中科院自动化所团队 投稿
量子位 | 公众号 QbitAI
大模型参数量飙升至千亿、万亿级,却陷入“规模越大,效率越低” 困境?
中科院自动化所新研究给出破局方案——
首次让MoE专家告别“静态孤立”,开启动态“组队学习”。

具体而言,MoE本是大语言模型(LLM)实现参数量扩张且计算成本仅呈线性增长的核心路径,却长期受困于负载失衡、参数冗余、通信开销的“三难困境”,成为大模型落地部署的主要瓶颈。
而中科院自动化所的研究团队通过专家集群动态重组,不仅让大模型总参数量直降80%,负载方差降低至原来的三分之一,消耗内存更直逼轻量级传统稠密模型,更一举达成通信延迟、负载均衡、内存占用的三重优化,为大参数LLM的低成本部署提供了新路径。
下面详细来看——
一套统一框架直击MoE底层运作模式
随着LLM参数规模的持续扩张,模型规模增长与计算效率优化难以协同推进的核心挑战逐渐显现,混合专家模型(MoE)作为一种稀疏激活架构,为模型规模的持续扩展提供了理论上极具吸引力的技术途径。
它通过将计算任务动态分配给不同的“专家”子神经网络,使得模型参数量迅速增长的同时,计算成本仍能保持近乎线性增长。
然而,MoE在实际部署中面临着源于现代硬件体系结构限制的严峻挑战——一个根本性的“优化三难困境”制约了MoE模型的实际效能。
负载不均衡、参数冗余和通信开销这三大瓶颈,不仅各自形成了突出的优化难题,更关键的是,它们深度耦合、相互制约,成为当前MoE系统设计的核心障碍。
这些困境直接源于硬件的物理限制:
内存与容量限制:MoE巨大的参数量对GPU有限的高带宽显存构成了巨大压力,使得参数冗余成为一个关乎成本与可行性的关键问题。
计算资源利用率低:传统Top-K会直接将大量tokens路由给少数几个得分top的专家,这种路由方式极易引起高分专家计算过载,而其他专家则在GPU中长期处于空闲状态,造成了昂贵计算单元的严重浪费,使得实际吞吐量远低于理论值。
通信瓶颈:在多节点、多GPU的分布式训练中,实现Token到专家的动态路由所需的“All-to-All”全局通信模式,其高昂的延迟常常成为整个系统的性能主导因素。
面对此“三难困境”,现有的优化工作往往是碎片化的,未能从系统层面统一解决问题。
例如,负载均衡损失函数是一种被动的补偿机制;参数压缩技术(如MoE-Lite)虽减少了参数,却将专家视为独立的实体,忽视了其内在的结构关联性;而通信感知路由虽优化了数据传输路径,却无法改变模型固有的冗余和失衡问题。
这种“事后补救”的优化思路,凸显出一个严峻的现实——学界迫切需要一个能够协同解决这三重内在矛盾的统一框架。
近日,来自中国科学院自动化研究所的研究团队,提出了一套统一框架,该框架直击MoE的底层运作模式。
研究团队发现,被语义相似的输入所激活的专家,其参数本身也存在着结构性冗余。
这一发现为设计动态的、结构化的专家组织方式提供了理论依据,将专家从“静态孤立的个体”转变为“动态协作的联盟”。
实验表明,该框架在几乎不损失模型性能的前提下,实现了总参数量削减80%,吞吐量提升10%-20%,峰值内存消耗降低至逼近轻量级稠密模型的水平。
这项研究为构建更高效、更经济、更具可扩展性的MoE大模型提供了坚实的理论与实践基础。
方法详解:动态专家分组与结构化压缩的统一框架
为了系统性解决上文提到的三难困境,研究团队提出的框架将MoE的优化过程形式化为一个统一的联合优化数学问题,目标函数旨在同时最小化任务损失、负载不均衡、参数冗余和通信成本:
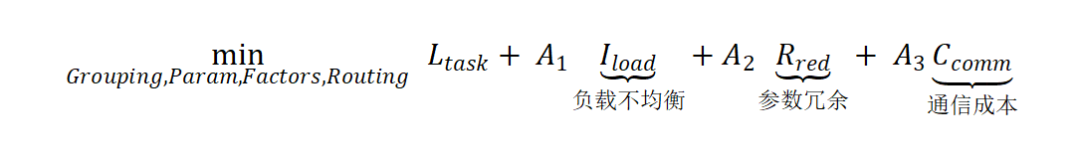
为求解该问题,研究团队设计了四个紧密耦合、协同作用的核心技术组件。
1.在线双相似度聚类
为克服传统Top-K路由在动态输入分布下易于导致的负载失衡问题,研究团队提出了一个主动对专家集合进行动态重组,而非被动调整路由概率的解决方案。
研究团队设计了一种在线聚类算法,周期性地将专家动态划分至若干专家簇。聚类的核心依据是一个融合相似度指标S,该指标同时量化了专家的“结构相似性”与“功能相似性”:
结构相似性(Sparam ):通过计算两个专家权重矩阵W𝑖和W𝑗向量化表示的余弦相似度,直接衡量它们在参数空间中的接近程度,揭示其底层的结构关联。

功能相似性(Stask ):研究团队利用路由器的输出logit作为输入Token的有效语义嵌入。为每个专家维护一个“激活质心”𝛍𝑖(路由至该专家的Token嵌入的指数移动平均值)。若两个专家的激活质心在向量空间中相近,则表明它们的功能定位趋同。
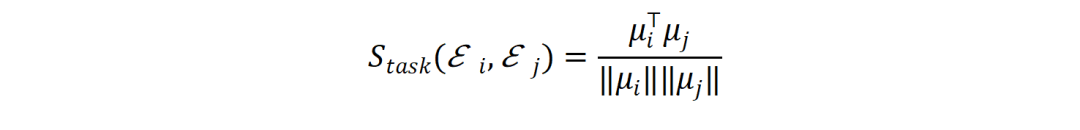
通过加权融合S(𝛆𝑖,𝛆𝑗 )=𝛼Sparam +(1—𝛼)Stask,研究团队获得一个全面的相似度度量,基于该指标周期性地运行K-means++聚类算法即可进行专家动态重组。
该方法保证了簇内专家的高度相关性,为后续的结构化参数压缩提供了前提。通过将路由过程分解,天然地平滑了Token分配的波动,起到粗粒度负载均衡的作用。
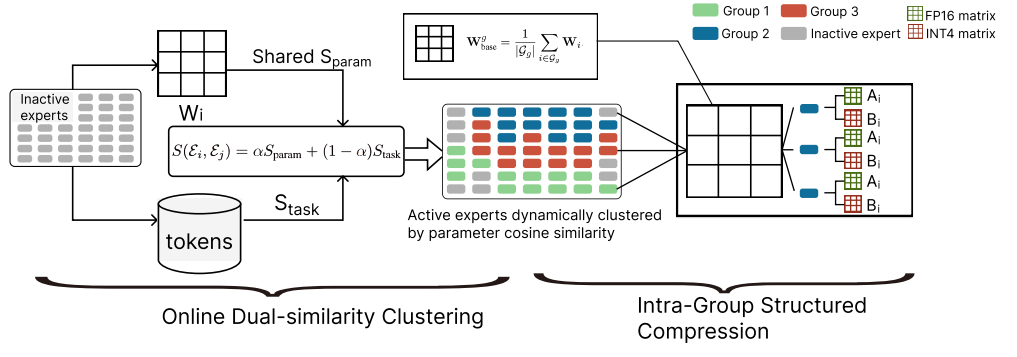
△图1:在线双相似度聚类与簇内结构化压缩框架示意图
2.共享基底与低秩残差压缩
既然簇内专家具有高度的功能与结构相似性,完整存储每个专家的参数矩阵便构成了显著的冗余。
研究团队提出一种结构化的参数分解方法,将每个专家的权重矩阵W𝑖分解为一个共享的公共部分和一个低秩的特有部分。
共享基底  :对于簇g内的所有专家,研究团队将其权重矩阵进行平均,得到一个代表该簇公共能力的共享基底矩阵。该矩阵仅需存储一份,由簇内所有专家共享。
:对于簇g内的所有专家,研究团队将其权重矩阵进行平均,得到一个代表该簇公共能力的共享基底矩阵。该矩阵仅需存储一份,由簇内所有专家共享。
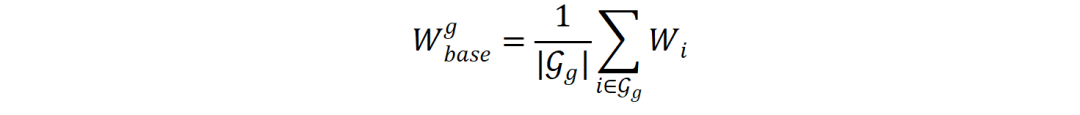
低秩残差(ΔW𝑖) :每个专家的特异性信息由其原始权重与共享基底的差值,即残差矩阵  来表征。研究团队认为,该残差矩阵具有低秩特性,因此可将其高效地分解为两个小维度矩阵A𝑖和B𝑖的乘积。
来表征。研究团队认为,该残差矩阵具有低秩特性,因此可将其高效地分解为两个小维度矩阵A𝑖和B𝑖的乘积。

在前向计算中, ,其中
,其中 的计算结果可在簇内专家间复用,提升了计算效率。
的计算结果可在簇内专家间复用,提升了计算效率。
此分解方法实现了显著的参数压缩。其研究团队用一个压缩比(CR)公式进行衡量:
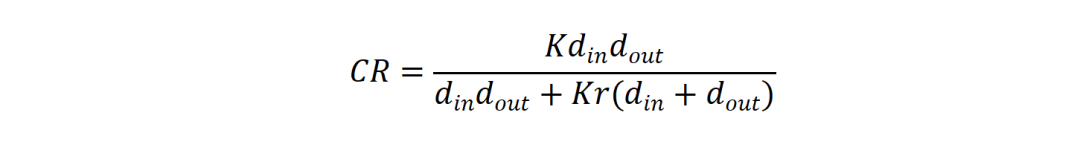
在典型配置下(d=4096,K=8,r=16),专家簇内压缩比高达6.6倍,框架能在几乎不损失模型表达能力的前提下,大幅削减参数冗余。
3.分层路由
传统的扁平化MoE路由机制需在全部专家中进行选择,其All-to-All通信模式是系统性能的主要瓶颈。研究团队设计了一种两阶段分层路由策略,将路由决策过程分解。
第一阶段:簇级别路由。输入Token x首先与G个簇的“原型向量”𝒰𝑔 计算相似度,通过Softmax选择最匹配的目标簇𝑔*。此步骤将路由的搜索空间从E个专家缩小至G个簇。
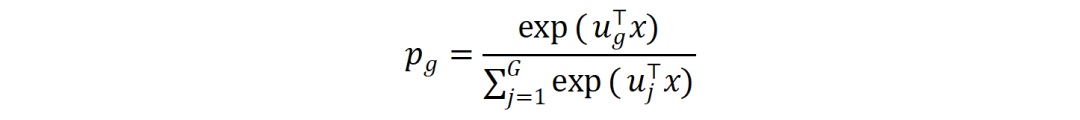
第二阶段:专家级别路由。在选定的簇𝑔*内部,Token x再与该簇内的K个专家的路由权重𝑣𝑖计算相似度,通过另一次Softmax选择最终激活的Top-K个专家。
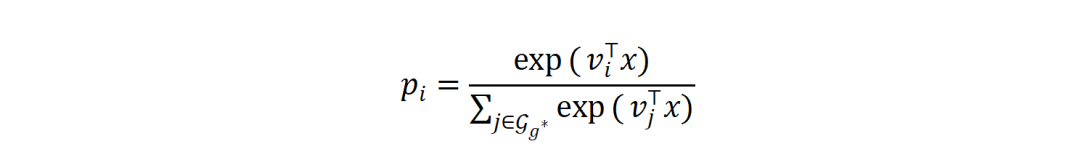
下图为分层路由机制示意图。该机制将路由过程分解为簇选择与簇内专家选择两个阶段。
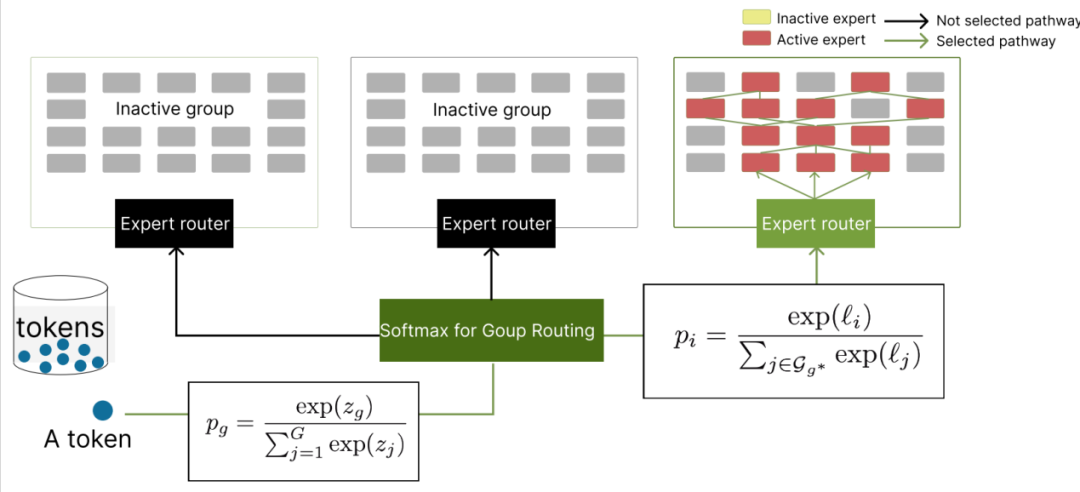
通过这种先选组再选专家的路由方法,路由计算复杂度从O(E·d)降低到O(G·d+K·d),在分布式环境中,数据仅需发送至托管目标簇𝑔* 的GPU子集,从而显著降低了All-to-All通信的数据交换,直接缓解了系统的通信延迟瓶颈。
4. 异构精度与动态内存管理
为进一步降低MoE模型的显存占用,使其能在更广泛的硬件上部署。
研究团队对不同参数组件采用非均匀的数值精度。敏感度较高的共享基底矩阵(图5)存储为FP16格式,而容错性更高的低秩残差因子A𝑖,B𝑖则被量化为INT4格式。
同时,研究团队设计了一套内存管理策略,实时监控专家簇的活跃度。若一个簇在连续多个步骤中未被激活,则将其参数从GPU显存动态卸载至NVMe存储。伴随着动态卸载,一个滚动激活预测器会异步地将预测将被调用的簇预取回显存。
该内存优化策略将MoE模型的峰值内存消耗降低至与小一个数量级的稠密模型相当的水平,显著提升了大规模MoE模型的易用性。
实验验证:性能、效率与均衡性的综合收益
研究团队在GLUE和WikiText-103等标准NLP基准上进行了全面的实验评估。
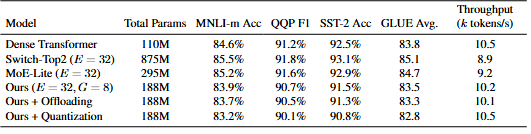

相较于基线模型Switch Transformer,研究团队的框架在维持相近模型质量的同时,总参数量减少约80%,吞吐量提升10%-20%,峰值内存消耗降低近50%。
而在启用动态卸载与量化后,模型的内存占用可与标准的稠密Transformer模型相媲美,为在资源受限环境下部署和研究MoE模型提供了可行性。
研究团队的方法将专家负载的变异系数降低了超过三分之一,证明了动态聚类在缓解负载失衡问题上的有效性。

而消融实验进一步证实,框架中的在线聚类、低秩压缩和分层路由等组件对最终的性能增益均有不可或缺的贡献。
论文链接:https://arxiv.org/abs/2510.02345










