
本文由 Intern-S1、Qwen3 等 AI 生成, 由机智流编辑部校对
近年来,大语言模型(LLMs)在推理任务中的表现令人叹为观止,特别是在数学竞赛和复杂逻辑推理等高难度场景中。然而,传统的推理增强方法,如自一致性(self-consistency[1])通过多数投票聚合多个推理路径,虽然提升了准确率,但往往伴随着高昂的计算成本和效率瓶颈。如何在保持高精度的同时大幅降低计算开销,成为了AI领域亟待解决的难题。
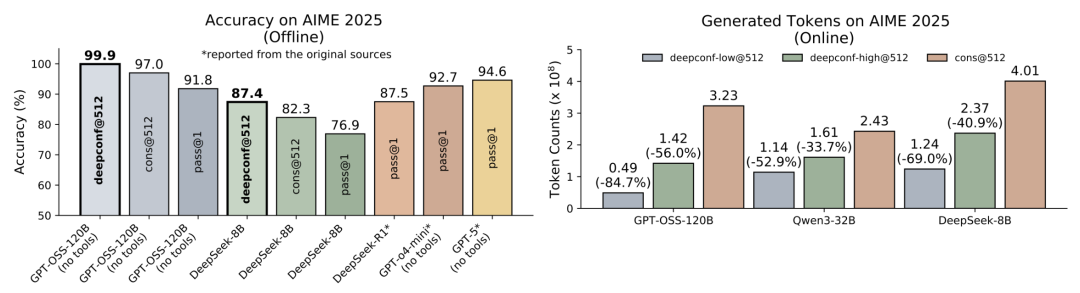
Meta AI联合加州大学圣地亚哥分校(UCSD)的研究团队,推出了一项名为“Deep Think with Confidence”(简称DeepConf)的创新方法,以“自信度”(Confidence)为核心,成功在推理性能与计算效率之间取得了惊艳的平衡。这项研究不仅在AIME 2025等高难度数学竞赛数据集上实现了高达99.9%的准确率(而在不使用工具但开启思考模式的情况下,GPT-5 的表现仅为 94.6%),还将生成token量削减了高达84.7% ,为个人开发者和中小企业的大模型私有化部署提供了全新的可能性。
本文将从DeepConf的创新点、实验方法以及实验结果三个方面,带您深入了解这一突破性工作的魅力所在。
论文链接:https://huggingface.co/papers/2508.15260
DeepConf的创新:以“自信”重塑推理范式
DeepConf的核心创新在于引入了基于模型内部“自信度”信号的动态推理路径筛选机制,打破了传统自一致性方法中所有推理路径平等对待的局限。
传统方法通过生成多个推理路径并以多数投票的方式选择最终答案,虽然有效,但存在两个显著问题:一是随着推理路径数量增加,准确率提升趋于饱和,甚至可能下降;二是生成大量推理路径导致计算成本线性增长,限制了其在资源受限环境中的应用。例如,在AIME 2025数据集上,传统方法从68%的单路径准确率提升到82%,需要额外生成511条推理路径,消耗高达1亿个token。
DeepConf通过利用模型在推理过程中产生的token分布统计信息,巧妙解决了这些问题。研究团队提出了一系列基于局部自信度(local confidence)的指标,包括组自信度(Group Confidence)、最低10%组自信度(Bottom 10% Group Confidence)、最低组自信度(Lowest Group Confidence)和尾部自信度(Tail Confidence)。这些指标通过分析模型在推理路径中每个token的预测概率分布,捕捉推理过程中的关键质量信号。例如,低熵表示模型对当前预测高度自信,而高熵则反映模型的不确定性。通过对这些信号的局部化分析,DeepConf能够识别出推理路径中的低质量片段,并在生成过程中或生成后动态剔除这些路径,从而大幅减少不必要的计算开销。
以下是几种主要自信度指标的简要定义及其数学公式:
1. Token Confidence(单token自信度):衡量模型在某一位置对top-k个候选token的预测确定性,计算为top-k个token的对数概率的负平均值。
其中, 是第 i 个位置上第 j 个候选token的概率,k 是考虑的top-k候选数。高 值表示模型预测更自信。
2. Average Trace Confidence(平均路径自信度):通过对整个推理路径中所有token的自信度取平均值,评估整条推理路径的总体质量。较高的平均值表明推理过程整体更可靠、更一致。
其中,N 是推理路径中的 token 总数, 为第 i 个 token 的自信度。该指标反映全局推理稳定性,适用于离线评估模型推理质量。
3. Group Confidence(组自信度):在推理路径中采用滑动窗口(窗口大小为 ,如 1024 或 2048)对局部 token 的自信度进行平均,用于捕捉推理过程中不同阶段的局部质量表现。
其中, 表示第 i 个滑动窗口包含的 n 个连续 token, 为其长度(通常为 n)。该指标有助于识别局部推理波动或潜在错误区域。
4. Bottom 10% Group Confidence(最低10%组自信度):聚焦于推理路径中自信度最低的那部分片段,计算这些低置信度组的平均自信度,用以检测可能引发错误的关键薄弱环节。
其中, 是所有滑动窗口中自信度排名最低的前 10% 的组集合。该指标对识别推理路径中的“危险区域”具有重要意义,尤其适用于质量监控与纠错机制设计。
5. Lowest Group Confidence(最低组自信度):选取推理路径中所有滑动窗口中自信度最低的那一组作为衡量标准,常用于在线推理场景中实现动态终止策略,防止低质量路径继续扩展。
其中,G 为路径中所有滑动窗口的集合。该指标提供了一个严格的“安全阈值”,可用于实时决策,例如中断不可靠推理流。
6. Tail Confidence(尾部自信度):专门评估推理路径最后一段(如最后 2048 个 token)的平均自信度,特别适用于数学推理等任务中强调最终答案正确性的场景。
其中, 表示路径末尾固定数量的 token 集合(如最后 2048 个)。高尾部自信度意味着模型在得出结论时表现出较强确定性,是判断最终输出可信度的重要依据。
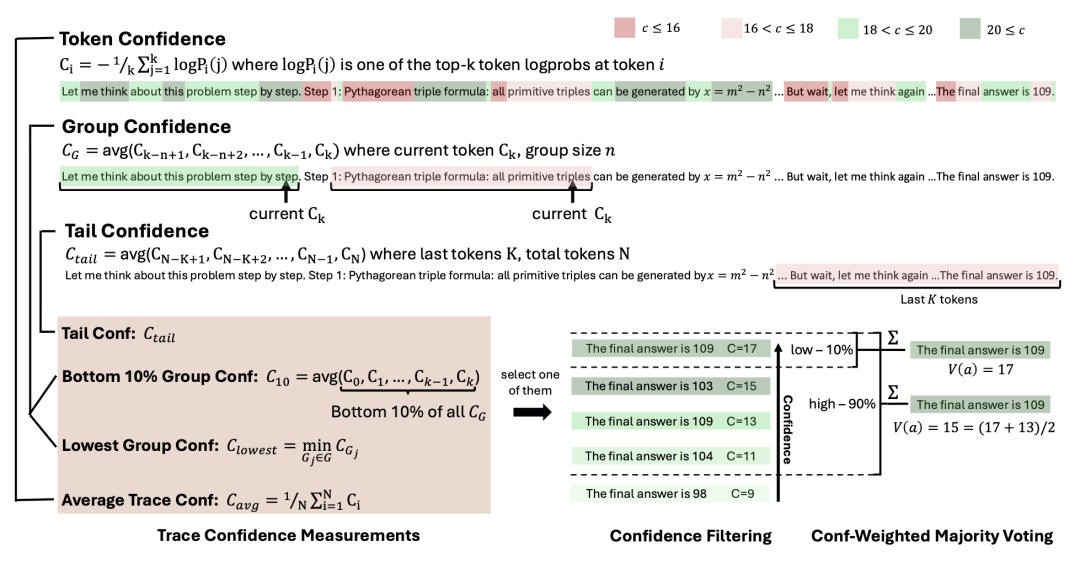 图1:DeepConf 不同自信度测量方法的示意图。
图1:DeepConf 不同自信度测量方法的示意图。
这些自信度指标通过分析token预测的概率分布(熵或对数概率),从全局到局部、从整体到尾部,提供多维度的推理路径质量评估。局部指标(如最低组自信度和尾部自信度)相比全局平均自信度更能捕捉推理中的关键错误,显著提升了DeepConf的性能和效率。
DeepConf支持两种工作模式:离线模式和在线模式。在离线模式下,DeepConf在生成所有推理路径后,利用自信度指标进行筛选和加权投票,优先选择高质量路径以提升准确率。在在线模式下,DeepConf通过实时监控推理路径的自信度,在生成过程中动态终止低质量路径,从而进一步降低token生成量。这种灵活的设计使得DeepConf无需额外模型训练或超参数调优即可无缝集成到现有服务框架中,为实际应用提供了极高的实用性。

图2:DeepConf在AIME 2025数据集上的表现(上图)及并行推理示意图(下图)。图中展示了DeepConf如何通过自信度筛选实现高精度与低计算成本的平衡。
实验方法:严谨设计,多维度验证
为了全面验证DeepConf的性能,研究团队在多个高难度推理任务和最新开源模型上进行了广泛的实验。实验涉及的模型包括DeepSeek-8B、Qwen3-8B、Qwen3-32B、GPT-OSS-20B和GPT-OSS-120B,覆盖了从8亿到1200亿参数的多种规模。数据集则包括AIME 2024、AIME 2025、BRUMO25、HMMT25以及GPQA-Diamond,这些数据集以高难度数学竞赛问题和研究生级别的STEM推理任务为主,广泛用于评估顶级推理模型的性能。
实验设计上,研究团队采用了统一的采样框架,为每个问题预生成4096条推理路径,作为离线和在线实验的基础池。离线实验从该池中重采样512条路径(或其他指定数量),应用不同的自信度指标进行加权投票和筛选。在线实验则通过初始16条路径的预热(warmup)阶段确定自信度阈值,随后在生成过程中动态终止低质量路径。
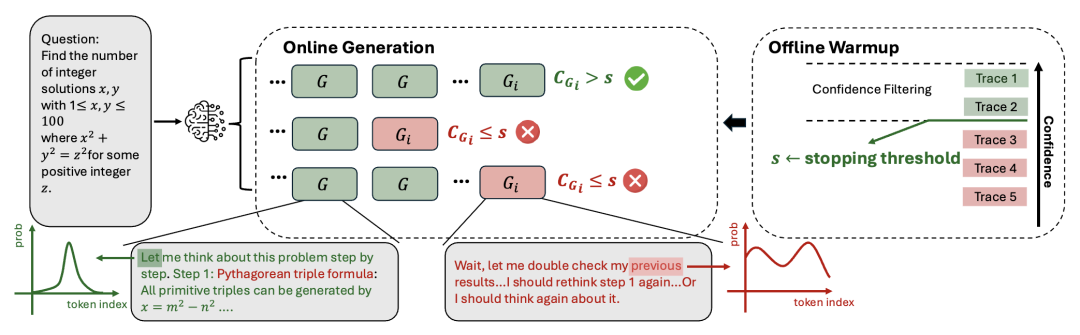 图3:DeepConf 的在线工作模式示意图。图中展示了如何通过初始路径的预热阶段确定自信度阈值,如何通过实时自信度监控动态终止低质量推理路径,从而优化计算效率。
图3:DeepConf 的在线工作模式示意图。图中展示了如何通过初始路径的预热阶段确定自信度阈值,如何通过实时自信度监控动态终止低质量推理路径,从而优化计算效率。
实验报告了四种主要方法:单路径准确率(Pass@1)、标准多数投票(Cons@K)、基于自信度的加权投票(Measure@K)以及结合自信度筛选的加权投票(Measure+top-η%@K)。其中,η表示保留的高自信度路径比例,通常取10%或90%。
在线实验中,DeepConf-low(保留10%高自信度路径)和DeepConf-high(保留90%高自信度路径)是两种主要配置,通过最低组自信度指标实现动态终止。实验还设置了共识阈值(τ=0.95),当多数答案的权重达到该阈值时停止生成,以进一步优化效率。所有结果均通过64次独立运行取平均值,确保统计稳定性。

图4:不同自信度指标在HMMT25数据集上的分布对比。图中显示了正确与错误推理路径的自信度分布,验证了局部自信度指标(如最低10%组自信度和尾部自信度)在区分推理质量上的优越性。
实验结果:精度与效率的双赢
DeepConf的实验结果充分展示了其在推理性能和计算效率上的双重优势。
在离线模式下,DeepConf在AIME 2025数据集上使用GPT-OSS-120B模型取得了惊人的99.9%准确率,远超标准多数投票的97.0%和单路径的91.8%。在其他数据集和模型上,DeepConf也展现出显著的性能提升。例如,在DeepSeek-8B模型上,AIME25的准确率从82.3%提升至87.4%,HMMT25从69.6%提升至79.0%。尾部自信度和最低10%组自信度等局部指标在多数场景下优于全局平均自信度,表明局部信号能够更精准地捕捉推理路径中的关键错误。
在线模式下,DeepConf的效率优势尤为突出。以DeepConf-low为例,在AIME 2025数据集上,GPT-OSS-120B模型的token生成量减少了84.7%,同时准确率提升至97.9%。在DeepSeek-8B模型上,AIME24数据集的token量减少了77.9%,准确率从86.7%提升至92.5%。即使在更保守的DeepConf-high配置下,token量也能减少18.59%至59%,且准确率基本保持不变或略有提升。图6和图7进一步揭示了DeepConf在不同任务和模型上的token削减模式,显示其在维持高精度的同时显著降低了计算成本。

图5:基于GPT-OSS-120B模型的生成token量对比。图中展示了DeepConf在不同任务上实现的显著token削减,最高达84.7%。
未来展望:DeepConf的潜力与挑战
DeepConf的成功不仅在于其当前的性能,还在于其为未来研究开辟了新的方向。研究团队指出,DeepConf可以进一步与强化学习结合,通过自信度引导的早期终止优化策略探索,提高训练过程中的样本效率。此外,针对模型在错误推理路径上表现出高自信度的情况,未来的工作可以探索更稳健的自信度校准技术和不确定性量化方法,以进一步提升推理的鲁棒性。
尽管DeepConf在实验中表现出色,但其局限性也不容忽视。在某些场景下,模型可能对错误的推理路径表现出过高自信,导致筛选失误。研究团队在附录中详细分析了这些情况,并提出了潜在的改进方向,如更精细的自信度指标设计和动态阈值调整。
结语:DeepConf开启高效推理新篇章
DeepConf通过引入基于局部自信度的动态筛选机制,为大型语言模型的推理任务带来了革命性的突破。其在AIME 2025等高难度数据集上的99.9%准确率和高达84.7%的token削减,充分证明了其在性能与效率上的双重优势。无论是学术研究还是工业应用,DeepConf都展现了测试时压缩(test-time compression)的巨大潜力,为高效、可扩展的AI推理提供了一条崭新的道路。
这项由Meta AI和UCSD联合完成的研究,不仅彰显了学术与工业合作的创新力量,也为AI推理领域的未来发展指明了方向。期待DeepConf在更多场景中的应用与优化,为智能系统的广泛部署注入新的活力。
项目主页:https://jiaweizzhao.github.io/deepconf
论文链接:https://huggingface.co/papers/2508.15260
vLLM 示例:https://jiaweizzhao.github.io/deepconf/static/htmls/code_example.html
self-consistency: http://arxiv.org/abs/2203.11171
-- 完 --
机智流推荐阅读:
2. 开源多模态大模型新突破,书生·万象3.5发布,通用能力、推理能力与部署效率全面升级
3. 工具调用推理只是花瓶,还是真的让大模型更聪明?腾讯清华团队揭秘工具集成推理的奥秘
4. CVPR2025 | g3D-LF让机器人“看懂”3D空间、“听懂”复杂语言,无需LLM,但导航、问答一气呵成
关注机智流并加入 AI 技术交流群,不仅能和来自大厂名校的 AI 开发者、爱好者一起进行技术交流,同时还有HuggingFace每日精选论文与顶会论文解读、Talk分享、通俗易懂的Agent知识与项目、前沿AI科技资讯、大模型实战教学活动等。
cc | 大模型技术交流群 hf | HuggingFace 高赞论文分享群 具身 | 具身智能交流群 硬件 | AI 硬件交流群 智能体 | Agent 技术交流群










