Vision-Language-Action(VLA)模型通过融合视觉、语言与动作,为机器人带来了强大的零样本与跨任务泛化能力。但仅依赖模仿学习的 VLA 在真实世界 OOD 场景中仍然脆弱,缺乏失败恢复、自主探索与闭环纠错能力。
强化学习(RL)正成为连接 VLA 预训练与真实部署的关键桥梁。
由南洋理工大学、北京邮电大学、清华大学联合推出,本综述系统梳理了 RL-VLA 在“学习—优化—部署”全生命周期中的核心方法与挑战,并从四个维度构建了完整技术图景:架构、训练范式、真实世界部署以及评估。

📝论文链接(每月更新):https://doi.org/10.36227/techrxiv.176531955.54563920/v1
🌟GitHub链接(每周更新):https://github.com/Denghaoyuan123/Awesome-RL-VLA
一、RL-VLA 架构:从开环推理到闭环优化
RL 通过奖励驱动的策略更新,使 VLA 从“复现示范”转向“结果导向”的闭环决策:
动作建模
-
自回归 VLA:通过 token-level RL(如 TGRPO、GRPO)实现稳定优化。【核心挑战】:离散动作令牌难以实现**灵巧操作 (dexterous manipulation)**,细粒度分词会增加预测难度。 -
生成式 VLA:在扩散 / Flow 动作空间中进行 sequence-level RL(如 πRL、FPO)【核心挑战】:生成式 VLA 依赖局部采样和不完美的信号,可能导致动作分布随迭代更新而扭曲或崩溃 -
双系统结构:RL 用于对齐高层 VLM 规划与低层 VLA 控制(如 Hume)【核心挑战】:VLM 规划器和 VLA 控制器之间的异构表示和时间尺度可能导致价值估计不一致,联合 RL 训练不稳定。
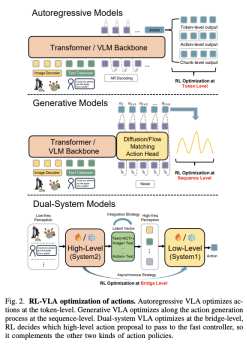
奖励设计
为了克服模仿学习的局限性并解决奖励稀疏性问题,RL-VLA 采用多种奖励信号:
-
内在奖励**(Intrinsic Rewards):基于自我监督或探索驱动,鼓励智能体探索新状态(RND、PBRS)。【核心挑战】:缺乏与任务目标的显式对齐,可能导致奖励欺骗 (reward hacking),** 或策略利用容易的内在奖励源而不推进任务。 -
外在奖励**(Extrinsic Rewards)**:来自人类偏好或基础模型(RLHF、Eureka、VLAC),更具任务对齐性
Transition建模
-
物理模拟器**(Physics-based Simulator)**(Isaac Sim、Gazebo): 通过精确的物理建模(如 Isaac Sim、Gazebo)复制环境动力学。【核心挑战】: 构建高保真模拟器需要大量人工投入,且计算成本高。 -
学习型世界模型**(Learning-based World Model)**(VLA-RFT、World-Env),数据驱动,从大规模演示中直接预测未来状态。推动基于模型的 RL-VLA

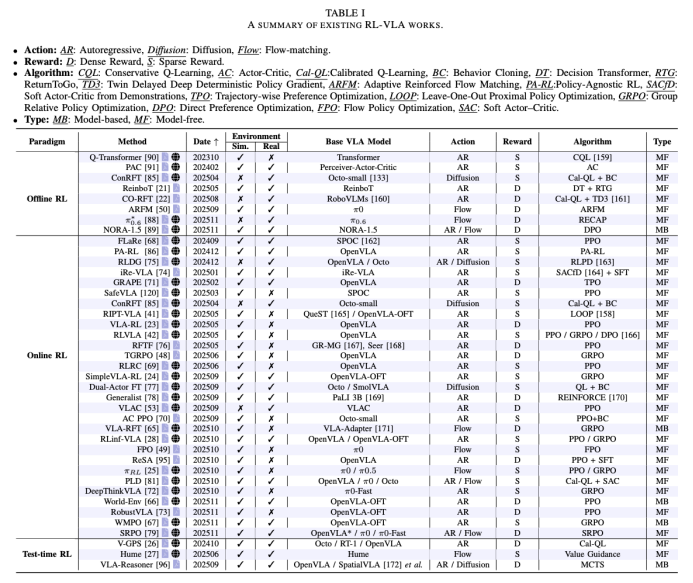
二、RL-VLA 训练范式深度拆解
RL-VLA 的训练范式根据智能体获取和利用环境反馈的方式,分为三种类型:
Online RL-VLA (在线强化学习)
智能体在训练过程中与环境持续交互,通过试错收集轨迹并更新策略,赋予 VLA 适应性闭环控制能力。
-
策略优化: 采用 PPO 变体(如 FLaRe、RLRC、SimpleVLA-RL 使用 GRPO)来平衡学习效率和稳定性。 -
_实证研究_:RLVLA 比较了 DPO、PPO 和 GRPO 算法,证明 RL 微调相比标准 SFT 能显著增强 OOD 场景下的泛化能力。 -
样本效率: 通过结合人类专家演示(RLDG)或集成 Actor-Critic 架构提供密集信号(VLAC),在有限预算下学习有效策略。 -
主动探索: 设计高效的探索策略以指导智能体生成更高性能的动作样本。例如,Plan-Seq-Learn 使用 LLM 生成高层任务规划来指导低层 RL 策略的探索。RESample 自动生成具有挑战性的 OOD 数据,创建失败和恢复轨迹。 -
训练稳定性: 通过动态推演采样(RIPT-VLA)或利用世界模型作为模拟器生成合成推演(World-Env),降低真实世界互动带来的方差和不稳定。
【核心挑战】:非平稳动力学和多模态噪声使策略优化难以维持稳定可靠的更新。
Offline RL-VLA (离线强化学习)
在不与环境交互的情况下,利用固定、静态数据集训练 VLA 模型。相比模仿学习,离线 RL-VLA 优化了来自过往经验的长期奖励,提升 OOD 泛化能力
数据利用:
-
保守约束: 限制策略更新,防止偏离数据集覆盖的分布(例如 CO-RFT、ConRFT 利用 Cal-QL 机制)。
-
定制化表示: 通过重塑轨迹或生成奖励(例如 ReinboT 优化累积奖励,_π_∗0.6 利用预训练价值函数)。
目标修改:
-
架构感知目标: 设计与 VLA 结构相匹配的 RL 目标(例如 ARFM 针对 Flow-based VLA)。
-
数据驱动目标适应: 利用 RL 目标增强离线数据集,生成高质量的合成轨迹(例如 RL-100)。
【核心挑战】:数据集的不平衡性和不完整的奖励信号限制了泛化能力。
3.Test-time RL-VLA (测试时强化学习)
在部署过程中,VLA 通过轻量级更新或适配器模块调整行为,无需进行全面的模型微调。
-
价值指导: 利用预训练的奖励或价值函数直接影响动作选择(例如 V-GPS 重新排序动作候选项,Hume 引入“价值引导思维”) -
内存缓冲指导: 在推理时检索相关的历史经验(例如 STRAP、ReSA)以提高探索效率和知识复用。 -
规划引导适应: 显式推理未来的动作序列以选择最优动作(例如 VLA-Reasoner 使用在线 MCTS(蒙特卡洛树搜索),BGR 利用价值函数进行进度监控和错误纠正)。
【核心挑战】_:_ 预推理未来动作序列和评估大量动作候选带来了显著的计算成本,限制了实时部署能力。
三、 RL-VLA 的真机部署:从虚拟到物理世界的飞跃 (Real-World Deployment)
真实世界部署是指在物理机器人上运行 RL-VLA 模型,实现在非结构化环境中的安全和自主操作。现有研究主要通过 Sim-to-Real 迁移和物理世界 RL 来应对样本效率、安全性和硬件限制等挑战。
A. Sim-to-Real 迁移:弥合虚拟与现实的鸿沟
Sim-to-Real 迁移的目标是让在模拟环境中训练的 VLA 模型能够有效地泛化到物理机器人上,解决领域迁移(distribution shift)问题。
1.领域随机化 (Domain Randomization, DR):
-
通过随机化广泛的模拟参数(如照明条件、背景纹理、执行器噪声),来匹配真实世界中遇到的感知多样性。 -
例如,SimpleVLA-RL 模型通过在多样化任务模拟中应用 DR,实现了对真实机器人的**零样本迁移 (zero-shot transfer)**,无需额外的微调。
2.数字孪生 (Digital Twin, DT):
-
创建物理系统的同步虚拟副本,实现安全和可扩展的策略训练。 -
实时校正: Real-Is-Sim 持续使用真实传感器流校正动态数字孪生,确保策略始终在熟悉的模拟器域内运行。 -
数据生成: RoboTwin 利用生成式框架,将单个 2D 图像转换为多样化、可交互的 DTs,并作为双臂操作的基准。 -
可微分引擎: DREAM 提出了一个实转模转实(real-to-sim-to-real)框架,利用可微分的高斯溅射(Gaussian Splat)创建高保真 DTs,用于训练力感知抓取策略。
挑战: 尽管取得了显著进展,但迁移后的策略表现仍逊于模拟环境中的表现。例如,SimpleVLA-RL 在物理机器人上的成功率远低于模拟环境,表明仅靠模拟训练不足以保证 VLA 在现实世界中的可靠部署。
B. 物理世界强化学习 (Real-world RL):追求自主性与安全性
物理世界 RL 直接在真实机器人上训练操作策略,但这带来了样本效率低下和安全风险等重大挑战。
通过将人类专业知识整合到策略学习过程中,加速收敛并减少不安全探索。
-
人类纠正干预 (Corrective Intervention): 人类提供实时反馈以纠正机器人动作,加速技能获取和安全探索。HIL-SERL 引入人机回路强化学习,通过人类反馈快速获得灵巧操作技能。DAFT 将自然语言反馈转化为语义化的纠正动作。ConRFT 也将人类干预整合到 RL 对 VLA 的微调中。 -
人类恢复辅助 (Recovery Assistance): 在自主恢复不可靠时,人类手动介入重置机器人或环境,减少失败的影响。ARMADA 和 RaC 集成了基于学习的恢复模块,并在恢复不可行时请求人类指导。Generalist 和 VLAC 则将人类协助限制在执行环境重置上。 -
人类课程任务设计 (Curriculum Task Design): 人类主管设计课程,将任务从简单到复杂组织起来,以平衡安全性和学习效率。MT-Opt 通过性能指标控制部署阈值。
挑战: 现有的 HiL 方法仍然严重依赖人类干预样本,导致人力成本高昂且可扩展性差,限制了大规模部署。
机器人能够在发生故障后自行处理并继续学习,减少人工重置和劳动成本。
-
免重置学习 (Reset-free Learning): 引入辅助重置策略(如 LNT、MEDAL、IBC)将智能体带回初始状态或可恢复区域,实现持续训练。 -
语义感知恢复 (Semantic-aware Recovery): 强调对操作时空动态的推理,通过语言模型(如 PaLM-E)或本体论(ontology)来解释故障原因并规划适当的恢复行为(如 RECOVER)。
挑战: 真实世界交互的固有不可逆性、部分可观察性以及长期训练的不稳定性阻碍了在复杂环境中实现可靠的故障检测和恢复执行。
3.安全探索 (Safe Exploration):
在经验收集过程中,确保智能体避免与物理环境发生不安全的互动。
-
保守安全评论家 (Conservative Safety Critics): 训练辅助评论家来评估动作提议违反安全约束的可能性(如 Recovery RL 学习安全恢复区域,SLAC 利用模拟预训练的潜动作空间来约束探索)。 -
实时安全执行 (Real-time Safety Enforcement): 在执行层面应用控制理论安全约束,例如使用阻抗控制器来限制末端执行器的力和速度。SafeVLA 模型通过约束学习 (Constrained Learning),从最小-最大视角优化 VLA,以应对安全风险,从而实现安全性-性能的权衡。
挑战: 最大的挑战在于高层语义推理与低层安全保障的整合。当前的框架难以将抽象的语义规则(如“小心处理易碎物体”)与必须执行物理约束(如“特定扭矩或速度限制”)的低层控制策略对齐。
四、评测与基准:RL-VLA 应该如何被“正确比较”?
评估是 RL-VLA 研究中尚未统一但极其关键的一环:
-
仿真基准:LIBERO、ManiSkill、CALVIN、RoboTwin 等,用于分析泛化与算法对比 -
真实世界基准:LeRobot、SERL,更贴近部署挑战 -
评测难点: -
成功率难以反映恢复能力与安全性 -
不同 RL 范式、不同动作表示间缺乏可比性 -
长时序任务与真实物理约束评估不足
未来评测需要从单次成功率走向鲁棒性、可恢复性与长期自主性。

五、Open Challenges & 展望
RL-VLA 通过 RL 驱动的闭环优化,克服了模仿学习在 OOD 场景中的根本限制,使其策略更具泛化能力和鲁棒性。
尽管 RL-VLA 已展现出巨大潜力,但距离通用具身智能仍存在关键挑战:
|
开放挑战 (Open Challenges) |
解决方案 (Promising Solutions) |
关键目标 |
|
长序列任务的扩展性 |
记忆检索机制和思维链式监督,保持长期时间一致性。 |
稳健的长期推理 |
|
样本效率低下 |
基于模型的强化学习 (MBRL),通过预测世界模型进行可扩展的训练。 |
提高效率和可扩展性 |
|
真实机器人训练成本 |
自主故障处理智能体;多机器人共享训练与实转模模拟推演。 |
减少人类干预,提高效率 |
|
安全性和风险感知 |
预测风险建模;基于约束的策略优化(如 SafeVLA)和语言条件下的安全推理。 |
确保可靠的物理操作 |
强化学习正在推动 VLA 从“高性能模仿者”进化为“具备自主探索、恢复与安全决策能力的通用机器人系统”。










