摘要
Abstract
构建通用智能机器人一直是机器人研究的核心目标之一。一个颇具前景的路径是模仿人类的进化轨迹:通过与环境持续互动不断学习,在初始阶段通过模仿人类行为,加速技能的学习与迁移。实现这一目标面临三大核心挑战:
(1)设计具备高度类人操作能力且安全可靠的机器人硬件;
(2)开发直观且可扩展的全身遥操作系统,以采集高质量人类演示数据;
(3)构建能够从人类演示中学习的全身视觉-运动策略的高效算法。
为统一解决以上挑战,星尘智能提出 Astribot Suite ——一套面向多样化真实环境、聚焦全身操作的机器人学习套件,致力于让机器人掌握广泛的日常任务。

项目地址:
https://arxiv.org/abs/2507.17141
在日常环境中实现机器人全身自主操控面临三大基本挑战。
首先,它需要精心设计的机器人硬件,不仅要能安全得在人类环境中部署,还要展现出人类水平的运动能力和表达能力。
其次,一个直观且可扩展的数据收集方式至关重要,目标是使非专业人士能以自然高效的方式执行各种日常任务。
第三,需要能捕捉全身控制复杂性的学习模型,兼具可扩展性以及推广到开放世界环境和任务的潜力。
为应对上述挑战,我们通过引入一个统一的框架来学习真实环境中的全身操作任务。框架由三个核心组件组成:
首先开发一个高性能机器人平台——具有灵活躯干和移动底座的双臂机器人——旨在高效而优雅得模拟人类操作行为。
其次引入了一个全身遥操作系统,优先考虑普遍适用于广泛的任务、高可用性和低延迟,让非专家用户能够进行高效的数据收集。
最后提出全身视觉运动策略 (DuoCore-WB)——一个简单而有效的学习算法,使用 RGB 观测和精心设计的动作表示来学习协调的全身动作。
1.高性能机器人平台
我们的机器人平台是一款高性能、坚固耐用、具备安全移动操作能力的机器人,为通用任务而设计。它采用创新的绳驱设计,能够模拟人体肌肉组织,实现柔顺运动和精准施力。与传统的刚性连杆机器人相比,我们的设计具有更高的有效载荷能力、更低的反冲和惯性、更紧凑的结构及更高的操作安全性。其轻量化结构、低摩擦传动和柔软的缓冲特性使其能够实现高分辨率的力控制,这对于需要精确力反馈的人工智能驱动操作任务至关重要。通过刚柔混合动力学建模,实现了最小控制延迟和高精度轨迹跟踪。此外,传动机构和制造工艺经过精心优化,以最大限度地减少表面磨损并确保长期机械耐久性,满足实际使用寿命的要求。
2.全身遥操作
对于全身遥操作,我们引入了一种直观且经济高效的系统,由 VR 头显和手持式操纵杆组成。操纵杆捕捉到的手部姿势被映射到机器人末端执行器的位置和方向,随后通过全身控制(WBC)转换为关节指令。该系统支持两种控制模式:(1) 第一人称视角模式,针对精确复杂的操控任务以及远程遥控操作进行了优化;(2) 第三人称视角模式,专为大范围全身运动而设计,传输延迟极低,非常适合高动态任务以及近场数据采集。
3.全身移动操作模型DuoCore-WB
为了学习广泛的全身操作任务,我们推出了 DuoCore-WB,这是一种简单而有效的模仿学习算法,旨在模拟全身动作。在这里我们暂且忽略模型架构的多样性与复杂性,而是强调三个核心设计选择:(1)基于 RGB 的视觉感知,能够使用预先训练的视觉编码器进行视觉泛化,并通过与大规模 VLA 训练的兼容性促进可扩展性; (2) 在执行器末端 (EE) 笛卡尔空间中使用 SO(3) 作为方向表示进行全身策略控制,表示为每个末端执行器在自身坐标系下的运动增量。与直接在关节空间中学习相比,在末端执行器笛卡尔空间中进行学习可以有效地减轻误差积累,这一问题在学习全身策略时尤为明显。此外,基于自身坐标系下的增量动作表征强调了视觉观察与动作目标之间的一致性,同时对复杂协调的全身运动中经常发生的较大视点转变具有更强的鲁棒性;(3) 实时轨迹生成模块 (RTG),利用二次规划 (QP) 优化将预测的动作块细化为平滑、准确和连续的执行轨迹。该模块作为后处理器,具有良好的鲁棒性与实时性,并可与上游策略解耦,适用于多种动作生成方法。

如图 1 所示,我们在六个具有代表性的真实世界全身任务上对 Astribot Suite 进行评估。每个任务的DuoCore-WB 策略都基于通过我们的遥操系统收集的数据进行训练。送饮料任务测试执行长时序、移动操作任务以及对铰接物体(门把手)进行灵巧操作的能力。 收纳猫粮任务测试在受限空间(例如低柜)内的双手协调操作以及处理高负载(约 2公斤)物体时的动态稳定性。扔垃圾任务测试多阶段任务的双手协调性和对铰接物体(垃圾桶盖)的精确操作。整理鞋子任务侧重于低高度空间中的全身协调性和双手同步操作的能力。扔玩具任务展示了学习高动态运动和从地板精确抓取物体的能力。整理玩具任务则全面评估了双手协调、且连续准确操纵多个物体的能力。
经过训练的的 DuoCore-WB 策略在上述任务中表现出色,平均成功率达到 80%,最高成功率达到 100%。
我们认为,Astribot Suite 集成的机器人实体、遥操作系统和学习框架,代表着我们在推动机器人走近人类生活、执行日常全身操做迈出了重要一步。
输入输出设计
DuoCore-WB仅使用 RGB 图像作为输入,保证了与大规模视觉-语言-动作(VLA)预训练模型的无缝衔接。视觉输入来自三个同步摄像头:头部相机、左腕相机和右腕相机。机器人状态信息包括底盘运动、躯干姿态、双臂末端执行器位姿及头部姿态,这些状态信息与视觉输入一同作为模型的输入。
DuoCore-WB 在末端执行器 (EE) 笛卡尔空间中(而非高维关节空间)对全身动作进行生成,有效避免了关节误差累积带来的末端精度下降。此外,该模型学习了各末端执行器在自身坐标系下的动作增量,增强了视觉观察与动作目标之间的一致性,并显著提升了在全身操作中应对大视角变化的鲁棒性。
模型架构
DuoCore-WB是一种融合了 Transformer架构与扩散模型(Diffusion Models)的模仿学习框架,目标是学习复杂的全身移动操作策略。

在多模态特征编码阶段,模型接收三路同步图像,并统一送入经过预训练的 Vision Transformer(ViT) 进行视觉特征编码。为了增强模型对摄像头视角与空间信息的感知能力,我们为每幅图像中的所有 patch tokens 添加了一组共享的可学习位置编码(Learnable Positional Embeddings),用于指示该 token 所在的空间位置以及图像来源(即摄像头模态),从而在特征层明确区分三视角之间的差异。同时,机器人的状态信息被编码为一个低维状态向量。该向量通过线性映射投影至与视觉特征相同的嵌入空间,并添加一组可学习的模态位置嵌入(modality-specific positional embedding),用于显式表征其模态来源,从而实现状态信息与视觉信息在统一特征空间中的融合。
在动作生成阶段,我们采用条件扩散模型(Conditional Denoising Diffusion Probabilistic Model, C-DDPM),以建模从感知特征到高维动作序列的条件生成映射。该模型能够在感知条件(如图像与状态编码)给定的前提下,从随机噪声中逐步生成与人类示范相一致的全身动作轨迹。具体而言,我们首先将原始的动作序列(包括底盘、躯干姿态、双臂末端执行器和头部的动作指令)加入高斯噪声,得到不同时间步下的带噪动作表示,该过程定义为前向扩散过程:

其中x为真实动作序列,
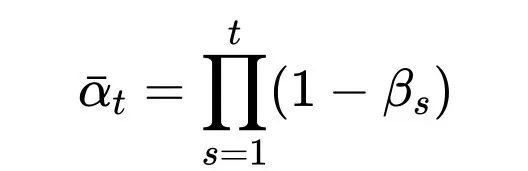
为累积的噪声衰减因子,

为扩散步数,
ϵ 为标准正态分布噪声。扩散模型通过最小化噪声预测误差,学习一个参数化的去噪网络

目标函数为:
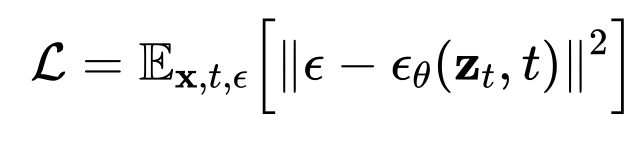
该模型训练完成后,可根据带噪输入

和时间步t,预测噪声并逐步还原出干净数据x,实现高质量的样本生成。
实时轨迹生成模块 (RTG)
当前的机器人策略模型通常基于当前观测生成一系列未来动作,这组连续动作被称为一个“动作片段”(action chunk)。尽管这些动作片段具有关联的时间索引,但其在动态执行过程中面临多项挑战:
(1)片段内抖动:同一动作片段中连续动作之间存在不一致性;
(2)片段间断裂:不同动作片段之间的突变转折会导致轨迹不连续,尤其在全身操控场景中,这种问题更为显著,因为观测在时间维度上可能剧烈变化。动作流中的突变不仅会降低执行稳定性,还可能对硬件本体造成潜在损害。
我们提出的方法是一个轻量级的后处理模块,可以与任何视觉运动学习算法无缝集成。在融合多个时间步的动作推理时采用Quadratic Programming (QP) 优化来生成平滑且动态可行的轨迹,全面解决续性、平滑过渡和物理约束问题。下图为某VLA模型用不同的动作片段处理方式产生的轨迹在不同时刻的速度。

部署细节
部署期间,推理在配备 NVIDIA RTX 4090 GPU 的工作站上执行,有效延迟为 0.05 秒。策略推理以 20 Hz 运行,推理结果以相同频率同步输入 RTG。然后,RTG 以 250 Hz 的频率向控制器发出动作命令。因此,每 0.05 秒生成一个新的策略动作序列并更新 RTG 状态,而控制器的命令每 0.004 秒刷新一次。
实验
我们在六个具有代表性的任务上对 DuoCore-WB 进行评估,任务示意如图 1 所示:
1.递送饮品(Deliver a drink):评估系统执行长时序任务的能力,涉及移动操作和对带关节物体(如门把手)的灵巧交互。

2.储存猫粮(Store cat food):测试机器人在狭小空间(如低矮橱柜)内的精细操作能力,包括在空间受限条件下的双臂协调动作,以及搬运约 2 公斤重载荷时的动态稳定性。

3.丢弃垃圾(Throw away trash):考察机器人多阶段的双臂协同能力和对带关节部件(如垃圾桶盖)的精准操作。

4.整理鞋子(Organize shoes):强调低高度全身协调以及同步的双臂操作能力。

5.投掷玩具(Throw a toy):展示机器人执行动态全身动作和从地面精准抓取小物体的能力。

6.拾取玩具(Pick up toys):作为综合性基准,测试机器人通过双臂协调,实现持续且精确的多物体操作。

如表2所示,DuoCore-WB在全身移动操作任务上展现了较好的成功率

表 2 | 任务成功率。对于每个任务,我们进行 15-30 次评估,并在第一个子任务失败时终止该回合。我们报告每个子任务的成功率以及整体端到端任务的成功率。“SR”代表成功率。标有 Ó 图标的子任务表示移动设备操作。
此外我们重点评估了动作空间、动作表示方式与参考坐标系设计对策略性能的影响,具体包括以下四项核心发现:
1.末端执行器(EE)空间动作表示减少误差积累、提升任务性能。相比于关节空间动作表示,EE 笛卡尔空间的策略在执行复杂全身协调任务时具有更高精度与更强泛化能力。在双臂桌面清理任务中,关节空间策略成功率为 90%(18/20),EE 空间策略提升至 95%(19/20);在更具挑战性的地面物体分类任务中,关节空间策略仅 25%(5/20),而 EE 空间策略显著提升至 90%(18/20)。EE 表示通过直接预测末端执行器位姿,有效避免了由关节层级误差传递带来的精度损失,表现出更强的鲁棒性与部署稳定性。
2.增量动作表示提高轨迹平滑度与执行稳定性。 如图所示,相较于绝对动作表示,基于增量动作表示训练的策略能有效减少动作跳变与轨迹振荡,尤其在高频控制或较大动作幅度场景下更显著。在桌面清理与地面分类任务中,绝对动作策略的平均步进变化为 0.0058,动作片段切换处变化高达 0.0196;而增量动作策略分别降低至 0.0034 与 0.0032。结果表明,增量表示显著提升了动作连续性与时序一致性,有助于提升执行稳定性与安全性。

3.末端执行器自我坐标系增强视觉-动作对齐与泛化能力。 我们将增量动作表示为末端执行器的位姿变换矩阵,并系统比较了两种参考坐标系:机器人基座坐标系与末端执行器自我坐标系。在多个桌面任务中进行评估,包括腕部相机主导的精细操作、头部相机引导的大范围移动,以及需全身协调的地面拾取任务。所有实验均在少样本条件下(每任务仅40条示范)进行,如表4显示,基于末端执行器自我坐标系的增量动作表示平均表现更优,具有以下优势:
精细操作任务中(腕部相机主导):由于动作目标直接定义在观察视角内,末端执行器坐标系可实现视觉观测与动作目标的紧密对齐,提升动作精度并加快模型收敛。
大范围移动任务中(头部相机主导):头部相机与机器人基座之间的相对位置更稳定,使用基座坐标系定义动作有助于建立一致的图像特征-控制映射,取得更好性能。
全身协调任务中(视角变化剧烈):头部相机视角变化导致基座参考系下的动作表示不稳定;使用末端执行器自我坐标系可提供更稳定、视角不变的目标表达,提升复杂任务表现。
泛化能力:在存在分布偏移(如新物体位置)时,末端执行器坐标系下的动作表示具备更强的空间推理能力与部署鲁棒性,尤其在精细操作中展现更佳泛化效果。

4.基于末端自我坐标系的相对轨迹表示提升结构一致性与建模效率。实验比较了三种轨迹表示方式:世界坐标下的绝对轨迹、机器人基座坐标系下的相对轨迹,以及末端执行器自我坐标系下的相对轨迹。如图所示,绝对轨迹受初始状态与环境布局变化影响较大,结构一致性弱;基座相对轨迹可滤除部分全局变化,但参考系固定,仍受机器人移动影响;而 EE 自我坐标系下的相对轨迹则能动态更新参考系,使动作表达在结构上更紧凑、信息密度更高,且自然对齐机器人控制逻辑,在多任务学习中取得最佳表现。


往期文章
全球首篇自动驾驶VLA模型综述重磅发布!麦吉尔&清华&小米团队解析VLA自驾模型的前世今生
字节跳动Seed实验室发布ByteDexter灵巧手:解锁人类级灵巧操作
具身专栏(三)| 具身智能中VLA、VLN、VA中常见训练(training)方法
具身专栏(二)| 具身智能中VLA、VLN分类与发展线梳理
具身专栏(一)| VLA、VA、VLN概述
π0.5:突破视觉语言模型边界,首个实现开放世界泛化的VLA诞生!
斯坦福&英伟达最新论文:CoT-VLA模型凭"视觉思维链"实现复杂任务精准操控
RoboTwin2.0全面开源!多模态大模型驱动的双臂操作Benchmark ,支持代码生成!
开源!Maniskill仿真器上LeRobot的sim2real的RL训练代码开源(附教程)
迈向机器人领域ImageNet,大牛PieterAbbeel领衔北大、通院、斯坦福发布RoboVerse大一统仿真平台
CVPR 北大、清华最新突破:机器人操作新范式,3.3万次仿真模拟构建最大灵巧手数据集
人形机器人四级分类:你的人形机器人到Level 4了吗?(附L1-L4技术全景图)建议收藏!
斯坦福最新论文:使用人类动作的视频数据,摆脱对机器人硬件的需求
爆发在即!养老机器人如何守护2.2亿老人?产业链+政策一览,建议收藏!











