:AGI关键拼图!(附实现代码)智驾传奇团队再出手:UniVLA 打造机器人通用行动指南
世界模型的引入
传统的 VLA 更像“看到就做”,缺乏对未来的预判。
而加入世界模型后,机器人能在心里“想象未来场景”——比如模拟抓取失败后的后果,再重新规划。
这类方法让 VLM+VLA 具备了更强的长时序推理和物理一致性,尤其适合需要提前规划的任务。
这些探索方向其实是在给 VLM+VLA 补齐短板:RL 让它更能自我纠错,无训练优化让它更能落地,人类视频带来知识迁移,世界模型则增强了未来感知力。
它们共同推动机器人从“能理解、能行动”,逐渐走向“更聪明、更稳健、更可部署”的具身智能。
相关阅读:首个!阿里巴巴达摩院:世界模型+动作模型,给机器人装上「预言&执行」双引擎

▲图8|其它前沿方向代表性的 VLA 方法汇总©️【深蓝具身智能】编译
对于这四种常见的前言方向,大家也可以通过上图了解每个方向上的代表性工作。

未来展望与总结
整体来看,大规模 VLM 与 VLA 的结合,为机器人打开了一条全新的道路:
单体模型走的是端到端一体化的理想路线,追求纯粹和统一;
层级模型则更偏向工程化,把复杂任务拆解成规划与执行的分工合作;
而强化学习、人类视频学习、世界模型等方向,则在不断补足泛化、数据、长时序推理这些短板。
站在具身智能的角度,这意味着什么?
(1)机器人操作将更具开放性:过去只能处理特定场景、特定任务的机器人,未来有机会真正走进开放世界。
(2)人与机器的交互更自然:自然语言指令和视觉场景的结合,让机器人更好地理解“人话”,而不是依赖模板化命令。
(3)跨平台迁移更轻松:统一的动作表示和世界模型的引入,有望让机器人跨环境、跨形态地学习和执行任务。
(4)从被动执行到主动探索:具备记忆、预测和推理的机器人,不再只是“执行器”,而是能在复杂环境中自主制定和调整策略的智能体。
没错,VLM+VLA 的结合正在让“具身智能”这四个字从概念变得更可触摸。未来的关键挑战,一方面在于如何让这些大模型真正跑在资源受限的机器人上,另一方面则是如何保证它们在开放环境里的安全性与可靠性。
不知道各位读者目前最想了解的方向是什么?是世界模型与机器人,还是多模态感知下的具身智能?欢迎在评论区留言。
编辑|阿豹
审编|具身君
Ref
论文题目:Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
论文作者:Rui Shao, Wei Li, Lingsen Zhang, Renshan Zhang, Zhiyang Liu, Ran Chen, Liqiang Nie
论文地址:https://arxiv.org/pdf/2508.13073
项目地址:https://github.com/JiuTian-VL/Large-VLM-based-VLA-for-Robotic-Manipulation
VLM盘点:一文读透 | 从 VLN 到 VLA,研究成果井喷的 VLM 才是具身智能的隐藏王牌?
工作投稿|商务合作|转载
:SL13126828869(微信号)
>>自主机器人技术研讨会早鸟报名【倒计时 6 天】<<

为促进自主机器人领域一线青年学者和工程师的交流,推动学术界与企业界的深度交融与产学研合作,中国自动化学会主办了自主机器人技术研讨会(Autonomous Robotic Technology Seminar,简称ARTS)。
基于前两届大会的成功经验和广泛影响,第三届ARTS将继续深化技术交流与创新,定于2025年10月18日-19日在杭州举办。我们诚挚邀请您参加,并欢迎您对大会组织提供宝贵意见和建议!


【具身宝典】具身智能主流技术方案是什么?搞模仿学习,还是强化学习?|看完还不懂具身智能中的「语义地图」,我吃了!|你真的了解无监督强化学习吗?3 篇标志性文章解读具身智能的“第一性原理”|解析|具身智能:大模型如何让机器人实现“从冰箱里拿一瓶可乐”?|盘点 | 5年VLA进化之路,45篇代表性工作!它凭什么成为具身智能「新范式」?动态避障技术解析!聊一聊具身智能体如何在复杂环境中实现避障
【技术深度】具身智能30年权力转移:谁杀死了PID?大模型正在吃掉传统控制论的午餐……|全面盘点:机器人在未知环境探索的3大技术路线,优缺点对比、应用案例!|照搬=最佳实践?分享真正的 VLA 微调高手,“常用”的3大具身智能VLA模型!机器人开源=复现地狱?这2大核武器级方案解决机器人通用性难题,破解“形态诅咒”!|视觉-语言-导航(VLN)技术梳理:算法框架、学习范式、四大实践|盘点:17个具身智能领域核心【数据集】,涵盖从单一到复合的 7 大常见任务类别||90%机器人项目栽在本地化?【盘点】3种经典部署路径,破解长距自主任务瓶颈!|VLA模型的「核心引擎」:盘点5类核心动作Token,如何驱动机器人精准操作?
【先锋观点】周博宇 | 具身智能:一场需要谦逊与耐心的科学远征|许华哲:具身智能需要从ImageNet做起吗?|独家|ICRA冠军导师、最佳论文获得者眼中“被低估但潜力巨大”的具身智能路径|独家解读 | 从OpenAI姚顺雨观点切入:强化学习终于泛化,具身智能将不只是“感知动作”
【非开源代码复现】非开源代码复现 | 首个能抓取不同轻薄纸类的触觉灵巧手-臂系统PP-Tac(RSS 2025)|独家复现实录|全球首个「窗口级」VLN系统:实现空中无人机最后一公里配送|不碰真机也不仿真?(伪代码)伯克利最新:仅用一部手机,生成大规模高质量机器人训练数据!
我们开设此账号,想要向各位对【具身智能】感兴趣的人传递最前沿最权威的知识讯息外,也想和大家一起见证它到底是泡沫还是又一场热浪?
欢迎关注【深蓝具身智能】👇

【深蓝具身智能】的内容均由作者团队倾注个人心血制作而成,希望各位遵守原创规则珍惜作者们的劳动成果。
投稿|商务合作|转载:SL13126828869(微信)

点击❤收藏并推荐本文










