
> 作者:Rikki
如果你关注机器人领域,可能会发现一个有趣的趋势:越来越多的四足机器人开始“听懂人话”“看懂世界”,能根据语言指令完成导航、避障甚至抓取等任务。这背后,多模态大语言模型(MLLM)功不可没——它能整合视觉、语言信息,帮机器人做决策。但问题来了:MLLM计算量大,推理速度慢,机器人往往“想半天才能动一下”,在动态环境里很容易“撞墙”。
最近看到一篇题为《QUART-Online: Latency-Free Multimodal Large Language Model for Quadruped Robot Learning》的论文,正好解决了这个“延迟痛点”。今天就用通俗的语言,聊聊这篇论文的核心思路、实验结果,以及它为啥能让四足机器人“反应更快、干活更准”。

论文链接:https://huggingface.co/papers/2412.15576
项目链接:https://quart-online.github.io
一、先聊聊背景:四足机器人的“聪明但迟钝”难题
1. MLLM给机器人带来的“超能力”
以前的四足机器人,大多是“专项选手”——比如只会走固定路线,换个指令或场景就“懵了”。但MLLM出现后,情况变了:它能理解自然语言(比如“绕开红色障碍物”),能识别从没见过的物体,甚至能“推理”(比如“先挪开箱子才能到目标点”)。
论文里提到一个叫QUART的前辈模型,就已经实现了“端到端控制”——输入图像和语言指令,直接输出机器人动作,还展现出不少“ emergent abilities ”(突发能力),比如看懂新指令、适应新物体。
2. 致命瓶颈:推理延迟让机器人“慢半拍”
但QUART有个大问题:推理速度太慢。论文里做了测试,QUART的推理频率只有2Hz——意思是1秒只能输出2个动作指令。而四足机器人的底层控制器,通常需要50Hz的频率才能流畅运动(1秒50次调整)。
这就像你开车时,大脑1秒才反应1次,遇到突发情况根本来不及刹车。论文里举了个例子:面对移动的红色障碍物,QUART因为延迟没及时拐弯,直接撞了上去

3. 传统解决方案:“砍参数”治标不治本
有人说:“把MLLM的参数减少点,不就快了?”论文里专门做了实验验证这个思路
表 1:QUART与不同参数缩减方案的性能对比表。每列信息为“方法”“成功率”“模型参数”“推理速度”。其中“P” 表示在 QUART 上实施参数缩减方法。
原版QUART(80亿参数):成功率74%,速度2Hz; 缩减到53亿参数:成功率暴跌到22%,速度只到3Hz; 缩减到27亿参数:成功率只剩11%,速度也才5Hz。
很明显:“砍参数”虽然能稍微提速,但会让MLLM的“智商”大幅下降——尤其面对没见过的场景(比如新物体、新指令),几乎没法工作。
二、QUART-Online的核心思路:不“砍智商”,只“优化动作”
既然“砍参数”不行,论文团队换了个角度:MLLM的推理延迟,主要是因为要处理大量连续动作数据。那能不能把动作“压缩”一下,让MLLM少算点?
基于这个想法,他们提出了QUART-Online模型,核心靠两个技术:动作块离散化(ACD) 和动作-感知对齐。咱们一个个说。
1. 动作块离散化(ACD):把“连续动作”变成“压缩数据包”
机器人的动作是“连续的”——比如关节角度每秒变50次,每次都是一个连续数值。MLLM要处理这些数据,就像要读一本没分页的书,又慢又容易乱。
ACD的作用,就是把“连续动作”整理成“压缩数据包”:
第一步:“打包”——把连续的N个动作帧(比如5帧、10帧)当成一个“动作块”,相当于给书分页; 第二步:“压缩”——用1D卷积把动作块压缩成少数“离散向量”(类似把几页内容总结成一个关键词),同时保留关键信息; 第三步:“解码”——MLLM输出压缩后的向量后,再用一个解码器把向量还原成连续动作,给底层控制器用。
论文里做了测试,验证不同动作块长度对ACD重建精度的影响
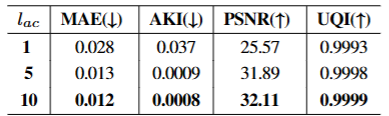
动作块长度1:MAE 0.028,PSNR 25.57; 动作块长度5:MAE 0.013,PSNR 31.89; 动作块长度10:MAE 0.012,PSNR 32.11。
很明显:动作块越长,压缩后还原的精度越高——因为包含了更多时间信息,就像总结10页内容比总结1页更准确。
2. 动作-感知对齐:让MLLM“看懂动作、语言、图像”
光压缩动作还不够,MLLM得能把“压缩动作”和“视觉、语言”对应起来——比如知道“‘绕开障碍物’这个指令,对应‘向左转+减速’这个压缩动作块”。
论文的做法是微调MLLM:把视觉数据(图像)、语言数据(指令)、压缩动作块一起喂给MLLM,让它学习三者的对应关系,形成一个“统一语义空间”。就像教孩子把“苹果”这个词、苹果的图片、“拿苹果”这个动作联系起来

而且微调时,只调整MLLM处理动作的部分,不改变它原本的“语言理解”和“图像识别”能力——保证MLLM的“智商”不下降。
3. 关键设计:让MLLM和控制器“同频共振”
论文里有个很巧妙的设计:通过调整动作块长度,让MLLM的推理频率和底层控制器的频率匹配。公式很简单:控制器频率(f_l)= 动作块长度(l_ac)× MLLM推理频率(f_m)

比如控制器需要50Hz,MLLM推理频率是10Hz,那选5个动作帧作为一个块就行(5×10=50)。这样MLLM每输出一个压缩动作块,解码器就能拆成5个连续动作,正好满足控制器的需求——实现“无延迟同步”。
三、实验结果:速度提25倍,成功率涨65%
说再多理论,不如看实验数据。论文在QUARD数据集(专门用于四足机器人测试,包含导航、避障、全身操作等任务)上做了全面测试,结果很亮眼。
1. 速度:从2Hz到50Hz,实现实时控制
原版QUART的推理速度只有2Hz,而QUART-Online直接冲到了50Hz——和底层控制器完全同步。这意味着机器人每秒能收到50个动作指令,再也不会“慢半拍”
2. 成功率:各类任务平均涨65%
论文对比了QUART-Online和原版QUART、VLA(CLIP)、VLA(VC-1)等基线模型

在“绕开障碍物”任务中,QUART-Online成功率90%,而QUART只有48%; 面对没见过的物体(比如新纹理的箱子),QUART-Online成功率89%,QUART只有25%; 面对同义不同表述的指令(比如“到目标点”换成“去那个物体那”),QUART-Online成功率99%,QUART只有33%。
整体算下来,QUART-Online的平均任务成功率比原版QUART提升了65%——既快又准。
3. 动态环境测试:成功避障,不再“撞墙”
论文还做了动态环境实验:让红色障碍物移动,看机器人能否避开。结果显示:
QUART因为延迟,一直保持原方向,直接撞向障碍物; QUART-Online能快速调整方向,顺利绕开

四、不足与未来:还有哪些可以改进?
当然,QUART-Online也不是完美的。论文里提到了两个未来要解决的问题:
动作层级不够深:目前输出的还是“高层指令”(比如“向左转”“减速”),需要底层控制器转换成关节角度。未来希望让MLLM直接输出关节角度,减少中间步骤; 复杂场景适应性待验证:实验主要在模拟环境(NVIDIA Isaac Gym)和简单真实场景中做的,还没测试复杂地形(比如山地、碎石路)。后续需要验证在更恶劣环境下的表现。
五、总结:QUART-Online的价值在哪?
这篇论文最核心的贡献,是找到了“不牺牲MLLM性能,又能降低推理延迟”的新思路——不是粗暴“砍参数”,而是通过“压缩动作+对齐多模态信息”,让MLLM和机器人控制器“高效配合”。
对于四足机器人领域来说,这意味着:未来的机器人既能保持“听懂人话、看懂世界”的能力,又能“反应迅速、动作流畅”,在家庭服务、工业巡检、救援等场景中更实用。
如果你想了解更多细节,可以去论文的项目页面看看(https://quart-online.github.io),里面有代码和更多实验视频。期待未来能看到QUART-Online在真实场景中大展身手!










