
不需要动作预训练,即可同时实现未来视频预测与一致的动作轨迹生成。
作者丨拓元智慧AI团队

该论文作者来自中山大学、拓元智慧AI实验室团队,项目负责人为王广润博士。王广润,国家级“四青人才”、拓元智慧首席科学家、中山大学计算机学院副教授、博士生导师、华为战略研究院人才基金获得者、前牛津大学研究员,主要研究方向包括新一代AI架构、大物理模型、多模态生成式AI等。

论文题目:Physical Autoregressive Model for Robotic Manipulation without Action Pretraining
论文链接:https://arxiv.org/abs/2508.09822
项目主页:https://hcplab-sysu.github.io/PhysicalAutoregressiveModel/
近日,由中山大学、拓元智慧AI实验室联合提出的全新“物理自回归模型(Physical Autoregressive Model,PAR)”打通了“预判未来视频帧—生成动作轨迹”的统一链路,将视觉帧与动作共同编码为“物理token”,在无需动作预训练的前提下即可学习物理世界的动态规律。基于ManiSkill基准,PAR 在PushCube任务上实现100%成功率,并在其余任务上与需要动作预训练的强基线表现相当,显示了从大规模视频预训练向机器人操控迁移的可行路径。
四大核心技术点:
全局记忆的自回归框架:构建从过去到现在的所有“观察-动作”历史,借鉴GPT等语言模型的工作模式,基于全部N个历史token预测下一步(N+1步)最合理的行动。
统一的“物理token”表征:将帧与动作拼接为一个序列单元,直接建模机器人与环境的联合演化;模型以自回归方式逐步预测下一步视频与动作。
连续空间的DiT去分词器(de-tokenizer):以扩散Transformer(DiT)建模帧与动作的连续分布,避免离散量化带来的误差累积,并促进两模态的相互增强。
面向控制的因果掩码与效率机制:引入“动作对帧的单向注意力”,形成隐式逆运动学;同时结合并行训练与KV-cache提升推理效率。

01
在机器人操控领域,获取大规模、标注完备的人类示教数据成本高昂。现有不少方法把语言大模型用于行动策略,但文本与动作模态之间存在天然鸿沟。相比之下,自回归视频生成模型天生擅长“基于过去预测未来”,与动作生成的目标更一致,因此成为迁移“世界知识”的理想载体。
此外,要让机器人“知行合一”,不仅要“想得明白”,更要“做得精准”。现有的方法往往只依赖于“当前帧+前一帧”的“局部观察”,缺乏对长程历史的记忆。与之相比,具备全局记忆的自回归框架,可通过历史全量token预测未来状态,实现“视觉-动作”的全局关联建模,有效降低机器人在动态场景中(如机器人抓取、物体堆叠)因“短视”导致的“动作漂移”问题。

02
方法:PAR 如何把“看见的未来”变成“下一步动作”
整体框架:从“看—想—做”的自回归闭环
PAR 的核心想法是把机器人与环境的交互过程,统一描述成一串“物理token”。每个 token 同时包含这一刻的视觉画面和动作片段。模型像讲故事一样按时间读入这些token,用一个因果式Transformer形成对当前情境的理解,然后同时预测下一张将看到的画面以及下一步要执行的动作。新的画面和动作再被接回序列,进入下一轮预测,形成“预测—执行—再预测”的闭环。
直观地说,PAR并不是先独立学会“看视频”,再额外学会“怎么动”,而是把两件事合在一起、每一步都边看边想边做。这种端到端的整体建模,避免了两阶段方法常见的分布偏移,也更贴近真实控制场景里“在行动中不断校正”的节奏。

图1:整体框架:从“看—想—做”的物理自回归闭环
生成细节:在“连续空间”里同时生成视频与动作
传统做法常把视频和动作先量化成离散码,再去预测,这会引入不可忽略的量化误差。PAR 选择在连续空间里直接建模:
统一条件,双分支生成。 上述 Transformer 得到的“情境表示”被同时送入两个生成器:一个负责“把下一张画面逐步复原出来”(视频分支),另一个负责“把下一段动作逐步生成出来”(动作分支)。两个分支共享同一份条件,因此在训练时能彼此约束、相互增强——看到的未来会直接影响该怎么动,反过来更合理的动作也会促使画面预测更贴近真实。
逐步细化,贴近真实。 两个分支都采用逐步细化的生成方式(多步从粗到细),这让结果更加平滑、细节更真实,尤其适合对轨迹连续性和视觉连贯性都很敏感的机器人任务。
轻量动作解码器。 动作本身维度较低,采用更轻量的生成器即可稳定产出可控、平滑的控制量,便于在线部署。
注意力与控制:时间因果 + 帧内双向 + 动作←视觉单向
为把“预测未来”和“生成动作”真正做成控制器可用的能力,PAR 在注意力结构上加入了三条关键约束:
时间因果。 跨时间维度只能“看过去、不能看未来”,保证推理时与真实执行一致,避免“偷看答案”。
帧内双向。 同一帧内部,图像的各个区域可以相互关注,让模型准确理解目标、障碍和机械臂之间的空间关系,从而把下一张画面预测得更可信。
动作←视觉的单向通道。 当前步待预测的动作可以关注同一时刻待预测的视觉表示,但反过来不行;直觉上,这等价于在网络里植入一种“从期望实现的外观与相对位置反推该怎么动”的先验(可把它理解为一种隐式逆运动学)。这使得动作更紧贴关键像素区域(例如方块或目标区),减小偏差累积。
在工程层面,推理时配合KV-cache等增量计算,只对新增的 token 计算注意力,长序列滚动的时延增长更可控,适合在线控制。

03
主要评测结果:在maniskill基准中,PAR在PushCube达到100%成功率,总体成绩居第二,仅次于需要动作预训练的RDT;在PickCube与StackCube上也超过或接近需要动作预训练的强基准方法(总体平均74%)。
对齐与可解释性:如图2所示,可视化显示预测视频与实际执行在关键动作时序与轨迹上高度一致;如图3所示,注意力图表明不同头会在帧/动作token与关键像素区域(方块、目标区、机械臂)之间进行有针对性的聚焦。

图
2:预测视频与实际执行关联可视化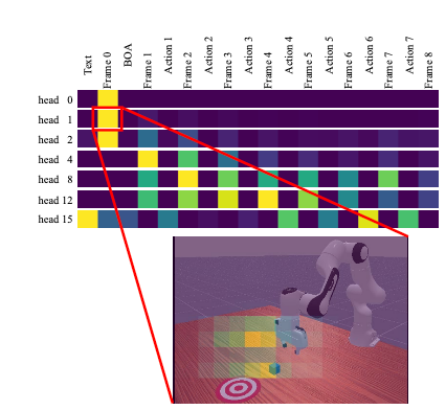
图3:注意力图
PAR证明了“从视频世界迁移物理知识”用于机器人操控的有效性:不需要动作预训练,即可同时实现未来视频预测与一致的动作轨迹生成,为解决示教数据稀缺提供新路径。



未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。
未经「AI科技评论」授权,严禁以任何方式在网页、论坛、社区进行转载!
公众号转载请先在「AI科技评论」后台留言取得授权,转载时需标注来源并插入本公众号名片。










