公众号记得加星标⭐️,第一时间看推送不会错过。
随着这颗GPU的发布,NVIDIA 的产品有了范式转变,实际上也合情合理,但这与同构 GPU 机架和集群相比,是一个巨大的转变。
借助这颗名为 NVIDIA Rubin CPX,NVIDIA 在同一个 NVL144 机架中,除了 2026 个 Rubin HBM GPU 之外,还添加了多个 GDDR7 显存 GPU。实际上,这些大型 HBM Rubin GPU 配备了 GDDR7 Rubin CPX GPU 作为协处理器。
CPX 的基本观察是,当今的 LLM 分为两个不同的阶段:预填充( Pre-fill)和解码(decode)。NVIDIA 将其分为上下文阶段和生成阶段。两者之间的转换需要移动键值缓存(key-value)或键值缓存(KV cache)。通常,上下文阶段(预填充)受计算限制,而生成阶段则受内存限制。由于我们正处于构建拥有数十万个 GPU 的集群并逐步扩展到数百万个 GPU 的时代,因此有足够的工作负载和规模将这些任务拆分到两个更优化的架构中,而不是仅仅通过具有海量 HBM 池的 GPU 来运行它们。
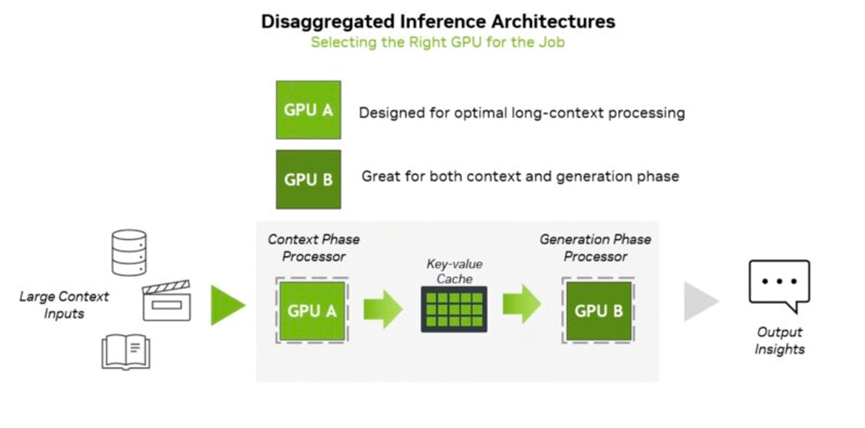
更重要的是,上下文或预填充阶段正变得越来越具有挑战性,尤其是在上下文窗口很长且视频内容丰富的情况下。NVIDIA 正通过 Rubin CX 抓住这一机遇。
Rubin CX 拥有 30PFLOPS 的 NVFP4 性能以及 128GB 的 GDDR7 显存。NVIDIA 声称其指数运算能力是 GB300 的三倍。由于视频工作负载也是其关键驱动因素之一,因此配备了四个 NVENC/NVDEC 引擎。
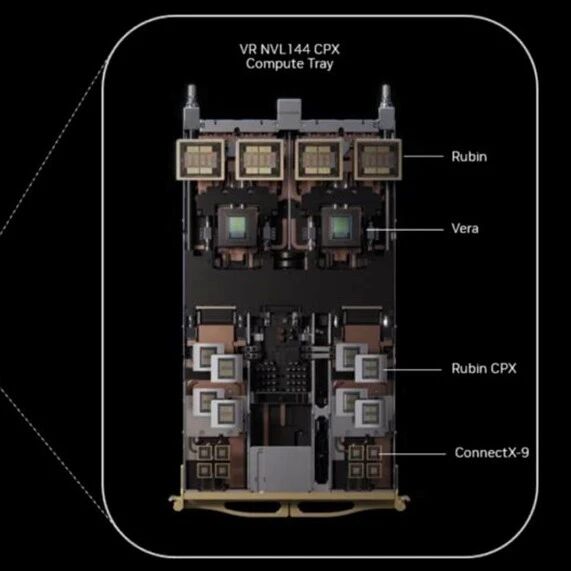
令人兴奋的是,这些也是为异构机架设计的。在这里,我们可以看到一个 Vera Rubin NVL144 CPX 计算托盘。里面有四个 Rubin 组件和两个 Vera Arm CPU。然后是八个 Rubin CPX 组件(NVIDIA 称它们是单片芯片)。最后,还有八个 NVIDIA ConnectX-9,其网卡速率应该相当于 1.6Tbps(ConnectX-7 为 400G,ConnectX-8 为 800G)。这意味着每个计算托盘可以产生 12.8Tbps 的网络吞吐量,或者相当于一整台 Broadcom Tomahawk 3 交换机的吞吐量/相当于当前一代 AI 集群中常见的 NVIDIA Spectrum-4 SN5610 交换机的四分之一。

因此,这款显卡将配备 144 个 Rubin 标准套件,然后在机架中安装 144 个 Rubin CPX。NVIDIA 表示还会提供其他选项,例如 Sidecar 式显卡。或许更有趣的是,NVIDIA 正在利用其强大的技术打造大型单片 GDDR GPU,而 AMD 和英特尔在这方面做得较少,因为他们更注重容量细分市场。Rubin CPX 在 NVL144 机架之外的表现将会如何,值得关注。
由于 NVIDIA Rubin NVL144 CPX 机架设计时采用了许多未来技术,因此它们的目标上市时间为 2026 年底,因此这还需要一年多的时间。
NVIDIA 推出 Rubin CPX
专为大规模上下文推理而设计的全新 GPU
NVIDIA今日宣布推出 NVIDIA Rubin CPX,这是一款专为海量上下文处理而打造的全新 GPU。它使 AI 系统能够以突破性的速度和效率处理数百万个令牌的软件编码和生成视频。
Rubin CPX 与全新 NVIDIA Vera Rubin NVL144 CPX 平台中的 NVIDIA Vera CPU 和 Rubin GPU 协同工作。这款集成式 NVIDIA MGX 系统集成了每秒 8 百亿亿次浮点运算的 AI 计算能力,可提供比 NVIDIA GB300 NVL72 系统高出 7.5 倍的 AI 性能,并在单个机架中提供 100TB 的快速内存和每秒 1.7PB 的内存带宽。此外,还为希望重复使用现有 Vera Rubin NVL144 系统的客户提供了专用的 Rubin CPX 计算托盘。
NVIDIA 创始人兼首席执行官黄仁勋表示:“Vera Rubin 平台将标志着 AI 计算领域的又一次飞跃——它不仅引入了下一代 Rubin GPU,还推出了名为 CPX 的全新处理器。正如 RTX 彻底改变了图形和物理 AI 一样,Rubin CPX 是首款专为海量上下文 AI 打造的 CUDA GPU,在这种 AI 中,模型可以同时推理数百万个知识标记。”
NVIDIA Rubin CPX为长上下文处理提供了最高的性能和代币收益,远远超出了当今系统的设计处理能力。这将使 AI 编码助手从简单的代码生成工具转变为能够理解和优化大型软件项目的复杂系统。
为了处理视频,AI 模型可能需要处理一小时内容中多达 100 万个 token,这突破了传统 GPU 计算的极限。Rubin CPX 将视频解码器和编码器以及长上下文推理处理集成在单个芯片中,为视频搜索和高质量生成视频等长格式应用提供了前所未有的功能。
Rubin CPX GPU 基于 NVIDIA Rubin 架构构建,采用经济高效的单片芯片设计,配备强大的 NVFP4 计算资源,并经过优化,可为 AI 推理任务提供极高的性能和能源效率。
ubin CPX 提供高达 30 petaflops 的计算能力,并采用 NVFP4 精度,以实现最高的性能和准确度。它配备 128GB 经济高效的 GDDR7 内存,可加速最苛刻的基于上下文的工作负载。此外,与 NVIDIA GB300 NVL72 系统相比,它还提供了 3 倍更快的注意力机制,从而提升了 AI 模型处理更长上下文序列的能力,且速度丝毫不会降低。
Rubin CPX 提供多种配置,包括 Vera Rubin NVL144 CPX,可与NVIDIA Quantum‑X800 InfiniBand横向扩展计算架构或搭载NVIDIA Spectrum- XGS 以太网技术和 NVIDIA ConnectX®-9 SuperNIC™ 的 NVIDIA Spectrum- X™ 以太网网络平台结合使用。Vera Rubin NVL144 CPX 助力企业实现前所未有的规模盈利,每投资 1 亿美元即可获得 50 亿美元的token收益。
参考链接
https://nvidianews.nvidia.com/news/nvidia-unveils-rubin-cpx-a-new-class-of-gpu-designed-for-massive-context-inference
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
END
今天是《半导体行业观察》为您分享的第4154期内容,欢迎关注。
推荐阅读

加星标⭐️第一时间看推送,小号防走丢