👇扫码免费加入AI知识星球,如您有工作需要分享,欢迎联系:aigc_to_future

作者:Cong Wei等

文章链接:https://arxiv.org/pdf/2510.08377
项目链接:https://congwei1230.github.io/UniVideo/
Hugging Face链接:https://huggingface.co/papers/2510.08377
亮点直击
UniVideo——一种强大的多模态生成模型,在单一框架内统一实现视频的理解、生成与编辑功能。为实现这一目标,本文设计了双流架构,将多模态大模型(MLLM)的推理能力与多模态扩散Transformer(MMDiT)的生成优势相结合。相较于以往面向单一任务或受限模态的方法,UniVideo能够解析多模态指令、区分多样化任务,并在广泛基准测试中实现SOTA性能。 验证了UniVideo具备泛化到未知任务及新颖任务组合的能力,无需特别设计即可实现。这凸显了统一框架的显著优势。

总结速览
解决的问题: 统一多模态模型在多模态内容生成与编辑领域展现出巨大潜力,但其应用目前主要局限于图像领域。
提出的方案: 本文提出了UniVideo,一个将统一建模能力扩展至视频领域的多功能框架。UniVideo采用双流设计,结合用于指令理解的多模态大语言模型(MLLM)与用于视频生成的多模态DiT(MMDiT)。
应用的技术:
双流设计:结合MLLM和MMDiT,实现复杂多模态指令的准确解析。 单一多模态指令范式:统一视频生成和编辑任务,并进行联合训练。 泛化能力:支持任务组合和从图像编辑数据中迁移编辑能力。
达到的效果: UniVideo在文本/图像到视频生成、上下文视频生成和上下文视频编辑任务中达到或超越了当前SOTA的专用基线。它支持基于视觉提示的视频生成,并能处理未见过的指令,如绿幕角色或更换视频中的材质等。
方法
模型架构
如下图2所示,UniVideo由两个主要组件组成:多模态大语言模型(MLLM)和多模态DiT(MM-DiT)。MLLM负责视觉-文本理解,接受文本、图像和视频输入,并生成文本响应。MM-DiT专注于视觉生成,有两个分支:一个结合来自MLLM的高层语义信息,另一个整合来自VAE的细粒度重建信号。具体来说,本文提取MLLM的最后一层隐藏状态,这些状态编码了多模态输入的丰富语义特征。通过可训练连接器将其对齐到MM-DiT的输入空间,并输入其理解流。同时,视觉信号通过VAE编码并传递到MM-DiT生成流以保留细节。这种设计实现了强大的语义基础和高保真视觉细节,对于视频编辑和保留身份特征的上下文生成尤为重要。

统一多个任务
本文通过为每个视觉输入分配一个ID标签来标准化多模态指令,如上图1所示。对于文本到视频(T2V),文本输入由MLLM处理,而噪声视频则输入到MM-DiT。对于图像到视频(I2V),图像和文本都由MLLM处理,而图像和噪声视频则提供给MM-DiT。对于上下文视频生成(MultiID2V)和上下文视频编辑(ID-V2V),通常有多个视觉条件可用,例如几张参考图像和一个参考视频。每个视觉信号通过VAE编码,填充为统一形状,沿时间轴连接,然后通过自注意力处理。与之前引入任务特定偏置嵌入或上下文适配器模块的方法不同,本文避免任务特定的定制。为了帮助MM-DiT区分条件潜在变量和噪声视频潜在变量,本文应用3D位置嵌入,该嵌入在跨帧时保留空间索引,仅增加时间维度。实际上,发现这种策略比Qwen2-VL的MRoPE更有效,后者在引入新视觉输入时会偏移所有轴。
理解视觉提示
UniVideo利用其MLLM分支来解释非传统或手工制作的提示,如下图3和下图6所示。例如,用户可以提供带有手动注释的输入图像,MLLM将其翻译为结构化计划和密集的提示标记,用于指导视频生成。与调用多个下游生成器的基于代理的方法不同,UniVideo提供了更简化的设计:MM-DiT直接整合来自MLLM生成的密集提示标记的嵌入。这种整合有效地将视觉提示转化为上下文视频生成。
训练策略
阶段1: MLLM和MM-DiT之间的连接器对齐。在此阶段,本文仅训练MLP连接器,同时保持MLLM和MM-DiT冻结。训练在约百万的文本到图像(T2I)和约百万的文本到视频(T2V)生成任务的预训练样本上进行,以及一个图像重建任务,其中仅将文本到图像数据集中的图像输入到MLLM中,MM-DiT使用来自MLLM的视觉特征重建图像。在此阶段之后,UniVideo可以根据来自MLLM的文本或图像输入生成图像和视频。
阶段2: 在T2I和T2V上微调MM-DiT。在此阶段,本文保持MLLM冻结,并在约千的高质量T2I和T2V样本上微调连接器和MM-DiT。在此阶段之后,UniVideo实现了与使用其自身文本编码器的MM-DiT主干相当的性能。
阶段3: 多任务训练。最后,本文扩展训练以包括上下文生成(多ID到视频)、上下文视频编辑、图像编辑和图像到视频任务,以及之前的T2I和T2V任务。本文保持MLLM冻结,仅训练连接器和MM-DiT。此阶段使UniVideo能够在多模态指令下统一广泛的视频生成和编辑任务。任务分解、训练设置和数据集构建的详细信息见下表1和下表2。


实验
首先描述实现细节。然后展示主要结果。对UniVideo在广泛的视频理解和生成任务中与最先进方法进行了全面的基准测试。结果显示了UniVideo在所有设置中的强大统一能力。接下来,展示了UniVideo的零样本泛化能力,并分析其视觉提示理解能力。最后,通过消融研究验证UniVideo的设计选择。
实现细节
采用qwen2.5VL-7B作为MLLM主干,采用HunyuanVideo-T2V13B作为MMDiT主干。原始的HunyuanVideo使用两个文本编码器;本文移除了它们,转而使用qwen2.5VL作为统一的多模态嵌入器。为了对齐qwen2.5VL和HunyuanVideo之间的特征维度,应用了一个4倍扩展的MLP。训练在32块H100 GPU上进行。
主要结果
视觉理解与生成
UniVideo的视觉理解由一个冻结的预训练MLLM驱动。冻结MLLM保留了其强大的原生理解能力,并防止与生成任务联合训练时的性能下降。如下表3所示,UniVideo在理解任务上取得了83.5(MMBench)、58.6(MMMU)和66.6(MM-Vet)的竞争性得分。同时,它保留了强大的生成能力,在单一统一模型中支持I2V和T2V。相比之下,基线模型依赖于不同任务的不同变体,而UniVideo在VBench基准测试中达到了与HunyuanVideo主干相当的性能。

上下文视频生成
基准测试: 遵循FullDiT和OmniGen2,本文构建了一个测试集,涵盖单ID和多ID视频生成场景。在单ID设置中,主体可能有多个参考图像(例如,一个人或物体的不同视角)。在多ID设置中,参考包括2-4个不同的身份。详细信息见附录。
指标: 本文进行人类评估和自动指标评估。对于人类评估,本文遵循Instruct-Imagen和OmniGen2的协议进行系统研究。每个样本由至少三名注释者对以下方面进行评分:(i)主体一致性(SC),(ii)提示遵循(PF),以及(iii)整体视频质量(Overall)。每个类别的分数从中选择,其中0表示不一致或质量极差,1表示完全一致或高质量。对于自动评估,本文采用VBench (Huang et al., 2024)中的三个指标:平滑度、动态性和美学。
基线: 由于能够进行上下文生成的视频模型稀缺,本文将UniVideo与最先进的开源模型VACE进行比较。本文还包括了商业基线,如Pika2.2和Kling1.6。
结果: 定量比较如下表4所示。UniVideo在所有指标上均表现出优于或与基线相当的性能。附加结果见下图4,更多示例可在本文的项目网站上查看。值得注意的是,基线模型在处理涉及多个身份的复杂指令时(例如,当参考图像数量为4时)常常遇到困难,而UniVideo能够准确遵循指令,同时保持身份一致性。


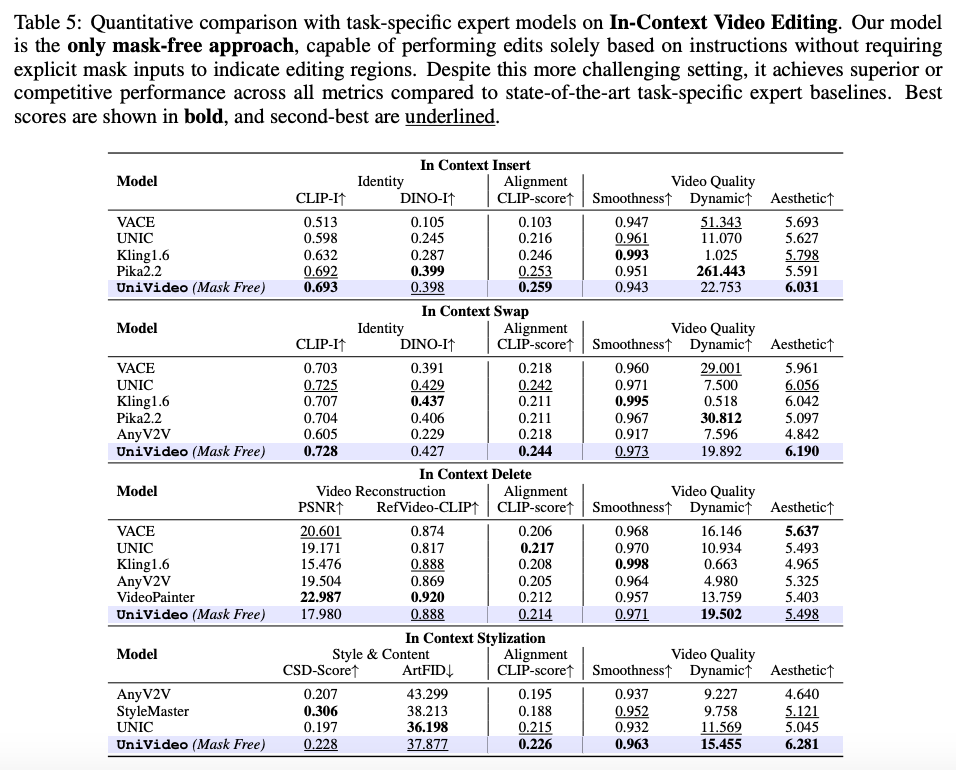
上下文视频编辑
基准测试: 遵循UNIC,本文构建了一个测试集,涵盖四种编辑类型:交换、删除、添加和风格转换。每个例子由一个源视频和一个参考图像组成,并附有自然语言指令。
指标: 采用UNIC的评估协议,并进行自动指标评估。具体来说,本文使用CLIP-I和DINO-I来衡量身份一致性,并使用CLIPScore来衡量提示遵循。
基线: 将UniVideo与最先进的任务特定专家模型进行比较,包括UNIC、AnyV2V和VideoPainter。本文还评估了商业模型,如Pika2.2和Kling1.6。需要注意的是,所有基线模型都需要显式的掩码输入以定位编辑区域并指导生成,而UniVideo在没有掩码的情况下运行。
结果: 定量比较如下表5所示。尽管UniVideo在更具挑战性的无掩码设置下进行评估,但在所有指标上仍然表现出优于或与基线相当的性能。附加结果见图4,更多示例可在本文的项目网站上查看。UniVideo能够准确遵循指令,同时保持参考图像的身份。
模型分析
零样本泛化
观察到UniVideo的两种泛化能力。尽管UniVideo的训练数据不包括通用的自由形式视频编辑任务(见上表1),但它将这种能力从多样的图像编辑数据和上下文视频编辑数据(限于ID删除、交换、添加和风格化)转移到视频领域,使其能够处理自由形式的视频编辑指令(例如,更改材料或环境)。令人惊讶的是,本文发现UniVideo可以执行从视频中绿幕角色的任务。本文还观察到UniVideo能够处理任务组合。它可以将上下文编辑与风格转换结合,或同时执行多个编辑(例如,删除一个身份同时添加另一个)。演示见下图5。

视觉提示理解
在下图6中展示了UniVideo进行视觉提示的结果。本文考虑两种类型的视觉提示。在第一种设置中,用户在画布上绘制参考图像和故事计划。此时,模型可以解释计划并生成相应的视频。在第二种设置中,注释直接绘制在输入图像上,模型将其视为I2V任务;在这种情况下,UniVideo可以解释视觉提示所描述的运动或新事件。这些结果突显了UniVideo在处理复杂多模态指令方面的优势。尽管定性结果是在零样本设置下获得的,但未来在任务特定数据上的端到端训练可能会进一步提高性能。

消融研究
本文的消融研究解决了两个核心问题:(i)与单任务学习相比,多任务学习是否提高了性能?(ii)本文的模型设计是否有效?具体来说,视觉嵌入是否应该同时流向MLLM和MMDiT分支?本文在上下文视频编辑和上下文视频生成中进行人工评估,使用与前文相同的评估协议。(i)为了研究多任务学习,本文将UniVideo与单任务基线进行比较。单任务基线与UniVideo共享相同的架构,但每个任务需要独立的模型,并且仅能访问任务特定的数据。下表6中的结果展示了多任务学习的有效性,特别是在编辑任务中,UniVideo在联合学习期间受益于大规模图像编辑数据。(ii)为了评估流式视觉输入的影响,本文将UniVideo与共享相同架构的变体进行比较:- 不使用MMDiT的视觉输入:视觉输入仅馈送到MLLM分支。正如下表7所示,仅将视觉输入馈送到MLLM会导致身份保持能力显著下降。

结论
UniVideo,这是一种用于视频理解、生成和编辑的统一多模态生成模型。通过将用于语义理解的MLLM与用于生成的MMDiT相结合,UniVideo结合了强大的多模态推理与细粒度的视觉一致性。它可以有效地解释多模态指令并处理多样化的任务。本文的实验表明,UniVideo不仅在文本/图像到视频、视频编辑和上下文生成方面匹配或超越了任务特定的基线,而且在未见过的任务和新颖的任务组合上也能泛化——这是专业管道难以实现的能力。除了稳健的性能,UniVideo还支持视觉提示理解,强调了统一建模相对于碎片化方法的优势。展望未来,UniVideo为多模态研究开辟了新方向,推动本文迈向能够通过语言、图像和视频自然交流的助手。
参考文献
[1] UniVideo: Unified Understanding, Generation, and Editing for Videos
技术交流社区免费开放
涉及 内容生成/理解(图像、视频、语音、文本、3D/4D等)、大模型、具身智能、自动驾驶、深度学习及传统视觉等多个不同方向。这个社群更加适合记录和积累,方便回溯和复盘。愿景是联结数十万AIGC开发者、研究者和爱好者,解决从理论到实战中遇到的具体问题。倡导深度讨论,确保每个提问都能得到认真对待。


技术交流
加入「AI生成未来社区」群聊,一起交流讨论,涉及 图像生成、视频生成、3D生成、具身智能等多个不同方向,备注不同方向邀请入群!可添加小助手备注方向加群!











