点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
0. 论文信息
标题:H3R: Hybrid Multi-view Correspondence for Generalizable 3D Reconstruction
作者:Heng Jia, Linchao Zhu, Na Zhao
机构:ReLER Lab, CCAI, Zhejiang University 、Singapore University of Technology and Design、The State Key Lab of Brain-Machine Intelligence, Zhejiang University
原文链接:https://arxiv.org/abs/2508.03118
代码链接:https://github.com/JiaHeng-DLUT/H3R
1. 导读
尽管最近在前馈3D高斯平铺方面取得了进展,但通用的3D重建仍然具有挑战性,特别是在多视图对应建模中。现有方法面临一个根本性的权衡:显式方法在几何精度上表现良好,但在模糊区域处理上存在困难;而隐式方法虽然提供了鲁棒性,但收敛速度较慢。我们提出了H3R框架,该框架通过将体积潜在融合与基于注意力的特征聚合相结合来解决这一限制。我们的框架由两个互补部分组成:一个高效的潜在体积,它通过极线约束强制几何一致性;以及一个相机感知的Transformer,它利用普吕克坐标进行自适应对应关系细化。通过整合这两种范式,我们的方法在增强泛化能力的同时实现了快速收敛。我们的方法比现有方法更快。此外,我们展示了空间对齐的基础模型(例如SD-VAE)在性能上显著优于语义对齐的模型(例如DINOv2),解决了语义表示与空间重建需求之间的不匹配问题。我们的方法支持可变数量和高分辨率的输入视图,同时证明了其在跨数据集上的鲁棒泛化能力。广泛的实验表明,我们的方法在多个基准测试中达到了最先进的性能,分别在RealEstate10K、ACID和DTU数据集上实现了0.59 dB、1.06 dB和0.22 dB的显著PSNR提升。
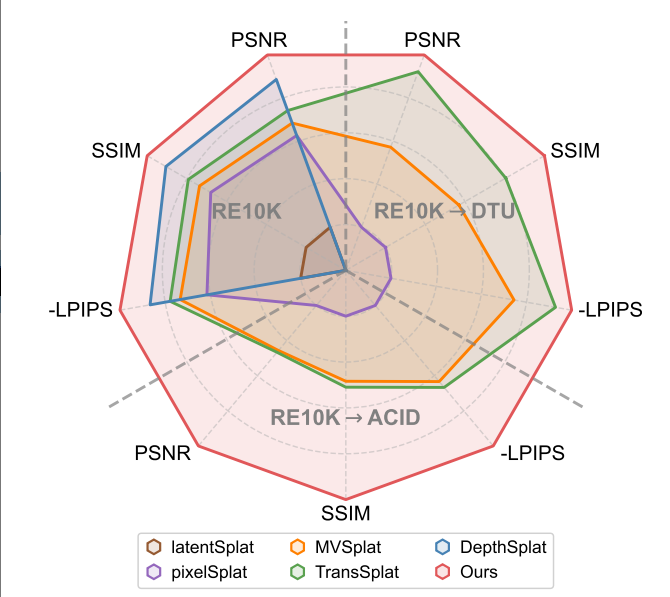
2. 效果展示
与最先进的通用3D重建方法的比较。我们的方法在三个数据集上都 consistently表现出优于现有方法的表现展示了卓越的重建性能和跨数据集泛化能力。
ACID和DTU数据集上的跨场景泛化结果。

3. 引言
可泛化的三维重建因其无需逐场景优化的特性而备受关注。传统神经辐射场(NeRF)需要昂贵的场景特异性训练,限制了其实用性。近期研究进展转向前向重建方法,这类方法利用3D高斯溅射(3DGS)等高效表示实现快速重建。3DGS通过3D高斯基元集合表示场景,规避了NeRF中计算密集的光线行进过程,并支持基于光栅化的快速渲染。pixelSplat和MVSplat通过单次前向传递预测像素对齐的高斯基元,在真实场景基准测试中实现高质量重建。与此同时,基于Transformer的方法如eFreeSplat和TranSplat通过注意力机制改善跨视角对应关系,增强稀疏输入下的深度估计能力。尽管重建质量取得显著进步,但在多样化场景中实现鲁棒的可泛化三维重建仍面临重大挑战。
首要挑战在于显式与隐式对应建模的权衡。显式方法通过代价体积强制几何约束,在几何精度上表现优异,但当光度一致性被破坏时(如遮挡、无纹理区域、镜面高光或重复模式)性能下降。相反,隐式方法采用注意力机制学习鲁棒对应关系以处理模糊场景,但存在收敛速度慢的问题。显式方法提供几何精度但缺乏鲁棒性,隐式方法以效率为代价换取适应性。因此,原则性整合这两种范式对于构建鲁棒高效的多视角对应模型至关重要。推荐课程:为什么说colmap仍然是三维重建的核心?
我们提出H3R框架,该混合网络整合显式与隐式对应建模。其包含两个互补组件:通过极线约束强制几何一致性的体积潜在融合模块,以及跨视角执行引导对应聚合的摄像头感知Transformer。体积模块将多视角特征投影到离散化潜在体积中,显式捕获几何对应关系。Transformer利用普吕克坐标执行几何感知注意力,隐式建模跨视角对应关系。这种混合设计在提升重建质量的同时显著改善训练效率。
除架构设计外,我们发现视觉表示的选择对对应质量起决定性作用,由此引出第二个关键挑战:主流视觉表示的语义特性与三维重建所需的空间保真度存在不匹配。近期方法通常依赖DINO等语义对齐模型,这类模型通过全局图像级监督强调高级语义理解,但以牺牲像素级空间保真度为代价,而空间保真度对精确三维重建至关重要。相比之下,空间对齐模型(如MAE和SDVAE)通过像素级重建目标保留细粒度局部特征和几何结构,天然更适合需要精确跨视角对应的三维重建任务。
通过多样化视觉基础模型的系统评估(图7),我们证明空间对齐模型持续优于语义对齐模型。值得注意的是,SD-VAE在参数效率上表现优异,而广泛采用的DINOv2性能明显不足。这些结果为可泛化三维重建提供了有力证据:空间对齐模型更具优势。

除技术考量外,实际部署面临现实输入多样性的挑战。现有方法假设固定视角和均匀质量的受控环境,难以应对真实世界的复杂场景。为此,我们开发两种专用扩展模型:H3R-α通过自适应潜在融合处理多上下文视角,随视角增加持续改善重建质量;H3R-β专注于高分辨率重建,在有限输入视角下输出高保真结果。
4. 主要贡献
核心贡献总结如下:
• 混合多视角对应建模:提出H3R框架,通过整合显式体积融合与隐式摄像头感知Transformer,解决显式与隐式对应建模的权衡问题。H3R在挑战性场景中实现优越重建质量,且收敛速度比现有方法快2倍。
• 空间对齐视觉表示:系统证明空间对齐视觉表示在高保真三维重建中显著优于传统语义对齐特征。SD-VAE凭借优异参数效率达最佳性能,而DINOv2尽管应用广泛却表现不佳。
• 综合性能提升:解决可泛化三维重建的三大核心挑战,在RealEstate10K、ACID和DTU数据集上分别实现0.59dB、1.06dB和0.22dB的PSNR提升,展现强泛化性、2倍加速收敛及鲁棒的现实适应性。
5. 方法
我们提出H3R框架(图2),该混合多视角对应模型用于可泛化三维重建。H3R结合体积潜在融合与摄像头感知Transformer,实现优越渲染质量与加速收敛。为应对实际三维重建场景的输入多样性,我们开发两种模型扩展:H3R-α处理多上下文视角并整合目标视角位姿以确保全面场景覆盖,H3R-β专注于高分辨率重建并在有限输入下输出高质量结果。

6. 实验结果
两视角新视图合成。我们在RealEstate10K和ACID两个挑战性数据集上评估方法(表1)。在RealEstate10K中,H3R显著优于TranSplat(+0.91 PSNR,+0.016 SSIM,-0.011 LPIPS)。在ACID中,我们的方法达到28.29 PSNR和0.846 SSIM,超越pixelSplat和MVSplat。定量结果结合图3的定性对比,证明我们的方法能从稀疏输入生成高保真新视图。
我们的方法通过两种专用变体展现通用性,分别针对不同输入条件设计。H3R-α利用目标摄像头位姿生成具有全面视角覆盖的高斯基元,相比基础H3R模型在RealEstate10K和ACID上分别提升+0.19和+0.15 PSNR。H3R-β利用高分辨率输入捕捉细节,实现更优渲染质量(+0.43和+0.42 PSNR)。这些结果证明我们的方法在不同输入条件下的通用性,推动可泛化新视图合成领域的发展并彰显现实部署潜力。


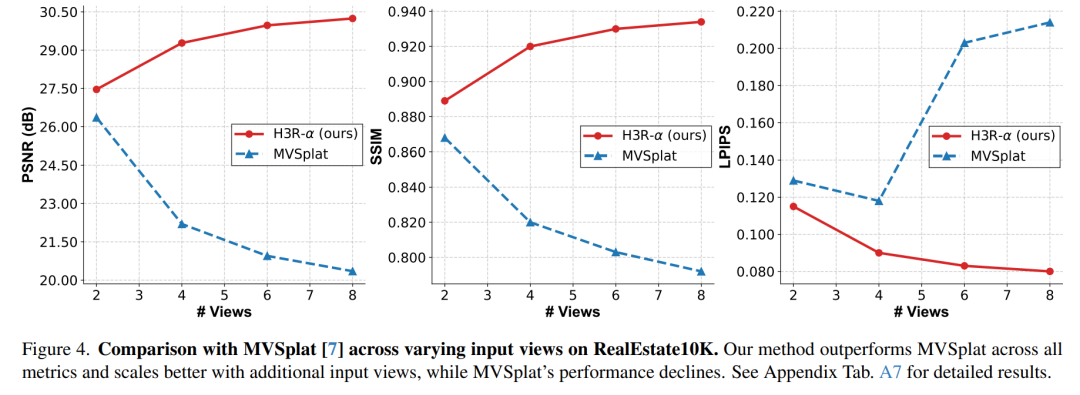
多视角新视图合成。图4比较RealEstate10K上H3R-α与MVSplat随输入视角增加的性能趋势。H3R-α随视角增加持续改善,从2到8视角时PSNR提升+2.78,LPIPS降低-0.035。相反,MVSplat在感知质量上出现性能下降(-0.085 LPIPS)。当达到8视角时,性能差距扩大至+9.89 PSNR和-0.134 LPIPS。所有指标的单调提升证明H3R-α对实际多视角重建场景具有优越适应性。
7. 总结 & 未来工作
我们提出H3R框架,通过解决三大根本挑战推进可泛化三维重建:多视角对应建模的权衡、视觉表示选择与现实输入多样性。H3R协同整合显式约束的几何精度与隐式注意力聚合的鲁棒性,通过集成免代价体积的潜在空间与摄像头感知Transformer,实现几何精度与鲁棒对应的统一,收敛速度比现有方法快2倍。此外,我们发现特征表示与重建保真度存在关键不匹配,系统分析证明空间对齐基础模型(如SD-VAE)显著优于DINOv2等语义对齐模型。实验结果验证方法有效性,在多个基准测试中展现持续改进、强跨数据集泛化性,同时支持可变数量或高分辨率输入视角。H3R不仅提供优越性能,还为设计更高效鲁棒的重建系统奠定基础原则。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
3D视觉1V1论文辅导来啦!

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001