点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:我爱计算机视觉,作者:CV君
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

本文分享一篇被计算机视觉顶级会议 ICCV 2025 评为 Highlight 的重磅论文——《CoopTrack: Exploring End-to-End Learning for Efficient Cooperative Sequential Perception》。该研究由清华大学、香港理工大学、香港大学及百度公司的学者共同完成,提出了一种名为 CoopTrack 的端到端协同3D多目标跟踪框架。它从根本上改变了现有方法,通过可学习的实例关联机制,在大幅提升跟踪精度的同时,有效控制了通信成本,在V2X-Seq数据集上实现了 39.0% mAP 和 32.8% AMOTA 的当前最佳性能(SOTA)。

论文标题:CoopTrack: Exploring End-to-End Learning for Efficient Cooperative Sequential Perception 作者:Jiaru Zhong, Jiahao Wang, Jiahui Xu, Xiaofan Li, Zaiqing Nie, Haibao Yu 机构:清华大学;香港理工大学;香港大学;百度公司 论文地址: https://arxiv.org/pdf/2507.19239v1 项目地址: https://github.com/zhongjiaru/CoopTrack 录用信息:Accepted by ICCV 2025 (Highlight)
01
研究背景与意义
单车智能是当前自动驾驶的主流路线,但它存在固有的“视界”局限性,例如在十字路口、恶劣天气或被大型车辆遮挡时,感知能力会严重下降。协同感知(Cooperative Perception)技术应运而生,它通过车与车(V2V)、车与路侧设施(V2I)之间的信息共享,为自动驾驶系统打开“上帝视角”,有效克服单车感知的不足。
然而,以往的协同感知研究大多集中在单帧感知任务上,如协同3D目标检测。对于更复杂、在时序上连续的协同3D多目标跟踪(Cooperative 3D Multi-Object Tracking)任务,探索尚不充分。现有的跟踪方法通常遵循“先协同检测,后进行跟踪”的非端到端模式,这种模式流程繁琐,且检测和跟踪任务分离会导致次优解。虽然有少数端到端的方法被提出,但它们依赖于基于规则的实例关联,鲁棒性和适应性不足。

(a) 大多数研究都集中在单帧感知任务上。 (b) 非端到端解决方案采用协作检测跟踪方法。 (c) 端到端协作跟踪方法实现了联合检测和跟踪: (c.1)之前的方法[71]应用了基于规则的查询关联。 (c.2)CoopTrack引入一种全新的“解码后融合”(fusion-after-decoding)的端到端协同跟踪框架,其核心是引入了可学习的实例关联机制,这与以往所有方法都有着本质区别。
02
主要研究内容与方法
CoopTrack是一个完全基于实例级别(instance-level)的端到端协同跟踪框架。其核心创新在于,它不再传输和融合庞大的原始数据或中间特征图,而是让每个智能体(车辆或路侧单元)独立解码出稀疏的实例级特征,然后仅将这些轻量级的特征进行传输和融合。这极大地降低了对通信带宽的要求。
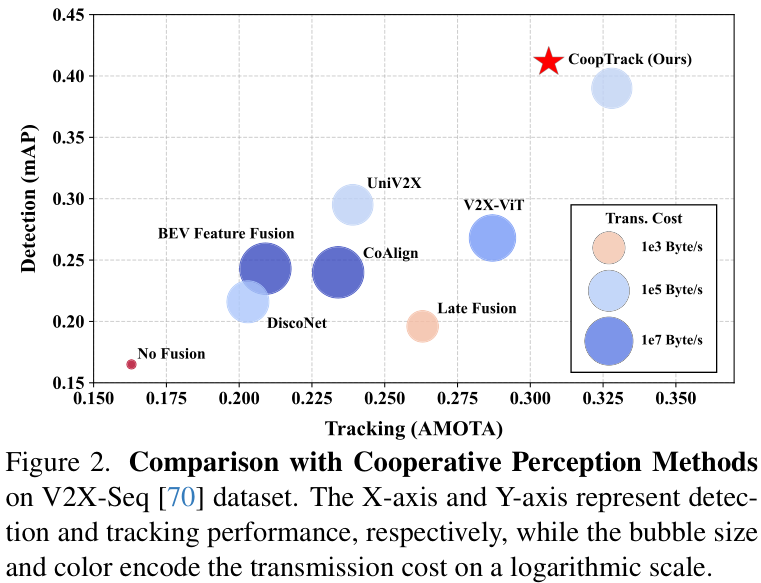
上图对比了不同方法在性能和传输成本上的表现,CoopTrack在实现最高检测和跟踪性能的同时,保持了极低的传输成本(气泡尺寸代表传输成本)。
CoopTrack的整体框架如下图所示,主要由两大核心组件构成:

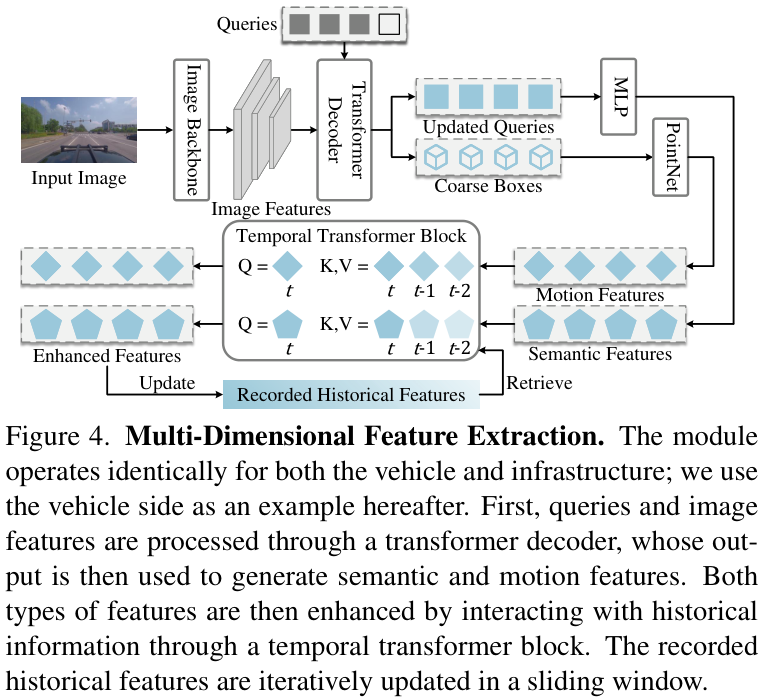
1. 多维特征提取 (Multi-Dimensional Feature Extraction, MDFE)
这个模块负责从每个智能体的传感器数据中提取全面的实例表示。它不仅仅关注目标的语义信息(是什么),还通过一个时间Transformer模块融入历史信息,提取目标的运动特征(怎么动)。这种包含语义和运动的多维特征为后续的跨智能体关联提供了丰富线索。
2. 跨智能体关联与聚合 (Cross-Agent Association and Aggregation)
这是CoopTrack的灵魂所在,负责将来自不同智能体的实例特征进行智能匹配和融合。
跨智能体对齐 (Cross-Agent Alignment, CAA): 首先,通过一个潜空间变换来解决不同智能体(如路侧激光雷达和车载摄像头)之间的领域差异问题。 基于图的关联 (Graph-Based Association, GBA): 这是本文的关键创新。它将来自不同智能体的实例视为图中的节点,利用图注意力网络(Graph Attention Network)来学习它们之间的关联性,生成一个亲和力矩阵。这个矩阵明确了哪些实例是同一个目标,从而实现自适应的、可学习的实例关联。 聚合 (Aggregation): 最后,根据学习到的关联关系,自适应地融合对齐后的特征,生成一个统一、增强的全局目标表示。

03
实验设计与结果分析
研究团队在两个大规模协同感知数据集V2X-Seq和Griffin上对CoopTrack进行了全面评估。
在V2X-Seq数据集上,CoopTrack在所有关键指标上都取得了SOTA(State-of-the-Art)性能,mAP和AMOTA分别达到了 39.0% 和 32.8%,显著超越了之前所有的方法。

在更为复杂的Griffin数据集上,CoopTrack同样表现出色,验证了其强大的泛化能力。
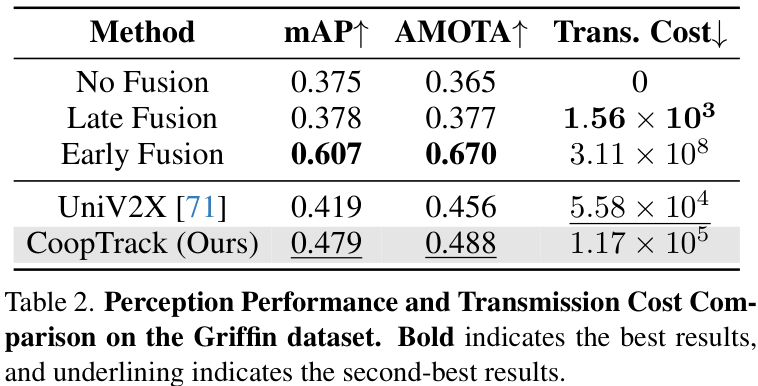
消融实验也充分证明了框架中每个设计模块的必要性。移除MDFE、CAA或GBA中任何一个,都会导致性能的明显下降,这突显了多维特征提取和可学习的跨智能体关联机制的重要性。

04
论文贡献与价值
CoopTrack的提出,为协同感知领域,特别是协同时序感知任务,带来了里程碑式的进展:
提出首个完全实例级的端到端协同跟踪框架:CoopTrack通过创新的“解码后融合”架构,实现了真正意义上的端到端学习,简化了流程并提升了性能。 引入可学习的实例关联机制:基于图的关联模块(GBA)是该框架的核心,它用数据驱动的方式替代了传统的基于规则的关联方法,更加鲁棒和高效。 兼顾高性能与低通信成本:通过只传输稀疏的实例级特征,CoopTrack在实现SOTA性能的同时,将通信开销保持在极低水平,为实际部署提供了可能。 推动领域发展:作为ICCV 2025的Highlight论文,CoopTrack为协同时序感知任务树立了新的标杆,其即将开源的代码将极大地推动社区在这一方向上的后续研究。
总而言之,CoopTrack不仅是一个性能卓越的算法,也是一种全新的、极具启发性的协同感知设计哲学,为实现更安全、更高效的自动驾驶系统铺平了道路。
3D视觉1V1论文辅导来啦!

3D视觉学习圈子
「3D视觉从入门到精通」知识星球(点开有惊喜) !星球内新增20多门3D视觉系统课程、入门环境配置教程、多场顶会直播、顶会论文最新解读、3D视觉算法源码、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群成立啦,微信:cv3d001




![NexusPickit-S1!从零搭建一套无序抓取平台[硬件+源码+课程]](https://xtechcon-static.oss-cn-chengdu.aliyuncs.com/xtimes/xtimes/images/2025-09-01/68b4d47533865.jpeg)