原文链接:
点击下方卡片,关注“大模型之心Tech”公众号
本文只做学术分享,如有侵权,联系删文,自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
苹果这几天真是进入了论文高产期,时不时就有新的研究发布出来。
就在近日,苹果又发布了一篇引发学界与业界关注的重磅论文。
这篇论文非常有意思,它用强化学习训练模型,让模型能够准确标出答案中哪些部分是幻觉(hallucinated)。
其核心突破在于:模型不再只是笼统地提示有错误,而是能直接指出具体哪一段文字是错误的。这对于需要修改输出或进行事实审查的用户来说,大大节省了时间。
论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。
该方法在片段级幻觉检测任务上,甚至超过了 GPT-5 和 o3。
总体而言,片段级奖励 + 类别平衡机制让模型真正学会了核查依据并精确指出错误内容,这是让大语言模型更可靠、更可审计的重要一步。

来源:https://x.com/rohanpaul_ai/status/1974652007068967315
接下来我们看看论文内容。
论文摘要部分,作者表示大语言模型常常会生成幻觉内容,即与事实不符、缺乏支持的信息,这会削弱模型输出的可靠性。以往的大多数研究都将幻觉检测视为一个二分类任务(即判断是否存在幻觉),但在许多实际应用中,人们需要识别具体的幻觉片段(hallucinated spans),这实际上是一个多步骤决策过程。
这自然引出了一个关键问题:显式推理是否能帮助完成幻觉片段检测这一复杂任务?
为了解答这个问题,来自苹果等机构的研究者首先对有无思维链推理的预训练模型进行了评估,结果表明:具备 CoT 推理的模型在多次采样时,往往能至少生成一个正确答案。
受到这一发现的启发,研究者提出了一个新的框架 RL4HS(Reinforcement Learning for Hallucination Span detection)。
该框架通过强化学习机制,利用片段级(span-level)奖励函数来激励模型进行推理。RL4HS 基于组相对策略优化(GRPO)方法构建,并引入了类别感知策略优化,以缓解奖励不平衡问题。
在 RAGTruth 基准测试集(涵盖摘要生成、问答、数据到文本等任务)上的实验结果显示:
RL4HS 的表现优于预训练的推理模型与传统监督微调方法;
这表明,对于幻觉片段检测任务,基于片段级奖励的强化学习机制是必要且有效的。

论文地址:https://arxiv.org/pdf/2510.02173
论文标题:Learning to Reason for Hallucination Span Detection
RL4HS 框架
本研究的核心问题之一是:显式推理是否有助于识别幻觉片段。
作为初步实验,研究者选取了 Qwen2.5-7B 和 Qwen3-8B 两种模型,在是否启用思维链两种模式下进行评估。研究者让大模型(Qwen 系列)分别在先推理后判断和直接判断两种模式下工作。
针对每个输入,本文对模型进行 K 次采样,并根据 Span-F1 指标选择最佳预测结果。相应的 Span-F1@K 结果如图 1 所示。

结果显示,当 K=1 时,思维链推理对 Qwen2.5-7B 模型没有带来性能提升,对 Qwen3-8B 模型的提升也较为有限。然而随着 K 值增大,Span-F1@K 指标的差距显著扩大,这证明思维链推理在多次采样时至少能产生一次准确预测的潜力。这些结果为采用强化学习方法来激发大语言模型在幻觉片段检测方面的推理能力提供了明确依据。本文在 Qwen2.5-14B 和 Qwen3-14B 模型上也进行了相同实验,观察到了类似现象。
此外,本文还采用了 GRPO,其学习目标定义如下:

尽管 GRPO 在组内对优势值进行了标准化处理,但本文发现预测类型会显著影响优势值的大小,如图 3 所示。
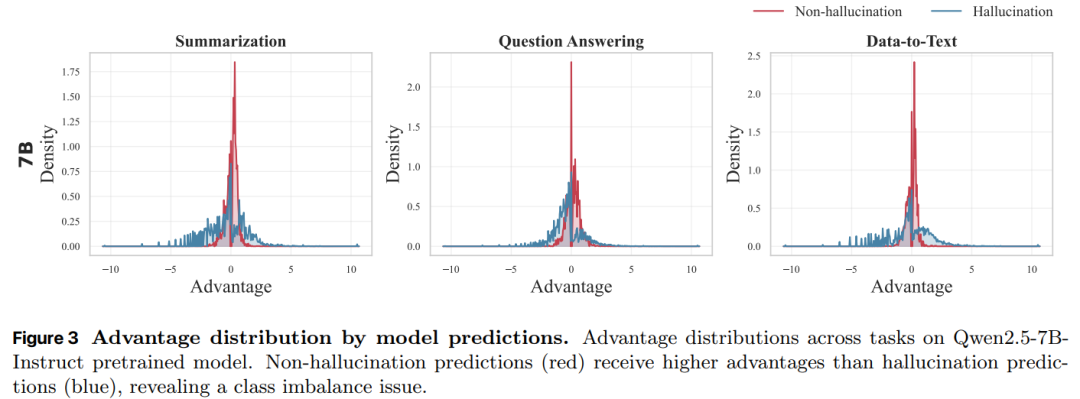
这种偏差源于奖励函数 r_span 固有的不对称性。在非幻觉类别中,模型只需预测一个空片段列表即可获得高奖励;而在幻觉类别中,模型必须精确定位并输出正确的片段范围。后者是更困难的目标,细微误差就会导致基于 F1 的奖励大幅降低。因此,GRPO 会过度激励模型做出非幻觉预测,最终形成高精确率但召回率被抑制的偏差行为。
为了解决这种不平衡问题,本文提出了类别感知策略优化(Class-Aware Policy Optimization,简称 CAPO)。该方法为非幻觉类别的样本引入一个缩放因子 α,用于调整其对应的优势值,从而缓解奖励偏差。本实验中使用 α = 0.5。

实验
实验数据集如下所示:

实验主要采用 Qwen2.5-7B-Instruct 和 Qwen2.5-14B-Instruct 作为基础模型。
作为对比,本文还评估了以下几类模型:
预训练推理模型:Qwen3-8B、Qwen3-14B 和 QwQ-32B;
商用推理模型:GPT-5、o3、GPT-4o-mini 以及 GPT-5-mini。
表 1 报告了 RAGTruth 在摘要、问答和数据转文本等任务中的幻觉检测结果。
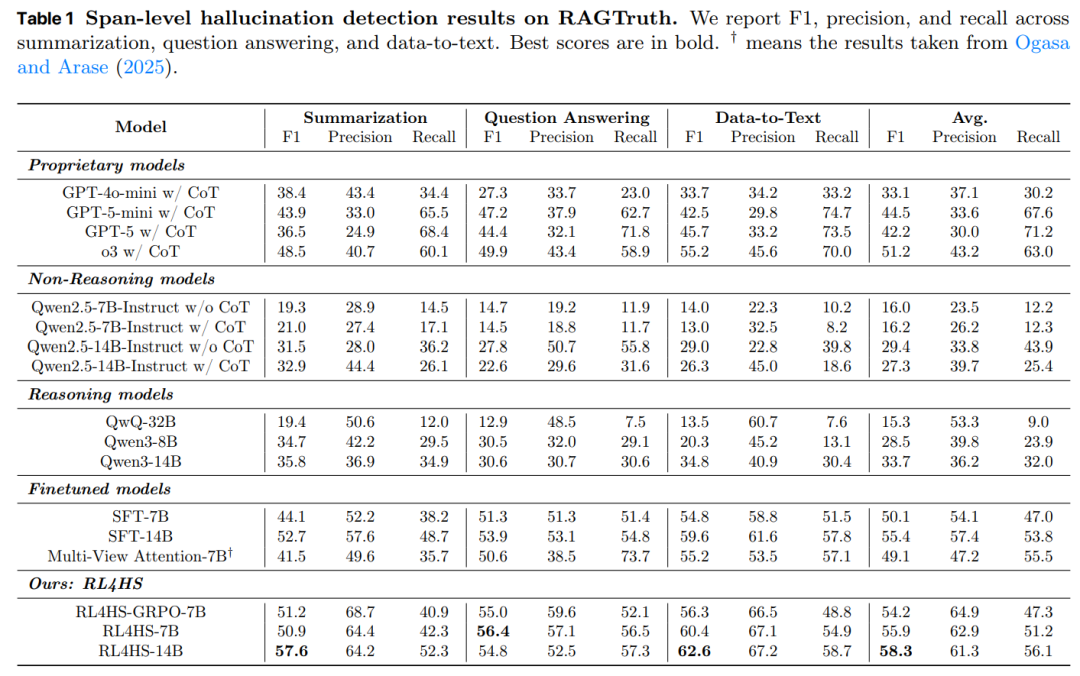
预训练指令微调模型: Qwen2.5-7B/14B-Instruct(无论是否使用 CoT)在任务中的表现都较差,F1 分数低于 30,这表明仅依靠提示并不足以实现精确的片段级定位。
预训练推理模型:具备推理能力的模型(如 QwQ-32B、Qwen3-8B、Qwen3-14B)在幻觉检测任务中能够迁移部分推理能力。例如,Qwen3-14B 在摘要任务上的 F1 提升至 35.8,而 Qwen2.5-14B-Instruct 仅为 32.9。然而,这些模型的表现仍落后于微调模型,这说明仅具备一般推理能力还不足以胜任片段级幻觉检测任务。
微调基线模型:监督微调显著提升了性能,在 14B 规模下 F1 达到 55.4。
RL4HS 模型:RL4HS 在所有基线模型之上表现出一致的优势,包括专有模型 GPT-4o/5-mini、GPT-5 和 o3。RL4HS-7B 在三个任务上的平均 F1 达到 55.9,显著优于 SFT 的 50.1。在 14B 规模下,RL4HS-14B 在摘要、问答和数据到文本任务上分别取得 57.6、54.8 和 62.6 的成绩,超越了 Qwen3 系列以及表现最强的 GPT-5 和 o3 模型。
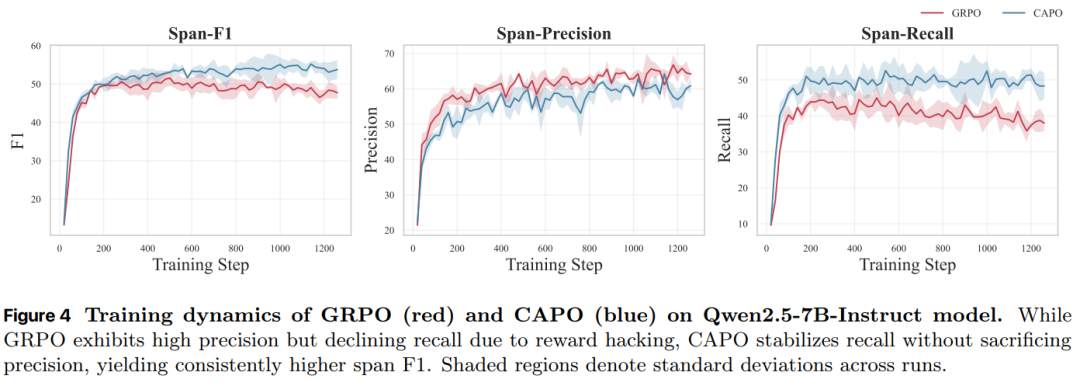
下图表明 CAPO 有效地解决了优势分布分析中揭示的不平衡问题。

为了更好地理解 RL4HS 所学习到的推理行为,本文在 RAGTruth 数据集上进行了定性结果分析(见表 3)。这一示例聚焦于一个具体的不一致问题。
预训练模型。在微调之前,预训练模型未能识别这一不一致。虽然它检查了结构化的营业时间和用户评价,但忽略了一个关键事实:结构化数据中并没有任何与餐饮服务相关的属性。因此,模型未标注出任何幻觉片段。
RL4HS。相比之下,RL4HS 成功识别出了提供餐饮服务这一声明是幻觉内容。其推理过程与人工设计的启发式检测流程高度一致
这一案例表明,RL4HS 的推理不仅停留在表面解释层面。不同于生成笼统或无关的说明,它能够执行系统化的、一致性检验式的推理,与传统幻觉检测流程中使用的启发式规则高度契合。这说明在片段级奖励机制下,RL4HS 所学到的推理行为是真实的、可靠的。

了解更多内容,请参考原论文。
大模型之心Tech知识星球交流社区
我们创建了一个全新的学习社区 —— “大模型之心Tech”知识星球,希望能够帮你把复杂的东西拆开,揉碎,整合,帮你快速打通从0到1的技术路径。
星球内容包含:每日大模型相关论文/技术报告更新、分类汇总(开源repo、大模型预训练、后训练、知识蒸馏、量化、推理模型、MoE、强化学习、RAG、提示工程等多个版块)、科研/办公助手、AI创作工具/产品测评、升学&求职&岗位推荐,等等。
星球成员平均每天花费不到0.3元,加入后3天内不满意可随时退款,欢迎扫码加入一起学习一起卷!











