

在图片生成领域,如何从基础的“能生”,发展到更高层次的“精准可控”,一直是行业关注的重点。特别是对于复杂场景下的多实例图像生成(Multi-Instance Generation, MIG),更是对精确空间控制和主体身份保真的双重挑战。
当你希望在一张图片中放置多个指定人物或物体并精确控制他们的位置,同时要求他们的面部特征与提供的参考图尽量一致时,传统的扩散模型(Diffusion Models)往往会遇到两个关键挑战:
空间定位漂移(Inadequate Position Control) :现有布局引导方法难以实现高精度的空间定位,生成的物体可能偏离用户指定的布局框(Bounding Box)。 多主体身份失真(Weak Identity Preservation) :当需要生成两个或更多不同主体时,模型易出现细节模糊、特征丢失,甚至不同主体间身份特征相互融合(串扰)的问题,参考图像越多,问题越突出。
这些挑战,是限制可控图像生成走向大规模商业化和专业化应用的关键因素。
近期,一项新的技术方案被提出,旨在解决上述问题!
浙江大学 ReLER 团队 提出 ContextGen 框架,旨在通过统一的 Diffusion Transformer (DiT) 架构,有效应对“布局”与“身份”双重可控难题。ContextGen 框架在控制精度和细节保真度上实现了显著提升,并在权威基准测试中,与包括 GPT-4o 和 Nano Banana 在内的现有领先模型进行了对比,展现了其竞争力,为多实例可控生成领域带来了一项有价值的探索。
这项研究有助于推动图像生成技术在多实例精准可控方向上的发展。

论文链接:https://arxiv.org/abs/2510.11000
项目页面:https://nenhang.github.io/ContextGen/
创新核心:上下文融合与双重注意力锚定
ContextGen 的设计理念是:以统一的上下文框架,同时锚定空间布局和主体身份。
传统的解决方案往往是分别处理布局和身份问题。ContextGen 首次将 复合布局图像(Composite Layout Image) 和 高保真参考图像(High-fidelity Reference Images) 这两种关键模态统一到一个上下文(Contextual Framework) 中。
通过这种上下文整合,模型能够同时获得全局的空间结构信息和实例级的细节信息,从而实现精确的空间控制和高保真的身份一致性。
ContextGen 的成功得益于其两大技术贡献:上下文布局锚定(Contextual Layout Anchoring, CLA)和身份一致性注意力(Identity Consistency Attention, ICA)。
1. Contextual Layout Anchoring (CLA):实现空间定位指导
CLA 机制是指导物体精确落位的关键机制。它通过将复合布局图像整合到生成上下文(Generation Context)中,指导模型将待生成的实例牢固地“锚定”在用户指定的位置上。
机制解析: 研究团队将 CLA 机制策略性地部署在DiT 的前层(Front Blocks)和后层(Back Blocks),这些层级通常负责处理全局上下文和宏观结构,有助于确保整体图像的合成结构正确,减少对象错位或重叠问题。 输入优化: 布局图像可以由用户手动设计,以实现控制自由度;也可以由 ContextGen 的自动排序算法合成,确保在复杂场景下,布局信息得到有效编码。
2. Identity Consistency Attention (ICA):实现高保真身份细节转移
ICA 机制的目标是解决身份保真问题。ICA 是一种注意力机制,其核心功能是将高保真的参考图像信息,以实例级的方式,精确地注入到目标生成区域。
机制解析: 与 CLA 关注全局结构不同,ICA 被部署在 DiT 的中层(Middle Blocks),因为这些层级对实例特有的属性和细节(如面部表情、衣物质地、纹理等)具有较显著的影响力。 专一连接: ICA 的注意力掩码(Attention Mask, )设计确保了目标图像中某个特定实例区域 (Query Token ),只会与 其对应的参考图像标记(Reference Token ) 建立强制连接。这种连接设计,有助于阻断不同主体之间信息的串扰和泄露,从而在多实例场景下实现可靠的身份细节转移。
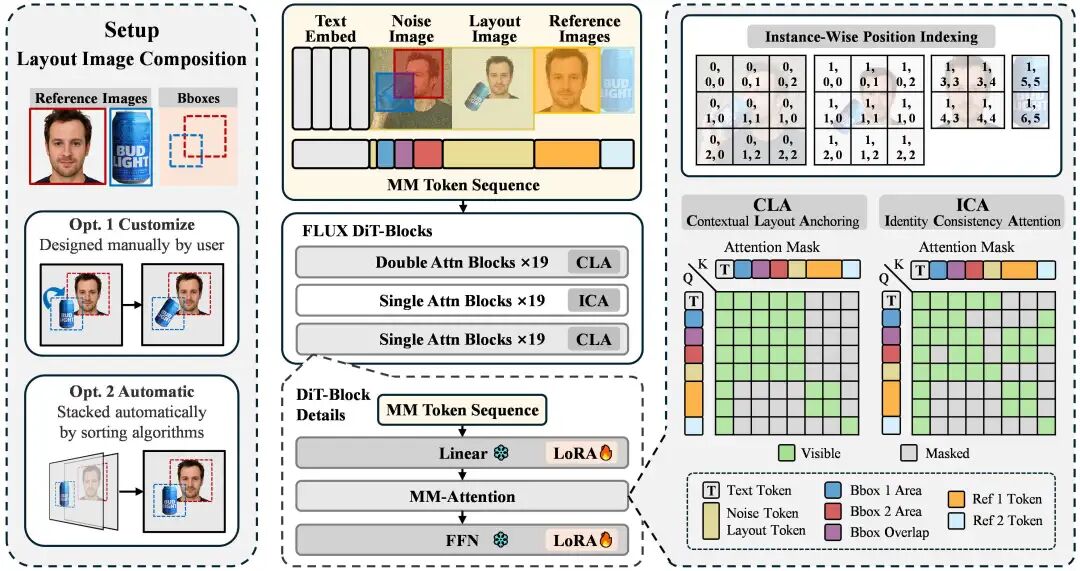
3. 增强的位置索引:多模态信息流的精准导航
为了让模型在处理文本、噪声图像、布局图像和多个参考图像构成的统一 Token 序列时,能够区分来自不同模态和不同参考图的 Token,ContextGen 采用了增强的实例级位置索引策略(Instance-Wise Position Indexing)。通过为每个辅助输入(Layout Image、Ref Images)分配独特的、非重叠的累积偏移位置索引,模型得以在统一的注意力机制中,精确地区分和处理每一个输入的特征。
数据集探索:首个大规模多实例生成数据集 IMIG-100K
高质量的数据集是模型性能的基础。现有的数据集大多存在通用性有余而缺乏细致的布局和身份注解的问题。
为填补这一空白,ContextGen 团队同步推出了IMIG-100K,这是首个包含详细布局和身份标注的大规模、分层结构图像引导多实例生成数据集(IMIG)。
IMIG-100K 数据集系统地构建了三个专门的子集,共同用于训练 ContextGen 的多样化能力:
基础实例构成 (Basic Instance Composition, 50K 样本):专注于基础的构图能力,确保模型掌握物体间的基本空间关系。 复杂实例交互(Complex Instance Interaction, 50K 样本): 专为复杂场景设计,每张图最多包含 8 个实例,并模拟了真实世界的复杂交互,如遮挡、视角旋转和姿态变化,提升了模型的鲁棒性。 灵活参考组合(Flexible Composition with References, 10K 样本): 这是一个独特的子集,用于训练模型应对低一致性输入的泛化能力,例如,参考图和目标生成图中的实例可能存在较大的形变或风格变化,但模型仍需保持核心身份一致。

实验验证:在多项任务中表现突出
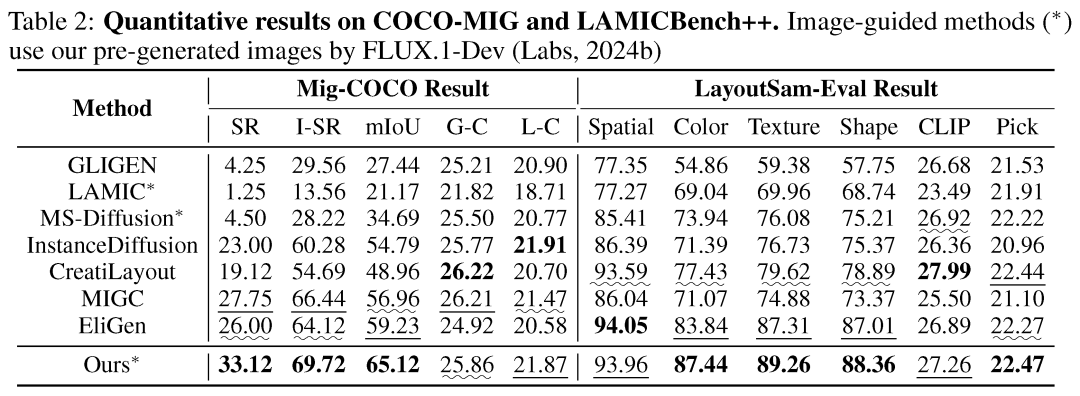
ContextGen 的性能在三大基准测试中得到验证,包括身份保真(LAMICBench++)、复杂布局控制与属性绑定(COCO-MIG)和细粒度文本布局控制生成(LayoutSAM-Eval)。
1. 身份保真:LAMICBench++ 对比领先模型
LAMICBench++ 是评估主体驱动生成中身份保持和特征一致性的基准。ContextGen 在此基准上获得了64.66的平均得分。这一结果与现有领先的开源模型(如 OmniGen2 的 61.08 分)和部分商业模型(如 GPT-4o、Nano Banana)相比,体现了其在身份保持方面的优势。
在 身份保留分数(IDS) 和 物体保真度(IPS) 上,ContextGen 展现了较强的竞争力。
IDS 提升显著: 在更多主体(大于等于 4 个参考图)的挑战场景中,ContextGen 的 IDS 评分达到30.42,相比之下,GPT-4o 为 17.12,Nano Banana 为 16.67,显示出更强的多主体身份保持能力。

定性结果: 从定性结果可以看到,在生成“老人与像素化武士”、“花束与甜甜圈”等复杂场景时,ContextGen 能够较好地保持人物脸部的皱纹细节、花瓶的特定形状、猫咪的毛发纹理等细微特征,并能敏感处理光照和姿态变化,生成的图像更具真实感和细节丰富度。

2. 布局控制和细粒度属性控制:COCO-MIG 空间精度表现良好 / LayoutSAM-Eval 颜色纹理表现突出
空间精度提升: 在 COCO-MIG 基准上,ContextGen 在图像级成功率(SR)、实例级成功率(I-SR)和空间准确性(mIoU)上表现良好。 属性绑定鲁棒: 在 LayoutSAM-Eval 基准上,ContextGen 凭借其双重注意力机制带来的细节注入能力,在纹理(Texture)和颜色(Color)两项细粒度指标上获得了较高的分数。
复杂场景处理: ContextGen 能够有效处理布局稠密、实例重叠等复杂情况,这对于现有方法来说是常见的挑战。


幕后揭秘:ICA 的“中层”部署与 DPO 的调校
为了最大化性能,研究团队还进行了消融实验,验证了关键组件的有效性。
1. ICA 的位置:中层部署是关键
消融实验证实了 ICA 机制必须应用于 DiT 的中层(MID-19 Blocks) 才能发挥最大效用。
如果仅使用 CLA 机制(相当于将 CLA 作用于所有层),平均分(AVG)仅为 58.03。 当 ICA 仅应用于中层时,IDS 分数显著提高,平均分达到最高。
这一发现为 DiT 架构设计提供了关键指导:全局结构锚定可由前后层负责,而细致的实例身份细节注入,在中层集中处理更为有效。

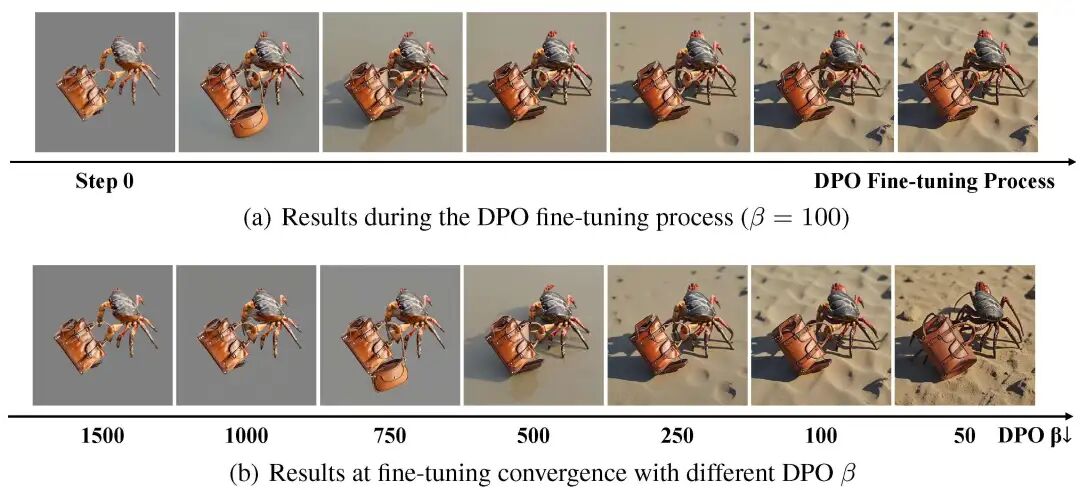
2. DPO 微调:平衡身份保持与场景适应性
模型在保持身份时,有时会过于“死板”,倾向于严格复制参考图像的姿态和光照,而忽略了目标场景的整体和谐性。为此,团队采用了 DPO(Direct Preference Optimization) 进行微调,将目标图像设为偏好样本,布局图像设为非偏好样本。
实验证明,DPO 微调有效地改善了模型的图文一致性和美学分数。它在保持身份细节和适应场景变化之间找到了一个平衡点,有助于确保最终生成图像的“神似”与“形合”。
总结与展望:推动可控 AIGC 发展的重要一步
ContextGen 框架以其创新的 上下文布局锚定(CLA) 和 身份一致性注意力(ICA) 机制,为图像生成领域提供了新的解决方案。它在技术上实现了布局与身份的双重可控,并在基准上展现了与现有领先技术竞争的实力。
ReLER 团队指出,未来的探索方向在于进一步提升其场景适应性。 当前 ContextGen 强大的身份一致性机制,旨在确保在多实例复杂场景下核心主体身份保持的鲁棒性。研究团队正在积极攻克下一阶段的目标:在保持高保真身份的同时,实现对目标场景光照、姿态、色彩等环境要素的更精细、更灵活的融合与适应,推动 ContextGen 走向身份保真与场景和谐性的更高程度的统一。
作者介绍
Ruihang Xu
所属院校:浙江大学计算机科学与技术学院本科生 研究兴趣:计算机视觉、智能体强化学习 电子邮箱:ruihangxu@zju.edu.cn
团队介绍
浙江大学 ReLER 实验室(Recognition, Learning, and Reasoning Laboratory)
研究领域:人工智能、计算机视觉、机器学习、三维重建、视频处理 负责人:杨易教授[1],浙江大学教授,专长于计算机视觉和多模态学习与推理。
杨易教授: https://scholar.google.com/citations?user=RMSuNFwAAAAJ&hl=en









![[生态进展] VSCode RISC-V 插件正式支持进迭时空(SpacemiT)AI 拓展指令集](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2026-03-02/69a57ce3423bf.jpeg)
