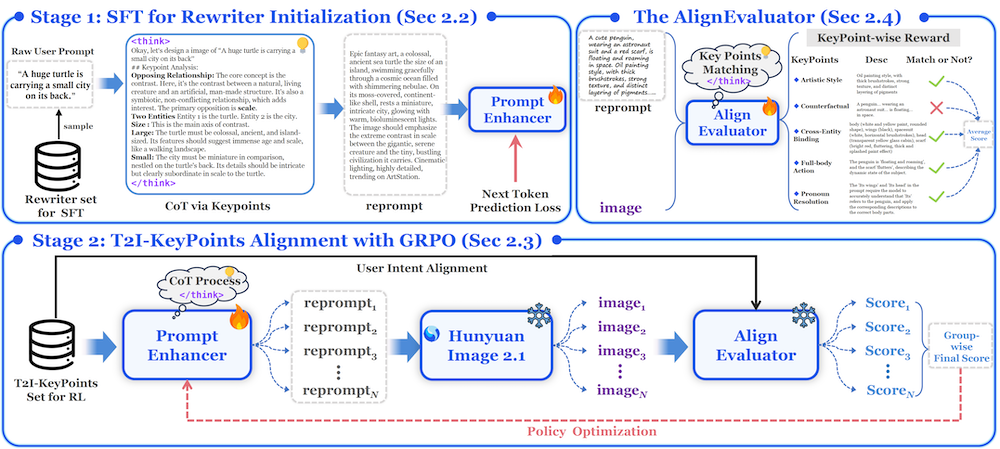
在开源模型中,图文一致性排名第一。作者 | 江宇编辑 | 漠影智东西AI前瞻9月10日报道,前日,腾讯开源其高分辨率文生图模型HunyuanImage-2.1,并同步释出推理代码和模型权重。作为一款具备2K超高清生成能力的扩散模型,HunyuanImage-2.1在架构设计、文本理解、多语种支持、推理效率等多个层面进行了系统性优化。它不仅支持中文和英文的复杂描述,还能自动润色提示词、提升图像语义对齐质量,同时具备图像精修能力。HunyuanImage-2.1已在GitHub上线,并开放了三项核心功能:文本生成图像、提示词增强与图像精修。用户也可以自由选择画幅比例与推理参数,也可选用“增强提示词”“图像精修”等附加选项,以生成更高质量的图像内容。目前,混元官网仅支持文生图功能,提示词增强与图像精修暂未上线。体验指路:混元官网:https://hunyuan.tencent.com/modelSquare/home/play?modelId=286&from=/visualGithub:https://github.com/Tencent-Hunyuan/HunyuanImage-2.1Huggingface:https://huggingface.co/tencent/HunyuanImage-2.101.三大功能支持2K出图,可控性更强在GItHub的体验页面中,用户可以使用HunyuanImage-2.1完成以下三类任务:1、文本生成图像:输入中英文提示词,生成最高可达2048×2048分辨率的图像,支持16:9、4:3、1:1等多种画幅比例;2、提示词增强:自动对用户输入的提示词进行语义润色与扩写,强化描述细节,提高成图质量;3、图像精修:上传已有图片并输入修改要求,由精修模型对画面清晰度、细节层次进行再提升。在基础设定中,用户可手动调节推理步数(默认50步)、提示词引导强度(默认3.5),并选择是否开启自动提示词增强(Reprompt)与精修(Refiner)。若显存充足,可关闭CPU offloading,提升生成速度。02.体验:中文渲染在线提示词增强和图片精修都能跑通智东西也上手体验了一番。1、文生图体验场景1:家长群里老师临时通知“明天带一张手抄报,主题为《中秋赏月》。提示词:中秋主题A4手抄报线稿,白底,粗黑描边,画面分三栏:左上角圆月+玉兔简笔画,右下角卡通嫦娥+月饼,底部留白写古诗,中间一排空心艺术字标题“中秋团圆”,整体简洁可爱,适合儿童涂色,无阴影、无填充色。混元生成的画面干净、布局合理,也没有多余的渲染,直接打印后可作为涂色底稿使用,一键解决爸妈的“作业焦虑”。2、提示词增强体验场景2:电商公司要做“双11预热海报”,只会写一句大白话:“热闹购物节氛围”。提示词:双11预热海报。增强后的提示词:一张充满动感的“双11”双十一购物狂欢日预热海报,画面中央聚焦于一个巨大的、发光的“11”数字。这个巨大的“1”数字由明亮的霓虹灯光效构成,呈现出从亮红色到电光蓝的渐变色彩,数字边缘带有柔和的光晕,具有强烈的科技感和视觉冲击力。在“1”字的正下方,是一行醒目的白色加粗艺术字体,内容为“双11”。数字的周围和背景中,分布着大量被动态模糊和数据流线条勾勒出的购物小哥剪影,他们有的高举手机,似乎在抢购,有的在浏览商品,姿态各异,充满了活力。背景是一个深邃的暗色空间,点缀着微小的、闪烁的星光或数据粒子,增强了画面的数字感。画面的底部区域,放置了一个虚拟的购物车图标和价格标签的样式,上面用醒目的红色字体写着“全场5折起”,并附有一个虚构但精致的电子产品或潮流服饰的特写图片。整体光线集中在中央的“1”字和周围的特效上,形成强烈的视觉焦点,营造出一种紧张、刺激且极具期待感的氛围。这张图片是一张融合了3D渲染、抽象设计和商业摄影元素的数字艺术作品,属于典型的电商大促宣传海报。▲增强后指令所生成的海报生成的图像还原了增强提示词中的元素布局,灯光、人物、数字感都有体现,整体画面比较完整,氛围也足够热闹。3、照片精修体验场景3:把“旅游打卡废片”秒变“小红书封面”。提示词:矫正水平线,恢复洪崖洞金黄灯光细节,压高光提阴影,去掉江面彩色噪点,强化吊脚楼木质纹理,保留现场烟火气。▲参考图▲精修后的图片处理后的照片确实清晰了一些,灯光颜色恢复得比较自然,远处楼体细节也比原图更清楚。03.架构亮点压缩VAE、双语编码器与人类反馈强化训练HunyuanImage-2.1的模型架构采用了“两阶段生成策略”,即:基础文生图模型+精修模型。其中,基础模型专注于语义理解与图像生成,精修模型则负责细节增强与瑕疵修复。核心技术亮点包括:1、高压缩率VAE+DiT主干网络:通过32×空间压缩率的VAE,大幅降低输入Token数量,使得生成2K图像的Token规模与他人1K图像相当,显著提升推理效率。2、双文本编码器:同时引入视觉语言大模型(MLLM)与多语种字符级ByT5编码器,分别处理场景理解与文字表达,确保多语言支持下的高质量图像生成。3、双流扩散Transformer结构:构建17B参数规模的大模型,在处理复杂构图与多主体任务时具备更强表征能力。4、人类反馈强化学习(RLHF):训练过程中使用两阶段后训练策略(SFT+RL),结合“高质量图像选优样本”与“奖励分布对齐机制”,优化生成图像的结构完整性与美学表现。5、PromptEnhancer重写模型:该模块通过结构性重写用户输入的提示词,以增强描述信息的完整度与图像生成的语义贴合度。其训练过程中引入了AlignEvaluator对图文语义一致性进行精细化评分。其核心机制是以“思维链式改写(Chain-of-Thought Rewriting)”为策略,通过两阶段训练流程完成提示词优化:第一阶段:通过监督微调(SFT),对海量用户提示词与增强后Prompt对进行结构学习;第二阶段:引入基于奖励的策略优化(GRPO),由“AlignEvaluator”对生成图像与提示词之间的语义一致性进行24项细粒度评估,进而反馈回提示词改写策略,完成高质量回写。该机制可显著提升提示词对复杂属性、否定结构、组合关系的表达准确性。例如,一条简单提示“汤姆猫在画画”,在PromptEnhancer处理后会被自动扩写为“身穿红色围裙的汤姆猫,在写实画风的油画布前,手持毛笔作画”,从而生成更具意图还原度的图像。6、Meanflow蒸馏推理:为解决工业级大模型推理速度慢的问题,HunyuanImage-2.1首次将Meanflow成功用于大模型蒸馏,在少量采样步骤下仍可保持图像质量,提升推理效率。此外,在数据构建上,HunyuanImage引入了结构化分层Caption机制(短/中/长/超长)与OCR Agent+IP RAG组合策略,显著增强了模型理解密集文本与世界知识描述的能力。使用HunyuanImage-2.1进行本地部署时,最低需配备支持CUDA的NVIDIA GPU,显存不少于59GB(生成2048×2048图像时,batch size=1)。当前仅支持Linux系统。上述显存要求基于启用模型CPU卸载(offloading)时的测得值,若设备内存充足,也可关闭卸载以获得更快的推理速度。同时,腾讯团队已确认将逐步开源PromptEnhancer-7B版本,包括更大规模的提示词改写模型、奖励模型AlignEvaluator、数据集与评测基准。同时,针对图生图、文生视频、图生视频等多模态任务的PromptEnhancer系列亦在开发中,即将推出。04.评测对比:在开源模型中图文一致性排名第一,逼近闭源商业模型表现在多个维度的标准化评测中,HunyuanImage-2.1展现出强劲性能,尤其在图文语义对齐方面已达到开源模型的领先水平,整体表现接近GPT-Image、Seedream-3.0等闭源商业模型。根据SSAE(Structured Semantic Alignment Evaluation)结构化语义对齐评测,研究团队基于12个类别、3500个语义关键点构建了自动化评估框架,分别评测了包括主主体、次主体、场景构成与图像风格在内的24项细分能力。从结果来看,HunyuanImage-2.1在Mean Image Accuracy(0.8888)与Global Accuracy(0.8832)指标上,超越了所有开源模型,在主客体识别、动作理解、图像构图等多个子维度也取得领先或持平表现:1、在“主主体识别”类维度中,HunyuanImage-2.1在名词(0.9339)、关键属性(0.9341)上接近Seedream-3.0;2、在“次主体表达”维度,其在名词(0.9627)和动作(0.9615)上的准确率接近GPT-Image(0.9494,0.8800);3、在“场景控制”中,其对镜头(0.7527)、风格(0.8689)和构图(0.7619)的把握能力与主流闭源模型接近。此外,在由100位专业标注员参与的GSB人评中,HunyuanImage-2.1在单轮推理、随机提示词设定下,对比Seedream-3.0(闭源)略逊1.36%,但在与Qwen-Image(开源)对比中胜出2.89%。这一结果表明,在不依赖样本筛选的实用生成场景中,HunyuanImage-2.1已具备高可用性和广泛适配性。05.结语:高分辨率中文出图开源模型也能胜任了HunyuanImage-2.1让中文场景下的高分辨率图像生成更易获取,也把提示词增强和精修做了同步精进。作为开源成果,它或许能成为国内更多应用探索的起点。