该论文发表于中国人工智能学会(CAAI)的B类推荐期刊IEEE Transactions on Neural Systems and Rehabilitation Engineering(中科院康复医学一区,IF=5.2),题目为《A Progressive Multi-Domain Adaptation Network with Reinforced Self-Constructed Graphs for Cross-Subject EEG-Based Emotion and Consciousness Recognition》。
华南师范大学人工智能学院陈荣滔为此文的第一作者,华南师范大学人工智能学院潘家辉教授为通讯作者。
论文链接:
https://ieeexplore.ieee.org/document/11142795

论文概要
今天,我们要介绍的是一项新的研究成果——一种基于强化自构图渐进式多域适应网络的跨被试脑电(EEG)情感识别和意识检测方法。这个方法听起来可能有点复杂,但它的核心思想和实现过程却非常精妙,接下来就让我们一起揭开它的神秘面纱。这项工作提出了一种基于强化自构图渐进式多域适应网络的跨被试脑电(EEG)情感识别和意识检测方法。该方法首先引入EEG-CutMix构建混合域数据进行数据增强,接着通过强化自构图模块(RSCG)来提取域不变特征,最后构建渐进式多域适应框架(PMDA)进行个体之间的数据分布平滑对齐。这种方法不仅有效提取了域不变特征,还保留了与情绪相关的信息,同时对齐了不同个体之间数据的联合概率分布,并成功应用于情感识别和意识障碍(DOC)患者的意识水平评估。

研究背景
脑电(EEG)信号,作为大脑神经活动的直接映射,为我们打开了一扇窥探情绪与意识状态的窗口。在临床诊断与人机交互领域,准确解读情绪至关重要,尤其是在评估意识水平时,有效的情绪反应能为判断是否存在残余意识提供关键的客观依据。然而,传统的行为量表评估方法(CRS-R)易因患者运动功能受损而产生误判,而面部表情、语言等情绪识别依据又主观性强、可靠性有限,且不适用于有表达障碍的人群。相比之下,EEG信号为情绪识别提供了一个更为客观、可靠的技术路径。但基于脑电的识别仍面临一个核心瓶颈:每个人的大脑活动模式都独一无二,导致为单个被试训练的模型难以直接适用于他人。因此,开发一种能克服个体差异、实现精准情绪识别的通用模型,已成为该领域亟待突破的关键。

方法
该论文提出了一种基于强化自构图渐进式多域适应网络的跨被试情感识别和意识检测方法.该方法主要由三个部分组成:EEG-CutMix数据增强,强化自构图模块和渐进式多域适应框架。
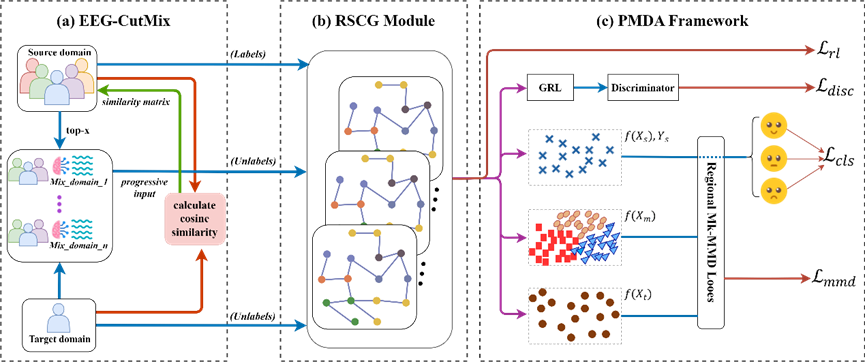
图1 模型整体框架
(1) EEG-CutMix数据增强:
首先,模型将原始的二维EEG张量数据进行“扁平化”处理,转化为一维向量。接着,针对一个选定的目标域样本,模型会遍历所有源域样本,并计算彼此间的余弦相似度,以量化其生理特征的接近程度。最后,通过“截断排序”策略,模型会找到最高的相似度分数值,并以此为基准设定一个动态阈值,所有相似度分数超过该阈值的源域样本都将被选中,从而构成一个高质量的候选池。接着进行动态剪切混合,模型从候选池中选取一个源域样本,并随机选择一个时间点τ进行切割。它将目标域样本从开始到τ时间点的部分,与源域样本从τ到结尾的部分进行逐通道拼接。这种“通道保留式”的拼接方式,能够在混合时序信息的同时,完整地保留EEG信号至关重要的多通道空间结构。最后,进行多强度高斯噪声注入,模型会向新生成的混合样本中注入与信号自身能量成比例的高斯噪声,提升模型的鲁棒性,进一步丰富数据多样性。
(2) 强化自构图模块:
首先将源域、目标域和混合集的EEG信号传入三个并行的卷积神经网络,提取不同尺度的EEG信号特征。这些初步提取的特征随后被送入一个“瓶颈层”进行压缩和精炼,最终为图中的每一个节点生成一个高信息密度的特征向量。接着进行强化学习图构建,模型将图的构建视为一个需要学习的决策过程,一个策略网络会接受任意两个节点的特征向量作为输入,并计算它们之间应该存在连接的概率。同时,为了确保生成图的质量,模型采用了一种双重筛选标准来构建最终的邻接矩阵。一条边必须同时满足两个条件才能存在:第一,它必须通过强化学习策略网络的概率阈值筛选,即被认为是高概率存在的连接;第二,它必须在节点特征相似度上排名前K(top-K),即两个节点在功能上高度相关。这种严格的机制保证了图结构的稀疏性和有效性。最后,进行模型奖励和优化,模型每构建一次图,都会根据一个综合了分类准确性和图连通性的奖励函数进行自我评估。如果构建的图能带来高奖励,模型就会通过策略梯度算法进行优化,从而增加未来构建类似图的概率。在学习到最优的邻接矩阵后,模型会执行标准的图卷积操作,通过聚合相邻节点的信息,最终输出一组包含丰富时空连接信息的过渡特征。
(3) 渐进式多域自适应框架:
该框架旨在确保模型学到的知识能有效、平滑地从源被试迁移到目标被试。在训练初期,模型主要专注于学习有标签的源域数据。随着训练轮次的增加,一个“进程比例”参数会逐渐增大,系统随之动态地、逐步地将越来越多的混合域与目标域数据引入训练过程。整个训练由一个复杂的多目标损失函数指导,该函数精妙地整合了分类损失、MMD损失、对抗损失与强化学习损失四大优化目标。通过最小化这个综合性的总损失,模型被驱动去协同优化所有任务,实现知识的平滑迁移。
图2 RSCG具体细节

实验结果
(1) 数据集:
研究使用了两个国际公认的公开情感EEG数据集SEED和SEED-IV,以及一个自采的情感EEG数据集。其中,SEED和SEED-IV数据集分别包含15名健康被试,自采数据集则包含了10名健康被试和12名意识障碍患者的数据。
(2) 实验设置:
模型以差分熵特征作为输入。为了严格评估模型的跨被试泛化能力,所有实验均采用留一被试法(LOSO)交叉验证策略。即每次将一名被试的全部数据作为测试集,其余所有被试的数据作为训练集,并重复该过程直到所有被试都被测试过一次。
(3) 实验结果与分析:
该模型在多个高标准数据集上均表现出卓越的性能,验证了其有效性与先进性。在国际通用的SEED和SEED-IV情感数据集上,该模型的跨被试情绪识别准确率分别达到了97.03%和88.18%。如表1和表2所示,这一成绩显著优于目前已有的所有方法,证明了其强大的泛化能力和顶尖水平。从训练过程来看,模型的学习效率极高,其AUC分数在训练初期便迅速收敛至高位。最终在测试集上,模型的宏平均ROC分数在SEED数据集上达到了0.983,在SEED-IV数据集上达到了0.961,进一步印证了其出色的分类性能。
表1 在SEED上使用LOSO交叉验证模型性能

表2 在SEED-IV上使用LOSO交叉验证模型性能

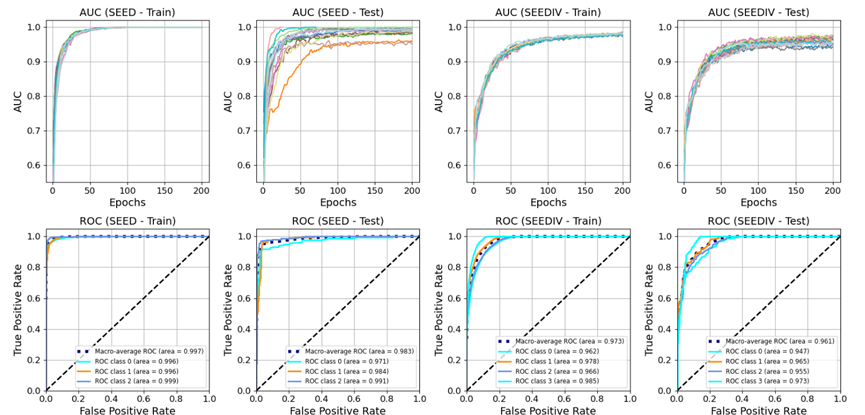
图3 不同数据集的AUC曲线和ROC曲线
在对10名健康被试和12名DOC患者的自采数据集测试中,如表3所示,模型在健康被试中取得了86.65%的高平均准确率。更为重要的是,在12名DOC患者中,有4名患者(包括1名临床诊断为植物状态的患者)的情绪识别准确率显著高于随机水平(均超过70%)。这一结果为他们拥有残余意识提供了有力的电生理学证据,这也与后续的临床观察结果相符,进一步验证了方法的有效性。
表3 在健康个体上使用LOSO交叉验证的情绪识别准确率和P值

表4 在DOC患者上使用LOSO交叉验证的情绪识别准确率和P值


结论
该论文提出的“渐进式多域自适应网络”,通过数据增强、自构图和渐进式迁移三项新设计,成功攻克了跨被试EEG情绪识别的核心难题。其在公开数据集上的顶尖表现和在意识障碍患者评估中的成功应用,不仅为脑机接口领域提供了新的技术范式,也为临床意识科学的探索和诊断开辟了充满希望的新道路。未来的工作将在更广泛的数据集上对该方法进行验证,并进一步优化模型,以更好地应对复杂的临床应用场景。
撰稿人:陈荣滔
审稿人:潘家辉


脑机接口与混合智能研究团队



团队主页
www.scholat.com/team/hbci