一、研究背景
在机器人领域,让机器人在复杂、非结构化环境中像人类一样熟练完成多样化任务,是长期核心目标。近年来,视觉-语言-动作(VLA)模型通过端到端映射感官输入与自然语言指令到机器人动作,推动了这一目标的落地,但仍存在显著局限:
泛化能力弱:环境微小变化(如物体外观、光照差异)会大幅降低性能; 数据依赖强:需大规模标注数据集,部署成本高、扩展性差。
为解决这些问题,研究人员提出分层策略,利用视觉-语言模型(VLM)将任务分解为子任务,并调用预定义操纵原语(如导航、抓取)。但这类方法受限于原语库,无法处理开门、拉抽屉等需要精细交互的真实场景任务——这类任务难以被有限的预定义原语覆盖。
此前基于代码生成的尝试也存在不足:早期方法仅适用于简单几何任务;部分方法依赖学习模型处理物理约束,降低对新场景的适应性;还有方法无法处理接触密集型操纵,或仅聚焦于故障检测而非扩展操纵能力。针对移动机器人,还需解决环境信息留存、非视野内物体规划等更复杂的挑战。
二、核心创新点
本研究提出的EmbodiedCoder是一种无训练框架,核心创新围绕“用代码连接感知与操纵”展开,具体包括三点:
无训练的开放世界适配:无需额外数据收集或微调,通过编码模型直接生成可执行轨迹代码,摆脱对预定义原语和大规模数据集的依赖,降低部署成本。 功能化几何参数化方法:将任务相关物体的点云拟合为几何基元(如将门拟合为带旋转轴的矩形、苹果拟合为球体),不仅捕捉物体整体结构,还提取功能组件(如门把手、抽屉滑轨),为轨迹规划提供结构化依据。 代码驱动的轨迹合成与缓存:基于几何参数生成满足物理、环境、硬件约束的参数化轨迹(如圆弧、贝塞尔曲线);同时引入代码缓存机制,复用已生成的可靠代码,平衡“已知任务效率”与“新任务泛化”。
三、主要技术方案
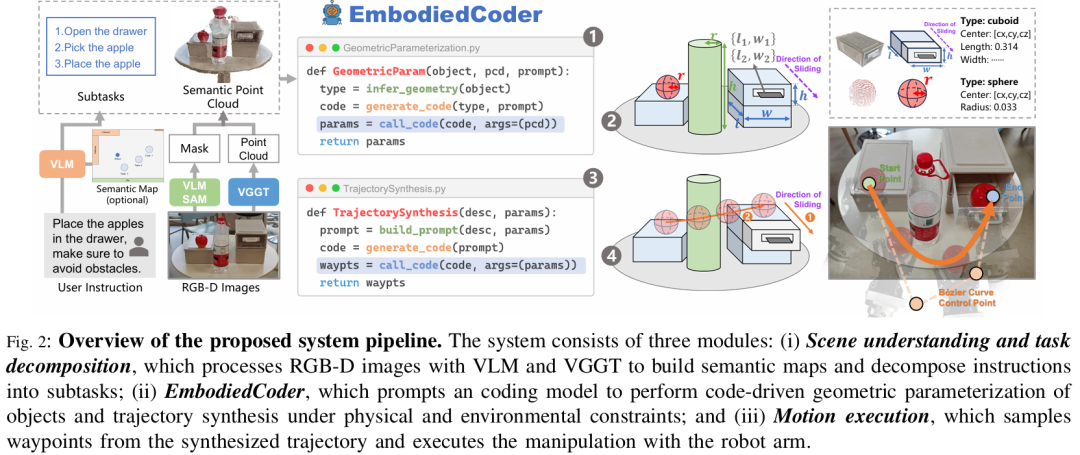
EmbodiedCoder的系统流程分为三大模块,整体框架如Fig.2所示,核心是通过代码将高-level指令转化为低-level操纵动作。
问题定义
将移动操纵任务形式化为带约束的运动规划问题,映射关系如下:
其中:
为场景的RGB-D观测数据; 为自然语言指令; 为约束集合(物体物理属性、环境障碍物、机器人运动学限制); 输出为与子任务对齐的动作序列。
场景理解与任务分解
该模块的目标是将原始感官数据转化为“任务相关的结构化信息”,分为两步:
语义映射构建:
用VGGT处理RGB图像,重建场景稠密点云;结合RGB-D相机的深度图校正,得到可靠的 metric-scale 点云; 用VLM生成物体边界框,输入SAM得到2D语义掩码,再投影到点云上,生成语义点云地图,并转化为BEV格式存储。
VLM结合语义地图,将总指令分解为子任务(如“开门→取水瓶→倒水”); 对每个子任务,VLM识别相关物体,推断其适配的几何形状(如抽屉为长方体、门把手为圆柱体),并通过SAM生成物体掩码,投影得到“仅包含目标物体”的语义点云,为后续参数化做准备。
EmbodiedCoder核心模块
该模块是框架的核心,通过编码模型生成代码,完成“几何参数化”与“轨迹合成”,具体分为三个阶段:
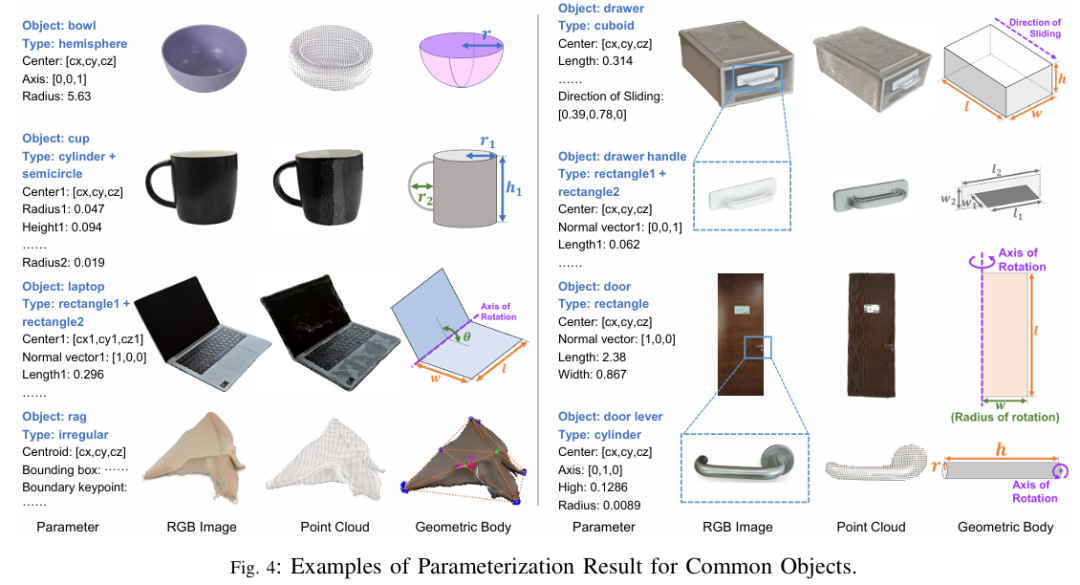
代码驱动的几何参数化
输入子任务相关的物体点云,编码模型生成代码将点云拟合为几何基元,同时提取功能参数。例如:
门的参数化:将门拟合为矩形(需估计中心、长宽、法向量),门把手拟合为圆柱体(需估计中心、半径、轴线方向),并推断铰链轴位置与旋转半径(如Fig.3的代码示例);

deformable物体(如抹布):通过极值点构建边界包围盒,而非刚性基元拟合。
参数化结果将非结构化点云转化为紧凑的结构化表示(如苹果→“球体(中心+半径)”,抽屉→“长方体(中心+长宽高+滑动方向)”),示例见Fig.4。
代码驱动的轨迹合成
基于几何参数,编码模型生成代码,合成满足多约束的轨迹,约束包括:
物理约束(如门绕铰链旋转、抽屉沿滑轨滑动); 环境约束(避障、门开启宽度需允许机器人通过); 硬件约束(机器人关节运动范围)。
轨迹以参数化曲线(如贝塞尔曲线、圆弧)表示,再采样离散路径点供机器人执行。例如“将苹果放入抽屉并避障”任务中,代码会生成带避障控制点的贝塞尔曲线,确保抓取苹果后绕开周围障碍物(如Fig.5的代码示例)。

代码缓存
对熟悉物体(如常见水瓶、抽屉)或重复子任务,复用已验证的代码,减少生成延迟与错误;对新物体/任务,重新调用编码模型生成代码。随任务执行,系统会积累可复用的技能库,逐步提升效率。
运动执行
机器人按子任务顺序执行:先导航至目标位置,再根据EmbodiedCoder生成的轨迹采样路径点,控制机械臂完成操纵(如抓取、旋转、放置),最终实现从“视觉-语言输入”到“动作输出”的闭环。
相关工作回顾
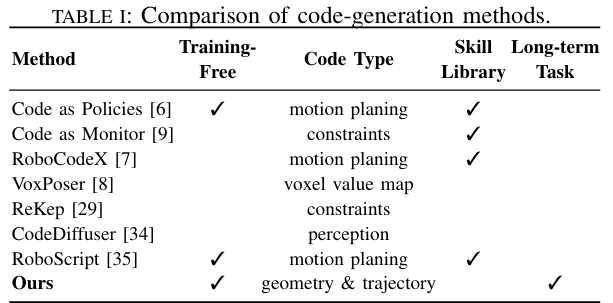
研究将EmbodiedCoder与三类主流方法进行对比,核心差异在于“是否依赖训练数据”“是否受限于预定义原语”“能否处理长期任务”:
数据驱动的VLA模型
特点:端到端映射视觉-语言输入到动作,如RT-1、RT-2、TinyVLA; 不足:需大规模机器人演示数据,泛化能力弱(环境变化易失效); 对比:EmbodiedCoder无需训练,通过几何参数化与代码生成适配新场景,在“倒水”等精细任务中表现更优(Table IV显示平均成功率89.2%,超过RT-2的84%)。

LLM驱动的轨迹与代码生成
特点:用LLM生成代码或轨迹,如Code-as-Policies、RoboCodeX、VoxPoser; 不足:Code-as-Policies仅适用于简单几何任务,RoboCodeX依赖 curated 多模态数据,VoxPoser无法处理接触密集型操纵; 对比:EmbodiedCoder通过“几何参数化→约束轨迹合成”两步法,能处理开门、抽屉操作等复杂任务,且无训练需求(Table I显示仅EmbodiedCoder同时满足“无训练”“处理长期任务”“无技能库依赖”)。
预定义技能的模块化系统
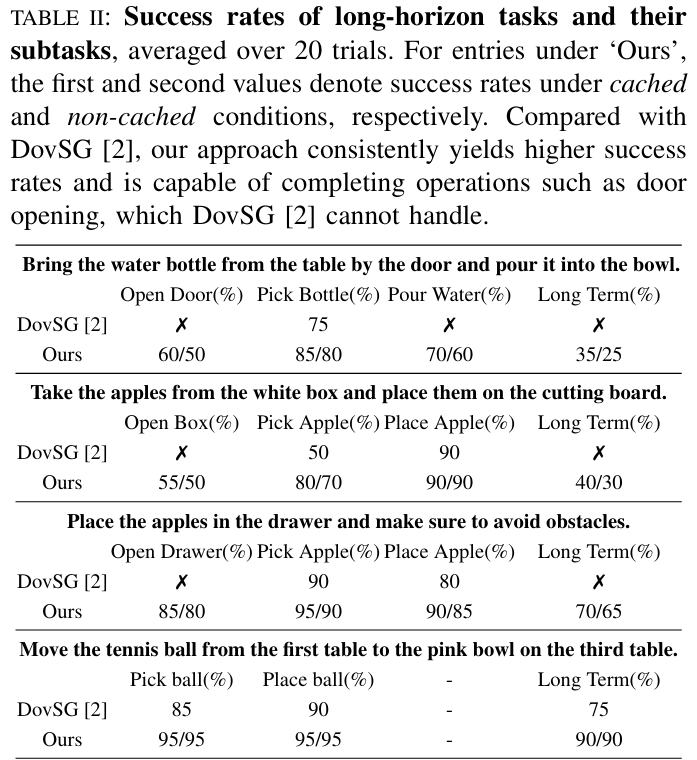
特点:结合high-level推理与固定技能库,如SayCan、OK-Robot、DovSG; 不足:受限于预定义原语,无法处理无对应原语的任务(如开门); 对比:EmbodiedCoder无需预定义技能,通过代码生成扩展操纵能力,Table II显示在“将苹果放入抽屉”任务中,长期成功率达65%(无缓存)和70%(有缓存),而DovSG无法完成该任务。
五、实验验证
实验基于AgileX Cobot S机器人(搭载RealSense D455相机),用Qwen-2.5VL(7B)做语义 grounding 与任务分解,ClaudeSonnet-4生成参数化与轨迹代码,验证“长期任务性能”“简单任务泛化”“模块有效性”。
长期任务评估
设计5项多步任务(如“从门边桌子取水瓶并倒入碗中”“将网球从第一张桌子移到第三张桌子的粉色碗中”),重复20次,对比DovSG:
结果:EmbodiedCoder在有缓存和无缓存条件下性能接近(如“开门”成功率75%,无缓存70%),说明零样本泛化能力; 优势:能处理DovSG无法完成的任务(如开门、抽屉操作),Table II显示“将苹果放入抽屉”任务的长期成功率达65%(无缓存)和70%(有缓存); 不足:开门成功率低于其他子任务,因机器人靠近门时相机视野有限,导致点云不完整,影响参数估计(如旋转半径计算错误)。
简单任务评估
在VLA模型的OOD基准任务上对比(如“抓取百事罐”“将苹果放在盘子上”“倒水”):
Table IV显示,EmbodiedCoder平均成功率89.2%,超过RT-2(84%)、OpenVLA(73.3%); 优势:在“倒水”等需精细控制的任务中表现突出(成功率80%),因几何参数化能捕捉容器表面法向量、倾斜角度约束,避免VLA模型依赖视觉特征的模糊性。
消融实验
物体形状对抓取的影响:对比AnyGrasp,EmbodiedCoder在各类物体上的抓取成功率更高(如塑料瓶100% vs 95%,易拉罐75% vs 40%,Table V),因参数化能结合 gripper 运动学约束(如球体沿径向对齐 gripper,圆柱体沿主轴选择接触点); 语义地图对任务分解的影响:Table VI显示,Qwen-7B在提供2D语义地图时,子任务分解成功率从72%提升至88%,因地图帮助模型对齐真实环境,减少规划幻觉(如“先导航到门口再开门”); 编码模型能力的影响:Fig.7显示,Claude-Sonnet-4的代码“完整率”(生成可执行代码)和“有效率”(代码完成任务)最高,但延迟较大;其他模型(如Qwen3-Coder、Kimi-k2)表现显著较差,说明仅最新编码模型具备足够的推理能力支撑任务。
参考
[1]EmbodiedCoder: Parameterized Embodied Mobile Manipulation via Modern Coding Model