
本文的共同第一作者为香港大学 InfoBodied AI 实验室的博士生孙力和吴杰枫,合作者为刘瑞哲,陈枫。通讯作者为香港大学数据科学研究院及电机电子工程系助理教授杨言超。InfoBodied AI 实验室近年来在 CVPR,ICML,Neurips,ICLR 等顶会上有多项代表性成果发表,与国内外知名高校,科研机构广泛开展合作。
标题:HyperTASR: Hypernetwork-Driven Task-Aware Scene Representations for Robust Manipulation
作者:Li Sun, Jiefeng Wu, Feng Chen, Ruizhe Liu, Yanchao Yang
机构:The University of Hong Kong
原文链接: https://arxiv.org/abs/2508.18802
出发点与研究背景
在具身智能中,策略学习通常需要依赖场景表征(scene representation)。然而,大多数现有多任务操作方法中的表征提取过程都是任务无关的(task-agnostic):
无论具身智能体要 “关抽屉” 还是 “堆积木”,系统提取的特征的方式始终相同(利用同样的神经网络参数)。
想象一下,一个机器人在厨房里,既要能精准抓取易碎的鸡蛋,又要能搬运重型锅具。传统方法让机器人用同一套 "眼光" 观察不同的任务场景,这会使得场景表征中包含大量与任务无关的信息,给策略网络的学习带来极大的负担。这正是当前具身智能面临的核心挑战之一。
这样的表征提取方式与人类的视觉感知差异很大 —— 认知科学的研究表明,人类会根据任务目标和执行阶段动态调整注意力,把有限的感知资源集中在最相关的物体或区域上。例如:找水杯时先关注桌面大范围区域;拿杯柄时又转向局部几何细节。
那么,具身智能体是否也可以学会 “具备任务感知能力的场景表征” 呢?

创新点与贡献
1. 提出任务感知场景表示框架
我们提出了 HyperTASR,这是一个用于提取任务感知场景表征的全新框架,它使具身智能体能够通过在整个执行过程中关注与任务最相关的环境特征来模拟类似人类的自适应感知。
2. 创新的超网络表示变换机制
我们引入了一种基于超网络的表示转换,它可以根据任务规范和进展状态动态生成适应参数,同时保持与现有策略学习框架的架构兼容性。
3. 兼容多种策略学习架构
无需大幅修改现有框架,即可嵌入到 从零训练的 GNFactor 和 基于预训练的 3D Diffuser Actor,显著提升性能。
4. 仿真与真机环境验证
在 RLBench 和真机实验中均取得了显著提升,验证了 HyperTASR 在不同表征下的有效性(2D/3D 表征,从零训练 / 预训练表征),并建立了单视角 manipulation 的新 SOTA。
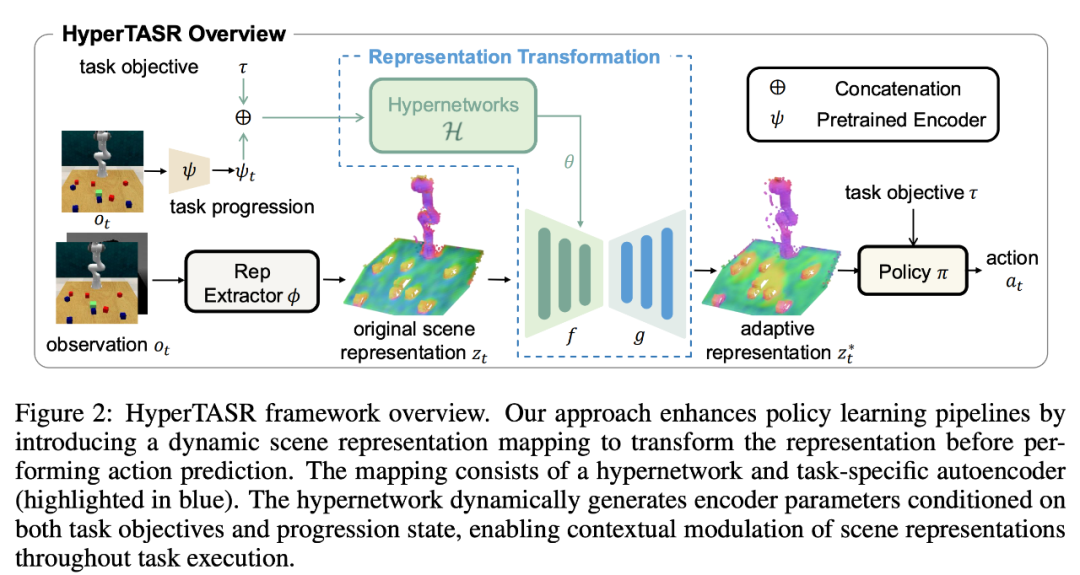
HyperTASR 概述
在这项工作中,我们提出了 HyperTASR —— 一个基于超网络的任务感知场景表征框架。它的核心思想是:具身智能体在执行不同任务、处于不同阶段时,应该动态调整感知重点,而不是一直用一套固定的特征去看世界。
动态调节:根据任务目标和执行阶段,实时生成表示变换参数,让特征随任务进展而不断适配。
架构兼容:作为一个独立的模块,可以无缝嵌入现有的策略学习框架(如 GNFactor、3D Diffuser Actor)。
计算分离:通过超网络建立 “任务上下文梯度流(task-contextual gradient)” 与 “状态相关梯度流(state- dependent gradient)” 的分离,大幅提升学习效率与表征质量。
换句话说,HyperTASR 让具身智能体在执行任务时,像人类一样 “看得更专注、更聪明”。
任务感知的场景表示 (Task-Aware Scene Representation)
传统的具身智能体操作任务(Manipulation)学习框架通常是这样的:
1. 从观测  提取一个固定的场景表征
提取一个固定的场景表征 
2. 在动作预测阶段,再利用任务信息 ,共同预测执行的动作:
,共同预测执行的动作:

这种做法的局限在于:表征提取器始终是任务无关的。不管是 “关抽屉” 还是 “堆积木”,它提取的特征都一样。结果就是:大量无关信息被带入策略学习,既降低了策略学习的效率,也增加了不同任务上泛化的难度。
受到人类视觉的启发,我们提出在表征阶段就引入任务信息:
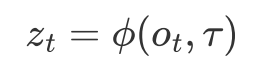
这样,场景表示能够随任务目标与执行阶段动态变化,带来三个好处:
更专注:只保留与当前任务相关的特征
更高效:过滤掉无关信息
更自然:和人类逐步完成任务时的视觉注意模式一致
超网络驱动的任务条件化表示 (Hypernetwork-Driven Task-Conditional Representation)
HyperTASR 的详细结构如 Figure 2 所示。为了实现任务感知,我们在表征提取器后加入了一个 轻量级的自编码器:
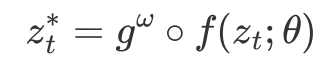
其中:
 :编码器,
:编码器, :编码器参数
:编码器参数 :解码器
:解码器 :原始表征,
:原始表征,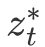 :任务感知表征
:任务感知表征
引入自编码器的一大优势在于,自编码器适用于不同的场景表征形式(2D/3D 表征都有对应的自编码器),另外自编码器可以维持原来场景表征的形式,无须调整后续策略网络的结构。
关键在于: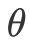 不是固定的,而是由超网络根据任务与执行状态动态调节的:
不是固定的,而是由超网络根据任务与执行状态动态调节的:

这里:
 任务目标(如 “拧上绿色瓶子”)
任务目标(如 “拧上绿色瓶子”) 任务进展编码(task progression)
任务进展编码(task progression) 由超网络
由超网络  生成的动态参数
生成的动态参数
这样,场景表征不仅会随任务不同而变化,也会在任务的执行过程中不断动态迁移。
这种设计的优势:
1. 梯度分离:任务上下文与状态相关信息在梯度传播中分离,增强可解释性和学习效率
2. 动态变换:不是简单加权,而是真正改变表征函数,使得表征更加灵活
实验验证
HyperTASR 的另一个优势是模块化、易集成。这种 “即插即用” 的设计让 HyperTASR 可以同时增强 从零训练和预训练 backbone 两类方法。我们分别把它嵌入到两类主流框架中进行验证:
1.GNFactor(从零训练):使用 3D volume 表征
2.3D Diffuser Actor(基于预训练):使用 2D backbone 提取特征再投影到 3D 点云
我们只使用了行为克隆损失(Behavior Cloning Loss)作为我们网络的训练损失。

仿真实验
在仿真环境 RLBench 中的 10 个任务上进行训练,实验结果如 Table 1 所示:
集成到 GNFactor 后,在无需特征蒸馏模块的情况下(训练无需额外的监督信息),成功率超过基线方法 27%;
集成到 3D Diffuser Actor 后,首次让单视角操作成功率突破 80%,刷新纪录。
在此基础上,我们进一步通过网络的梯度进行了注意力可视化:

从 Figure 3 中我们可以观察到:
传统方法的注意力往往分散在背景和无关物体;
HyperTASR 的注意力始终集中在任务相关的物体上,并随着任务进度动态变化。
另外,我们进行了消融实验,证明了 HyperTASR 设计中,引入任务进展的合理性,以及证明了使用超网络相比于直接利用 Transformer 将任务信息融合到场景表征里,能够获得更大的性能提升。
真机实验
我们采用 Aloha 进行了真机 manipulation 实验。如 Table 2 所示,在 6 个实际任务中,HyperTASR 在仅每个任务 15 条示教样本的有限条件下达到了 51.1%,展示了在真实环境操作中的强泛化能力。

一些真机实验对比结果如下:

参考
[1] Ze, Yanjie, et al. "Gnfactor: Multi-task real robot learning with generalizable neural feature fields." Conference on robot learning. PMLR, 2023.
[2] Ke, Tsung-Wei, Nikolaos Gkanatsios, and Katerina Fragkiadaki. "3D Diffuser Actor: Policy Diffusion with 3D Scene Representations." Conference on Robot Learning. PMLR, 2025.

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com










