

要理解AI,先要理解它何以不确定,由OpenAI前CTO Mira Murati创办的Thinking Machines 开山之作来了,刚刚,Thinking Machines Lab 宣布正式上线技术研究博客:连接主义。开篇就是万字技术雄文《击败LLM推理中的非确定性(Defeating Nondeterminism in LLM Inference)》

为什么叫“连接主义”?这其实是个致敬梗。来自上世纪80年代,当时研究神经网络的那群先驱者们,就是用这个词来命名探索人造大脑的领域的,Thinking Machines非常良心,没有学CloseAI,坚持开源,以后大家可以在联结主义博客里看到各种各样的话题,从硬核的底层计算,到好玩的提示词技巧,应有尽有,另外北大校友,OpenAI 前安全副总裁,Thinking Machines 联合创始人LiLian Weng 爆料,公司第一个旗舰产品命名为“连接机器”

LLM有个共同的毛病就是同一个问题,再次询问时可能给出不同的回答,没有可复现性,这好像不是个问题,大家都习以为常了
Thinking Machines Lab 的这篇文章对LLM不确定性进行了研究,发现几乎所有 LLM 推理端点之所以非确定性,主要原因在于负载(并因此导致批次大小)的非确定性变化!
这个洞见瞬间颠覆了大家习以为常的视角。原来,困扰我们的随机性,并非源于计算核心的瑕疵,而是源于系统在应对动态负载时架构上的妥协。你的每一次请求,其结果都在被其他成千上万个并发请求无形地塑造着,纯粹是数学上的问题
文章中有一句话点出:“从推理服务器的角度,它是确定的;但从用户的角度,它是非确定的。” 这就像生活里那些看似公平的规则,当环境变量一变,体验到的却是另一回事。AI并没有撒谎,只是我们忽略了系统背后复杂的运行逻辑
更重要的是,文章没有停留在揭示问题,而是给出了系统性的解法:让核心算子实现批次不变性,从RMSNorm到矩阵乘法,再到注意力机制,逐步重塑内核的确定性。最终,Thinking Machines不仅在实验中实现了千次生成结果的完全一致,还为未来的在线策略强化学习打开了大门
blog:
可复现性是科学进步的基石。然而,要从大型语言模型中获得可复现的结果却异常困难。
例如,人们可能会观察到,多次向 ChatGPT 提出相同的问题会得到不同的结果。这本身并不奇怪,因为从语言模型获取结果涉及采样过程,该过程将模型的输出转换为概率分布,并据此概率性地选择一个词元(token)
但更令人惊讶的可能是,即使将温度(temperature)降至 0¹(从而使采样在理论上是确定性的),LLM API 在实践中仍然不是确定性的。即便使用像 vLLM 或 SGLang 这样的开源推理库在自己的硬件上运行推理,采样过程仍然不是确定性的
但为什么 LLM 推理引擎不是确定性的呢?一个常见的假设是,浮点数的非结合性(non-associativity)与并发执行共同导致了非确定性,具体结果取决于哪个并发核心先完成计算。本文将此称为 LLM 推理非确定性的“并发+浮点数”假说。例如,一篇近期的 arXiv 预印本文章写道:
GPU 中的浮点数运算表现出非结合性,即 (a + b) + c ≠ a + (b + c),这是由有限精度和舍入误差造成的。这一特性直接影响 Transformer 架构中注意力分数和 logits 的计算,其中跨多线程的并行操作会因执行顺序的不同而产生不同的结果。
尽管这个假说不完全错误,但它并未揭示全貌。例如,即使在 GPU 上,对相同数据重复运行相同的矩阵乘法,也总会得到逐位元(bitwise)相同的结果。这里确实使用了浮点数,GPU 也确实存在大量并发。那为什么在这个测试中看不到非确定性呢?
# python
A = torch.randn(2048, 2048, device='cuda', dtype=torch.bfloat16)
B = torch.randn(2048, 2048, device='cuda', dtype=torch.bfloat16)
ref = torch.mm(A, B)
for _ in range(1000):
assert (torch.mm(A, B) - ref).abs().max().item() == 0要理解 LLM 推理非确定性的真正原因,必须深入探究
不幸的是,即便是定义 LLM 推理的“确定性”也很困难。也许令人困惑的是,以下陈述全部同时成立:
1.GPU 上的某些核函数(kernels)是非确定性的
2.然而,语言模型前向传播(forward pass)中使用的所有核函数都是确定性的
3.此外,LLM 推理服务器(如 vLLM)的前向传播也可以声称是确定性的
4.尽管如此,从任何使用该推理服务器的用户的角度来看,结果都是非确定性的
在本文中,将解释为什么“并发+浮点数”假说未能抓住要点,揭示 LLM 推理非确定性背后的真正元凶,并说明如何击败非确定性,在 LLM 推理中获得真正可复现的结果
原罪:浮点数的非结合性
在讨论非确定性之前,有必要先解释一下为什么会出现数值差异。毕竟,通常认为机器学习模型是遵循交换律或结合律等结构规则的数学函数。难道不应该有一个“数学上正确”的结果,并且机器学习库就应该提供这个结果吗?
罪魁祸首是浮点数的非结合性。也就是说,对于浮点数而言:
(a + b) + c ≠ a + (b + c)
# python
(0.1 + 1e20) - 1e20
>>> 0
0.1 + (1e20 - 1e20)
>>> 0.1具有讽刺意味的是,打破结合律正是浮点数有用的原因。
浮点数之所以有用,是因为它们允许一种动态的精度水平。为了便于解释,这里将使用基数 10(而不是二进制),其中浮点数的格式为 尾数 * 10^指数。同时,假设尾数有 3 位数字,指数有 1 位数字
例如,对于数值 3450,可以精确表示为 3.45 * 10³。也可以表示像 0.486 这样小得多的值,即 4.86 * 10⁻¹。通过这种方式,浮点数可以同时表示非常小和非常大的值。在科学领域,可以说浮点数允许我们保持恒定数量的“有效数字”
如果将两个具有相同指数的浮点数相加,其过程类似于整数加法。例如,123 (1.23 * 10²) + 456 (4.56 * 10²) 的结果是 579 (5.79 * 10²)
但当两个指数不同的浮点数相加时,比如 1230 和 23.4,会发生什么呢?在这种情况下,精确结果是 1253.4。然而,一次只能保持 3 位数的精度。因此,浮点数加法会丢弃最后两位数字,得到 1.25 * 10³(即 1250)

图1:需要 3 位精度来表示 1230,3 位精度来表示 23.4。然而,将这两个数相加得到的结果需要 5 位精度来表示(1253.4)。浮点数格式必须丢弃末尾的 34。在某种意义上,这相当于在相加前将原始的 23.4 四舍五入到 20.0。
然而,到了这一步,信息已经被破坏了。请注意,每当将两个具有不同尺度(即不同指数)的浮点数相加时,都可能发生这种情况。而将不同指数的浮点数相加是常有的事。事实上,如果能保证永远不需要不同的指数,那直接使用整数就可以了
换句话说,每次以不同顺序对浮点数进行求和,都可能得到一个完全不同的结果。举个极端的例子,根据求和顺序的不同,对下面这个数组求和可能会产生 102 种不同的结果。
# python
import random
vals = [1e-10, 1e-5, 1e-2, 1]
vals = vals + [-v for v in vals]
results = []
random.seed(42)
for _ in range(10000):
random.shuffle(vals)
results.append(sum(vals))
results = sorted(set(results))
print(f"There are {len(results)} unique results: {results}")
# 输出:
# There are 102 unique results: [-8.326672684688674e-17, -7.45931094670027e-17, ...]尽管这是产生非相同输出的根本原因,但它并没有直接回答非确定性来自何处。它没能帮助我们理解为什么浮点值会以不同顺序相加,这种情况何时发生,以及如何避免
答案在于核函数(kernels)的实现方式
为什么核函数不总按相同顺序进行加法运算?
如上所述,关于核函数以不同顺序进行加法运算的一个常见解释是“并发+浮点数”假说。该假说认为,如果并发线程的完成顺序是非确定性的,并且累加顺序依赖于线程完成的顺序(例如使用原子加法),那么累加顺序也将是非确定性的。
令人困惑的是,尽管这确实会导致非确定性核函数,但并发(以及原子加法)最终与 LLM 推理的非确定性完全无关!为了解释真正的罪魁祸首是什么,首先来了解一下为什么现代 GPU 核函数很少需要原子加法
何时需要原子加法?
通常,GPU 会在许多核心(即 SMs)上并发地启动一个程序。由于这些核心之间没有内在的同步机制,如果核心之间需要通信,就会带来挑战。例如,如果所有核心都必须对同一个元素进行累加,可以使用“原子加法”(atomic add,有时也称为“fetch-and-add”)。原子加法是非确定性的——结果累加的顺序完全取决于哪个核心先完成。
具体来说,想象一下用 100 个核心对一个 100 元素的向量进行规约(reduction,例如 torch.sum())。虽然可以并行加载所有 100 个元素,但最终必须将它们规约成一个单一元素。实现这一目标的一种方法是使用某种“原子加法”原语,硬件保证所有加法都会被处理,但不保证处理顺序

图2,原子加法确保每个核心的贡献都会反映在最终的总和中。然而,它不保证贡献被添加的顺序。这个顺序完全取决于哪个核心先完成,这是一个非确定性的属性。因此,多次执行同一个并行程序可能会导致非确定性的输出。
这通常就是人们所说的非确定性——用完全相同的输入两次执行同一个核函数,却得到了不同的输出。这被称为逐次运行非确定性(run-to-run nondeterminism),即两次运行完全相同的 Python 脚本(具有完全相同的依赖项),但得到的结果不同。
尽管并发的原子加法确实会使核函数非确定性,但绝大多数核函数并不需要原子加法。事实上,在 LLM 的典型前向传播中,通常一个原子加法都没有
这可能令人惊讶,因为并行化规约可以从原子加法中受益。原子加法最终之所以非必需,主要有两个原因:
1.通常在“批次”维度上有足够的并行性,因此不需要在规约维度上进行并行化。例如,假设不是规约一个 100 维的向量,而是在并行地规约 500 个向量。在这种情况下,可以在每个核心中规约一整个向量,让每个核心处理不同的向量
2.随着时间的推移,大多数神经网络库都采用了各种策略来实现确定性,同时不牺牲性能。例如,可以执行“分裂式”(或树形)规约,将 100 个元素的规约分解为五个 20 元素的规约(从而实现五路并行)。然后,为了合并剩余的五个元素,可以执行一个单独的“清理”规约(这个规约不是并行的,但因为它处理的元素足够少所以成本很低),或者利用一个信号量(semaphore)(它能确保每个并发的线程块以确定性的顺序进行累加)
由于这两个因素,对于绝大多数神经网络操作来说,避免原子加法带来的性能损失可以忽略不计
仍有一些常见的操作在避免原子加法时会有显著的性能损失。例如,PyTorch 中的 scatter_add (a[b] += c)。然而,在 LLM 中唯一常用到的是 FlashAttention 的反向传播
然而,LLM 的前向传播不涉及任何需要原子加法的操作。因此,LLM 的前向传播实际上是逐次运行确定性的。

图3,从推理服务器的角度来看,它是确定性的。给定完全相同的用户请求,它将总是提供相同的确定性输出。
维基百科写道:确定性算法是指,对于一个特定的输入,它将总是产生相同的输出。”在这种情况下,给定完全相同的输入(即推理服务器正在处理的完全相同的请求),前向传播总是会产生完全相同的输出
然而,前向传播本身是确定性的,并不足以保证包含它的系统是确定性的。例如,如果请求的输出依赖于并行的用户请求(例如 batch-norm),那会怎样?由于每个单独的请求无法知道并行的其他请求会是什么,从它们的角度来看,整个 LLM 推理也是非确定性的!
事实证明,请求的输出确实依赖于并行的用户请求。这并不是因为在批次之间泄露了信息——而是因为前向传播缺乏 “批次不变性” (batch invariance),导致请求的输出依赖于前向传播的批次大小。
批次不变性与确定性
为了解释批次不变性,让我们简化系统,只关注矩阵乘法。可以假设所有矩阵乘法的实现都是逐次运行确定性的。然而,它们并不是批次不变的。换句话说,当批次大小改变时,批次中的每个元素都可能得到不同的结果
从数学角度来看,这是一个相当不寻常的属性。矩阵乘法在批次中的每个元素上应该是独立的——批次中的其他元素以及批次的大小都不应影响特定元素的计算结果
然而,根据经验可以观察到,这并非事实
# python
import torch
torch.set_default_device('cuda')
B = 2048
D = 4096
a = torch.linspace(-1000, 1000, B*D).reshape(B, D)
b = torch.linspace(-1000, 1000, D*D).reshape(D, D)
# 通过取批次的第一个元素进行矩阵向量乘法
out1 = torch.mm(a[:1], b)
# 进行矩阵矩阵乘法,然后取批次的第一个元素
out2 = torch.mm(a, b)[:1]
print((out1 - out2).abs().max()) # tensor(1669.2500, device='cuda:0')注意,这是逐次运行确定性的。如果多次运行此脚本,它将确定性地返回相同的结果
然而,当一个非批次不变的核函数被用作更大推理系统的一部分时,该系统可能变得非确定性。当向一个推理端点发出查询时,服务器的负载量从用户的角度来看实际上是“非确定性”的。负载决定了核函数运行时的批次大小,从而改变了每个独立请求的最终结果!

图4,尽管推理服务器本身可以声称是确定性的,但对于单个用户而言,情况则不同。从单个用户的角度来看,其他并发用户不是系统的输入,而是系统的非确定性属性。这使得 LLM 推理从每个用户的角度来看是非确定性的。
如果将核函数不具有不变性的某个属性(即批次大小)与该属性的非确定性(即服务器负载)组合在一起,就会得到一个非确定性的系统。
换句话说,几乎所有 LLM 推理端点之所以非确定性,主要原因在于负载(并因此导致批次大小)的非确定性变化! 这种非确定性并非 GPU 所独有——由 CPU 或 TPU 提供的 LLM 推理端点也会有这个非确定性来源。
因此,如果想在推理服务器中避免非确定性,就必须在核函数中实现批次不变性。为了理解如何实现这一点,首先来看一下为什么核函数一开始就不具备批次不变性
如何使核函数具备批次不变性?
为了使 Transformer 实现批次不变,必须使其每个核函数都具备批次不变性。幸运的是,可以假设每个逐点(pointwise)操作都是批次不变的。因此,只需要关注涉及规约的 3 个操作——RMSNorm、矩阵乘法和注意力
方便的是,它们也按难度递增的顺序排列。每一个都需要一些额外的考虑才能在保持合理性能的同时实现批次不变性。先从 RMSNorm 开始
批次不变的 RMSNorm

图5:数据并行 RMSNorm,理想情况下,我们希望在并行化策略中避免核心之间的通信。实现这一点的一种方法是为每个批次元素分配一个核心,从而保证每个规约完全在单个核心内完成。这就是所谓的“数据并行”策略,因为我们只是沿着一个不需要通信的维度进行并行化。在这个例子中,有四行和四个核心,正好饱和了我们的核心。
RMSNorm 可以实现为:
# python
# x: [batch_size, hidden_dim]
# weight: [hidden_dim]
def rms_norm(x, weight):
return x * torch.rsqrt(torch.mean(x ** 2, dim=-1, keepdim=True)) * weight批次不变性的要求是,每个元素的规约顺序必须固定,与核函数的批次大小无关。注意,这并不意味着必须总是使用相同的规约策略。例如,如果改变规约的元素数量,即使规约策略改变,仍然可以是批次不变的
因此,只有当批次大小影响到规约策略时,才会破坏批次不变性。
让我们看一下 RMSNorm 的标准并行策略。通常,并行算法受益于最小化核心间的通信。因此,可以从一个策略开始,即为每个批次元素分配一个核心,如上图所示
增加批次大小并不会影响规约策略;如果 200 的批次大小为核函数提供了足够的并行度,那么 2000 的批次大小也绝对能提供足够的并行度。

图6:更大批次的数据并行 RMSNorm,将数据并行策略扩展到更大的批次是相当直接的——与其让每个核心处理一行,不如让每个核心顺序处理多行。这保留了批次不变性,因为每个批次元素的规约策略保持不变。
另一方面,减小批次大小可能会带来挑战。因为为每个批次元素分配一个核心,减小批次大小最终会导致核心数量多于批次元素,从而使一些核心处于空闲状态。
遇到这种情况时,一个优秀的核函数工程师会选择前一节提到的解决方案之一(原子加法或分裂式规约),以保持良好的并行性和性能。不幸的是,这会改变规约策略,从而使该核函数不具备批次不变性。

图7:分裂式规约 RMSNorm,如果批次大小很小,数据并行策略可能不再有足够的并行度来饱和核心。在这种情况下,将一个规约“分裂”到多个核心上可能更有效,从而充分利用 GPU。然而,这会失去批次不变性,因为不再以相同的顺序对每个元素进行规约。
最简单的解决方案是完全忽略这些情况。这并非完全不合理——小的批次大小意味着核函数可能执行得很快,因此性能下降可能不是灾难性的
如果非要优化这种情况,一种方法是始终使用一种即使在非常小的批次大小下也具有足够并行性的规约策略。这样的规约策略对于较大的批次大小会导致过多的并行性,但能让我们在整个尺寸范围内实现可观(但非峰值)的性能
批次不变的矩阵乘法
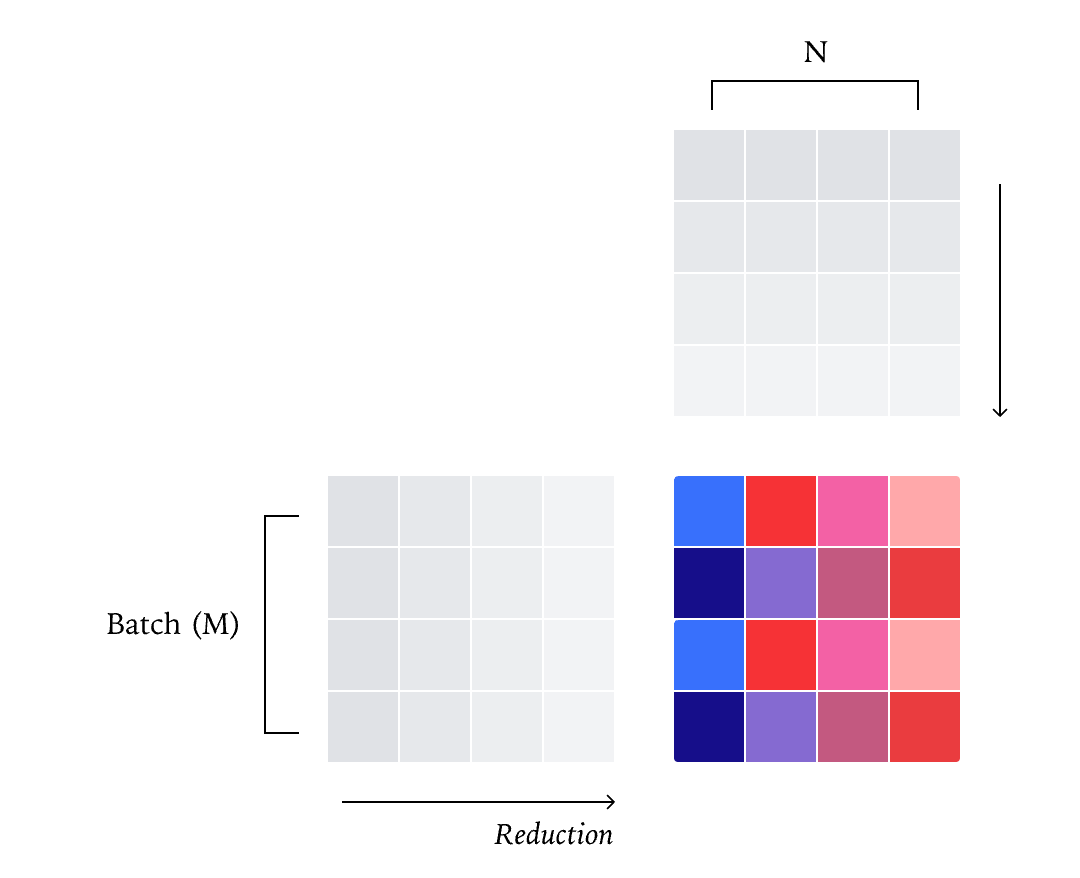
图8:数据并行矩阵乘法,与 RMSNorm 类似,矩阵乘法的标准并行策略是“数据并行”策略,将整个规约保持在一个核心内。
可以将矩阵乘法看作是一个逐点操作后跟一个规约。然后,如果通过将输出分块为多个瓦片(tile)来并行化矩阵乘法,就得到了一个类似的“数据并行”核函数策略,它将每个规约保持在一个核心内
也与 RMSNorm 类似,批次维度(M 和 N)可能变得太小,迫使我们在规约维度(K)上进行分裂。尽管有两个“批次”维度,矩阵乘法也需要每个核心有更多的工作量才能有效利用张量核心(tensorcores)。例如,如果有一个 [1024, K] x [K, 1024] 的矩阵乘法和一个标准的 [128, 128] 2D 瓦片大小,数据并行策略只能将这个矩阵乘法分解到 64 个核心中,不足以饱和 GPU
在矩阵乘法中沿规约维度进行分裂被称为 Split-K 矩阵乘法。就像 RMSNorm 一样,使用这种策略会破坏批次不变性¹⁰。

图9:Split-K 矩阵乘法,如果批次维度相当小,可能没有足够的并行性,需要进行 split-k 矩阵乘法。在这个例子中,我们将每个规约分裂到两个核心上,它们会分别累加,然后在最后合并它们的结果。然而,将每个规约分裂到两个核心上,使我们仍然可以利用八个核心。
矩阵乘法还有一个额外的复杂性——张量核心指令。对于规约,可以一次只操作一行,而高效的矩阵乘法核函数必须一次操作一整个“瓦片”
每个张量核心指令(例如 wgmma.mma_async.sync.aligned.m64n128k16)内部可能有不同的规约顺序。使用不同张量核心指令的一个原因可能是批次大小非常小。例如,如果使用一个操作 256 长度瓦片的张量核心 PTX 指令,但批次大小只有 32,那么几乎浪费了所有的计算!在批次大小为 1 时,最快的核函数通常根本不使用张量核心。

图10:填充的张量核心指令,如果批次大小太小,可能会出现我们甚至无法在输出中容纳一个 2D 瓦片的情况。在这种情况下,最有效的方法是切换到更小的张量核心指令或完全放弃张量核心!然而,这两种选择都会使核函数不具备批次不变性。
因此,确保矩阵乘法批次不变性的最简单方法是编译一个核函数配置,并将其用于所有形状。虽然会损失一些性能,但这在 LLM 推理中通常不是灾难性的。特别是,split-k 在 M 和 N 都很小时最需要,而幸运的是,在我们的案例中,N(即模型维度)通常非常大!

图11:性能对比图,尽管获得了批次不变性,与 cuBLAS 相比,性能仅损失约 20%。注意,这也不是一个优化的 Triton 核函数(例如,没有 TMA)。然而,性能图中的一些模式说明了批次不变性要求在何处损失了性能。首先,请注意在非常小的批次大小时,由于指令过大和并行性不足,性能损失显著。其次,随着批次大小增加,存在一个“锯齿状”模式,这是由量化效应(瓦片和波次)引起的,通常通过改变瓦片大小来缓解。
批次不变的注意力
在为矩阵乘法获得批次不变性之后,注意力引入了两个额外的复杂问题——恰如其名,因为它包含两个矩阵乘法。
1.与 RMSNorm 和矩阵乘法仅在特征维度上进行规约不同,现在需要在特征维度和序列维度上进行规约
2.由于上述原因,注意力必须处理各种影响序列处理方式的推理优化(如分块预填充、前缀缓存等)
因此,要在 LLM 推理中实现确定性,数值计算必须对一次处理多少个请求以及每个请求在推理引擎中如何被切分保持不变。
首先,来看一下注意力的标准并行策略,该策略首次在 FlashAttention2 中引入。与 RMSNorm 和 Matmul 类似,默认策略是数据并行策略。由于规约是在键/值(key/value)张量上进行的,数据并行策略只能在查询(query)张量上进行并行化。

图12:FlashAttention2 策略,沿着 Q 进行并行化,同时沿着 K/V 进行规约。这意味着整个规约可以保持在单个核心内,使其成为另一种数据并行策略。
例如,根据推理引擎的选择,一个序列可能会被分成几个部分进行处理(如在分块预填充中),或者可能一次性全部处理(如果预填充没有被分割)。为了实现“批次不变性”,一个给定词元的规约顺序必须不依赖于其序列中同时处理的其他词元的数量。如果在 KV 缓存中的 K/V 值与当前正在处理的词元的 K/V 值分开进行规约(如 vLLM 的 Triton 注意力核函数中那样),这是无法实现的。例如,在处理序列中的第 1000 个查询词元时,无论 KV 缓存中有 0 个词元(预填充)还是 999 个词元(解码),规约顺序都必须相同

图13:带 KV 缓存的 FlashAttention,为什么显式地分开处理 KV 缓存和当前的 KV 值会破坏批次不变性,原因有些微妙,与“边界条件”有关。具体来说,假设块大小为 32,但 KV 缓存中当前有 80 个元素。然后,我们计算另外 48 个未缓存的元素。在这种情况下,需要三个块(两个完整块和一个掩码块)来计算“P cache”,以及另外两个块(一个完整块和一个掩码块)来计算“P”。因此,总共需要五个块来计算规约,而我们总共只有四个块的元素(即 128)需要计算,这肯定会改变我们的规约顺序。
要解决这个问题,可以在注意力核函数本身之前更新 KV 缓存和页表,确保无论处理多少词元,键和值始终以一致的方式布局。
有了这个额外的细节(以及前一节提到的所有内容,如一致的瓦片大小),就能够实现一个批次不变的注意力!
然而,这里有一个重要问题。与矩阵乘法不同,在 LLM 推理中看到的注意力形状通常确实需要一个分裂式规约核函数,通常称为 Split-KV 或 FlashDecoding。这是因为如果不沿规约维度进行并行化,就只能沿批次维度、头维度和“查询长度”维度进行并行化。在注意力的解码阶段,查询长度非常小,因此除非有非常大的批次大小,否则通常无法饱和 GPU
不幸的是,像 RMSNorm 和 Matmuls 那样忽略这种情况并不容易。例如,如果有一个非常长的 KV 缓存,注意力核函数可能需要很长时间,尽管只处理一个请求

图14:固定数量的 Split-KV 策略(即 FlashDecode),如果查询长度变得非常小(如解码期间),核函数中的并行度可能会非常低。在这些情况下,需要再次沿规约维度进行分裂——这次是 KV 维度。如何沿 KV 维度分裂的典型策略是计算需要多少并行度,然后将 KV 维度平均划分。例如,如果 KV 长度为 1000,需要 4 个分裂,每个核心将处理 250 个元素。
这也不幸地破坏了批次不变性,因为精确的规约策略取决于在任何给定请求中正在处理的序列查询词元的数量
此外,常用于注意力的分裂式规约策略也给批次不变性带来了挑战。例如,FlashInfer 的平衡调度算法会选择能够饱和所有 GPU 核心的最大分裂尺寸,从而使规约策略不具备“批次不变性”。然而,与 RMSNorm/Matmuls 不同,仅仅选择一个固定的分裂数量而不考虑批次大小是不够的
相反,为了实现批次不变性,必须采用“固定分裂尺寸”策略。换句话说,不是固定分裂的数量,而是固定每个分裂的尺寸,最终得到可变数量的分裂。通过这种方式,可以保证无论正在处理多少词元,总是执行相同的规约顺序

图15:固定尺寸的 Split-KV 策略,此策略与前一个策略的唯一区别在于,分裂现在是“固定尺寸”的。例如,如果 KV 长度为 1000,与其将其分成四个长度为 250 的均匀分裂,不如将其分成三个固定尺寸长度为 256 的分裂和一个长度为 232 的分裂。这使我们能够保留批次不变性,因为规约策略不再依赖于一次处理多少查询词元!
实现
通过利用 vLLM 的 FlexAttention 后端以及 torch.Library,提供了一个在 vLLM 之上进行确定性推理的演示。通过 torch.Library,能够以非侵入性的方式替换掉大部分相关的 PyTorch 操作符。可以在 thinking-machines-lab/batch-invariant-ops 找到“批次不变”核函数库,以及在“确定性”模式下运行的 vLLM 示例
地址:
实验
完成结果的非确定性有多严重?
使用 Qwen/Qwen3-235B-A22B-Instruct-2507 模型,在温度为 0 的情况下,以提示“Tell me about Richard Feynman”采样 1000 次补全,每次生成 1000 个词元。令人惊讶的是,产生了 80 个独特的补全结果,其中最常见的出现了 78 次
观察补全结果的差异之处,可以看到它们在前 102 个词元上实际上是相同的!分歧的首次出现是在第 103 个词元处。所有补全都生成了序列“Feynman was born on May 11, 1918, in”。然而,其中 992 个补全接着生成了“Queens, New York”,而 8 个补全生成了“New York City”
另一方面,当启用批次不变的核函数时,所有 1000 个补全结果都是相同的。这正是从采样器中数学上期望得到的结果,但没有批次不变的核函数是无法实现确定性结果的。
性能
这里没有在优化批次不变核函数的性能上投入大量精力。然而,还是进行了一些实验来验证其性能仍然可用
将设置一个 API 服务器,用一个 GPU 运行 Qwen-3-8B,并请求 1000 个序列,输出长度在 90 到 110 之间
大部分的性能下降来自于 vLLM 中 FlexAttention 集成尚未经过高度优化。尽管如此,可以看到性能并非灾难性的
真正的同策略强化学习
正如研究人员所指出的,训练和推理之间的不同数值计算,不知不觉地将同策略(on-policy)强化学习变成了异策略(off-policy)强化学习
当然,如果甚至无法在两次相同的推理请求之间获得逐位元相同的结果,那么在训练和推理之间获得逐位元相同的结果是不可能的。确定性推理使我们也能修改训练栈,以获得采样和训练之间逐位元相同的结果,从而实现真正的同策略强化学习
在一个 RLVR 设置中,在 Bigmath 上进行了实验,RL 策略由 Qwen 2.5-VL instruct 8B 初始化,最大 rollout 长度为 4096
如果在没有异策略校正(即重要性权重)的情况下进行训练,奖励会在训练中途崩溃,而添加异策略校正项则允许训练顺利进行。但是,如果在采样器和训练器之间实现了逐位元相同的结果,就完全处于同策略(即 0 KL 散度)状态,并且也能顺利训练。
还可以绘制采样器和训练器之间 logprobs 的 KL 散度图,其中 3 次运行的行为有显著不同。当使用重要性权重运行时,它保持在 0.001 左右,偶尔出现尖峰。然而,不使用重要性权重运行最终会导致 KL 散度出现尖峰,大约在奖励崩溃的同一时间。当然,当运行“真正的同策略 RL”时,KL 散度保持在 0,表明训练策略和采样策略之间没有分歧
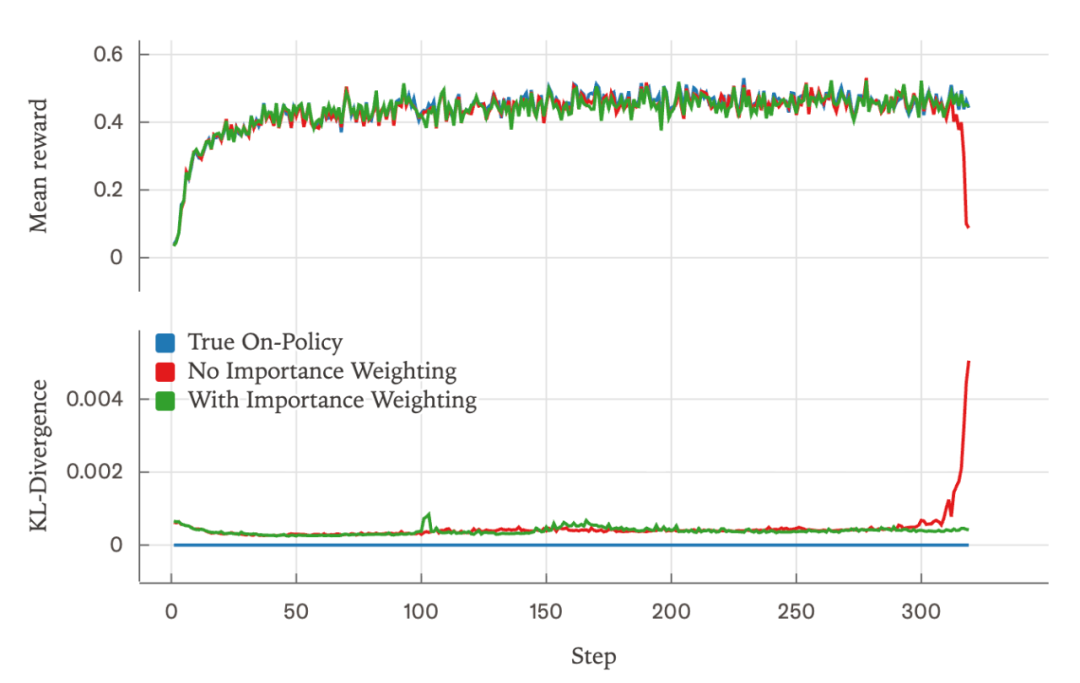
图16,注意,没有重要性权重的运行在第 318 步附近有一个显著的损失尖峰,并且这伴随着 logprobs 的 KL 散度出现相应的尖峰。与此同时,无论是使用异策略校正还是运行“真正的同策略”都允许 RL 继续顺利进行。显示“真正的同策略”的蓝线不是一个 bug——它就是一条平坦的 0 线。
结论
现代软件系统包含许多抽象层。在机器学习中,当遇到非确定性和微小的数值差异时,很容易将它们掩盖过去。毕竟,系统已经是概率性的了,多一点非确定性又有什么关系呢?在失败的单元测试中提高 atol/rtol 的容忍度又有什么问题呢?训练器和采样器之间 logprobs 的差异可能不是一个真正的 bug,对吧?
本文反对这种失败主义的态度。通过一些努力,可以理解非确定性的根本原因,甚至解决它们!希望这篇博客文章能够为社区提供一个坚实的理解,关于如何解决推理系统中的非确定性问题,并激励其他人去完全理解他们的系统
source:
https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/
☟☟☟
☞人工智能产业链联盟筹备组征集公告☜
☝
精选报告推荐:
11份清华大学的DeepSeek教程,全都给你打包好了,直接领取:
【清华第四版】DeepSeek+DeepResearch让科研像聊天一样简单?
【清华第七版】文科生零基础AI编程:快速提升想象力和实操能力
【清华第十一版】2025AI赋能教育:高考志愿填报工具使用指南
10份北京大学的DeepSeek教程
【北京大学第五版】Deepseek应用场景中需要关注的十个安全问题和防范措施
【北京大学第九版】AI+Agent与Agentic+AI的原理和应用洞察与未来展望
【北京大学第十版】DeepSeek在教育和学术领域的应用场景与案例(上中下合集)
8份浙江大学的DeepSeek专题系列教程
浙江大学DeepSeek专题系列一--吴飞:DeepSeek-回望AI三大主义与加强通识教育
浙江大学DeepSeek专题系列二--陈文智:Chatting or Acting-DeepSeek的突破边界与浙大先生的未来图景
浙江大学DeepSeek专题系列三--孙凌云:DeepSeek:智能时代的全面到来和人机协作的新常态
浙江大学DeepSeek专题系列四--王则可:DeepSeek模型优势:算力、成本角度解读
浙江大学DeepSeek专题系列五--陈静远:语言解码双生花:人类经验与AI算法的镜像之旅
浙江大学DeepSeek专题系列六--吴超:走向数字社会:从Deepseek到群体智慧
浙江大学DeepSeek专题系列七--朱朝阳:DeepSeek之火,可以燎原
浙江大学DeepSeek专题系列八--陈建海:DeepSeek的本地化部署与AI通识教育之未来
4份51CTO的《DeepSeek入门宝典》
51CTO:《DeepSeek入门宝典》:第1册-技术解析篇
51CTO:《DeepSeek入门宝典》:第2册-开发实战篇
51CTO:《DeepSeek入门宝典》:第3册-行业应用篇
51CTO:《DeepSeek入门宝典》:第4册-个人使用篇
5份厦门大学的DeepSeek教程
【厦门大学第一版】DeepSeek大模型概念、技术与应用实践
【厦门大学第五版】DeepSeek等大模型工具使用手册-实战篇
10份浙江大学的DeepSeek公开课第二季专题系列教程
【精选报告】浙江大学公开课第二季:《DeepSeek技术溯源及前沿探索》(附PDF下载)
【精选报告】浙江大学公开课第二季:2025从大模型、智能体到复杂AI应用系统的构建——以产业大脑为例(附PDF下载)
【精选报告】浙江大学公开课第二季:智能金融——AI驱动的金融变革(附PDF下载)
【精选报告】浙江大学公开课第二季:人工智能重塑科学与工程研究(附PDF下载)
【精选报告】浙江大学公开课第二季:生成式人工智能赋能智慧司法及相关思考(附PDF下载)
【精选报告】浙江大学公开课第二季:AI大模型如何破局传统医疗(附PDF下载)
【精选报告】浙江大学公开课第二季:2025年大模型:从单词接龙到行业落地报告(附PDF下载)
【精选报告】浙江大学公开课第二季:2025大小模型端云协同赋能人机交互报告(附PDF下载)
【精选报告】浙江大学公开课第二季:DeepSeek时代:让AI更懂中国文化的美与善(附PDF下载)
【精选报告】浙江大学公开课第二季:智能音乐生成:理解·反馈·融合(附PDF下载)
6份浙江大学的DeepSeek公开课第三季专题系列教程
【精选报告】浙江大学公开课第三季:走进海洋人工智能的未来(附PDF下载)
【精选报告】浙江大学公开课第三季:当艺术遇见AI:科艺融合的新探索(附PDF下载)
【精选报告】浙江大学公开课第三季:AI+BME,迈向智慧医疗健康——浙大的探索与实践(附PDF下载)
【精选报告】浙江大学公开课第三季:心理学与人工智能(附PDF下载)
【AI加油站】第八部:《模式识别(第四版)-模式识别与机器学习》(附下载)
人工智能产业链联盟高端社区

一次性说清楚DeepSeek,史上最全(建议收藏)
DeepSeek一分钟做一份PPT
用DeepSeek写爆款文章?自媒体人必看指南
【5分钟解锁DeepSeek王炸攻略】顶级AI玩法,解锁办公+创作新境界!
【中国风动漫】《雾山五行》大火,却很少人知道它的前身《岁城璃心》一个拿着十米大刀的男主夭折!

免责声明:部分文章和信息来源于互联网,不代表本订阅号赞同其观点和对其真实性负责。如转载内容涉及版权等问题,请立即与小编联系(微信号:913572853),我们将迅速采取适当的措施。本订阅号原创内容,转载需授权,并注明作者和出处。如需投稿请与小助理联系(微信号:AI480908961)
编辑:Zero













