HALLUGUARD团队 投稿
量子位 | 公众号 QbitAI
在真实应用中,LLM幻觉远比你想象得复杂。
来自弗吉尼亚理工等机构的重磅研究,第一次用统一理论解释:为什么LLM会产生幻觉?又为什么越推理越离谱?
在医疗、法律、科研等高风险场景,“幻觉”正在成为大模型落地的最后一道坎。
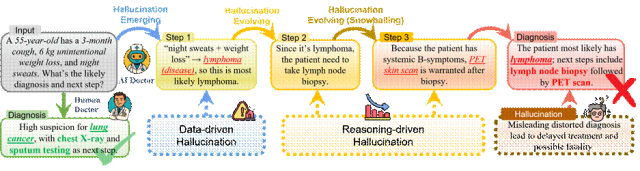
你可能已经见过这些情况:
回答看起来很自信,但事实是错的 单步回答没问题,一到多步推理就开始崩 前半段正确,后半段却被自己“带跑偏”
问题是:这些幻觉,真的是同一种问题吗?
幻觉不是一种,而是两种,而且会“演化”
来自弗吉尼亚理工大学、MIT、达特茅斯学院等机构的研究团队,在ICLR 2026发表论文HALLUGUARD,首次从理论上给出明确答案:
LLM幻觉并非单一来源,而是由两类机制共同作用、逐步演化而成。

两大根源,第一次被严格区分:
1. 数据驱动型幻觉(Data-driven)
来源:预训练/微调阶段的知识缺失、偏差、分布错配 表现:模型“本来就不知道,却说得很像真的”
2. 推理驱动型幻觉(Reasoning-driven)
来源:推理时的不稳定解码、多步逻辑放大 表现:模型“一开始对,但越推越歪”
更关键的是:真实幻觉往往不是“二选一”,而是先错在数据,再被推理放大。
理论突破:首个“幻觉风险界”,解释幻觉如何产生和放大
论文提出一个全新的理论框架——Hallucination Risk Bound(幻觉风险界)

它首次在数学上证明:整体幻觉风险=数据误差+推理不稳定误差
并进一步揭示了两个关键机制:
数据驱动项:与模型表征能力、预训练–任务分布错配密切相关
推理驱动项:在多步生成中会随推理长度指数级放大
一句话总结就是:
幻觉不是“突然出现”,而是“被一步步推出来的”。
这也是为什么很多模型:短回答还行,一到长链条推理就全面失控。
HALLUGUARD:一个真正“统一”的幻觉检测器
有了理论,下一步是:幻觉能不能测出来?
研究团队提出了HALLUGUARD——一个基于神经切线核(NTK)几何结构的幻觉评分函数,核心特点是:
同时覆盖两类幻觉(数据+推理) 无需外部知识或检索 无需人工标注,零监督 推理阶段零额外开销,可直接部署

直观理解它在做什么:
用NTK的谱结构判断模型“是不是学对了” 用解码Jacobian的放大效应衡量“推理会不会失控” 把“知识偏差+推理漂移”统一压缩成一个稳定分数
不是靠经验规则,而是从模型内部结构出发。
实验实锤:10个基准×9大模型,全面SOTA
HALLUGUARD在10个幻觉基准、11种主流方法、9个LLM backbone上全面测试,涵盖:
事实型QA(SQuAD、RAGTruth) 多步推理(GSM8K、MATH-500、BBH) 指令跟随&开放生成(TruthfulQA、HaluEval)
结果非常一致:
在推理型任务上优势最明显 在小模型(7B级)上提升最大,最高超过10% 显著超越SelfCheckGPT、Inside、RACE等主流方法

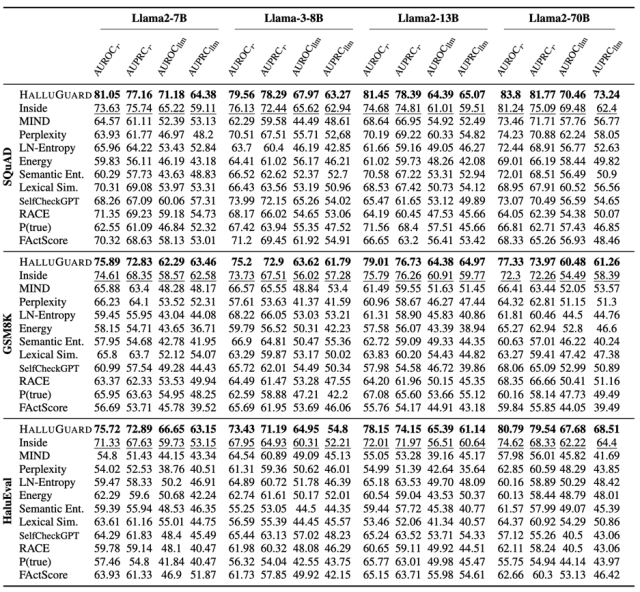
更重要的是消融实验表明:
数据型任务由“数据项”主导,推理型任务由“推理项”主导,由此理论与实验,完全对齐。

不止检测,还能直接“救推理”
HALLUGUARD不只是事后“报警器”。
研究发现:把HALLUGUARD作为推理时的评分信号,直接嵌入Beam Search:
MATH-500准确率:72.7%→81.0%
指令任务提升近16%
这意味着:幻觉检测可以反过来指导模型走“更稳”的推理路径。

HALLUGUARD的意义,不只是多了一个检测指标,而是:
第一次统一解释幻觉的“来源+演化” 第一次把理论分解落到可计算指标 第一次证明幻觉检测能反哺推理本身
这为高风险场景下的LLM部署,提供了一条从“经验补丁”走向“理论可控”的路径。

论文名称:
HALLUGUARD: Demystifying Data-Driven and Reasoning-Driven Hallucinations in LLMs
会议:
ICLR 2026
作者:
Xinyue Zeng, Junhong Lin, Yujun Yan, Feng Guo, Liang Shi, Jun Wu, Dawei Zhou
机构:
Virginia Tech, MIT, Dartmouth College等
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟










