在具身智能驱动的机器人操控领域,基于模仿学习的视觉—运动策略(Visuomotor Policies)已成为实现机器人自主操作的重要技术路径。这类策略通常依赖于视觉观测与本体感知状态(Proprioceptive States)的融合范式,通过融合来自摄像头等传感器的外部环境信息和机器人自身的关节角度、末端位置等内部状态,实现对动作输出的精确控制。该范式虽已在多个任务中取得显著成效,并被广泛应用于各类机器人学习系统中,却隐含着一个关键缺陷:策略模型对本体感知状态输入的过度依赖,容易导致其在训练轨迹上产生过拟合,进而削弱其在未见空间配置下的泛化能力。
具体而言,当策略过度依赖如机器人基座坐标、关节角度等内部状态时,其决策过程会逐渐“固化”于特定的空间位置与运动轨迹。一旦测试环境中物体的位置、桌面的高度或机器人的起始位姿发生改变——即便视觉场景在语义上高度相似——策略的表现也可能急剧下降。这种对空间变化的敏感性,严重制约了机器人在动态、非结构化现实环境中的适用性,也使得每一项新任务的部署都需耗费大量数据与调试成本。
针对上述痛点,千寻智能的研究团队在论文“Do You Need Proprioceptive States in Visuomotor Policies?”中进行了深入探讨,并提出了一种名为 State-free Policy 的新型“无状态”运动策略。该策略完全摒弃了对本体状态信息的依赖,仅通过视觉观察指导机器人完成任务,展现出卓越的空间泛化能力。
▍ State-free Policy无状态策略的实现条件
State-free Policy无状态策略背后建立于两项紧密结合的核心设计原则,它们共同确保了在缺乏内部状态反馈的情况下,策略仍能实现精确、鲁棒的控制。

相对末端执行器(EEF)动作空间 :传统基于状态的策略往往在绝对坐标系中运作,例如指令机器人“移动至世界坐标系中的(x, y, z)点”。这种方式虽直观,但其性能强烈依赖于对自身位置的精确感知。一旦机器人基座发生偏移或环境坐标系发生变化,策略便容易失效。
无状态策略则采用了相对末端执行器动作空间。在此框架下,机器人不再接收绝对坐标指令,而是输出以当前末端为参考系的相对运动指令,例如“向上移动5厘米,再向左旋转10度”。这自然赋予了策略对位置变化的不变性,是空间泛化的基础。
完整的任务观察:有效的无状态策略的另一个关键条件是确保充足的任务相关视觉信息。为此,研究人员为末端执行器配备了双广角摄像头系统,视野达到120°×120°,确保在执行任务的任何阶段,策略都能获得充分的环境信息。
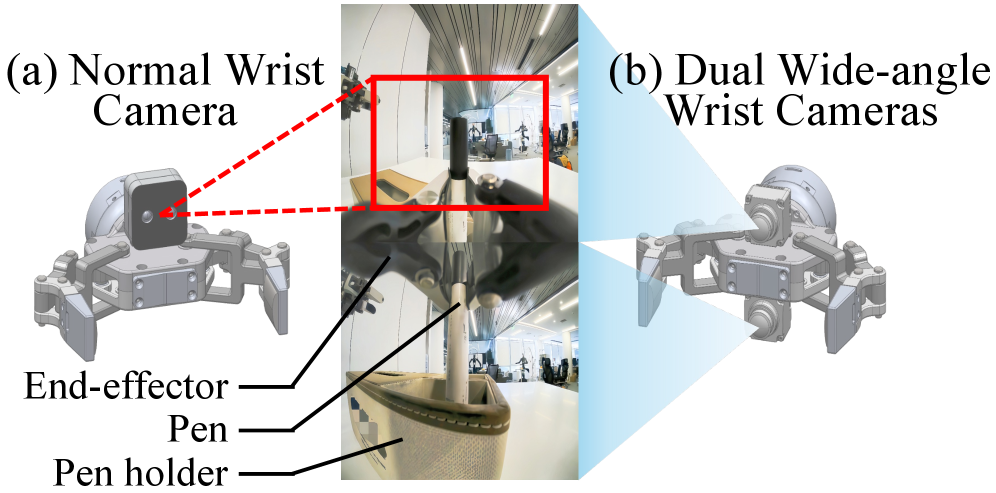
这种无状态策略的机制迫使策略对任务环境有更深入的理解,而不是简单地记住轨迹,从而使无状态策略能够实现基于状态的策略无法提供的优势:
• 空间泛化:由于无状态策略不依赖于状态输入,它们可以避免对训练轨迹的过拟合。因此,它们表现出强大的高度和水平泛化能力,其中高度指的是任务相关物体在垂直方向上的位置变化,水平指的是物体在二维平面上的位置变化。
• 数据效率:基于状态的策略需要大量在不同位置采集的演示数据来防止过拟合,数据收集成本极高。而无状态策略本身就不易过拟合轨迹,因此用更少的演示数据就能达到相同的效果。这大大降低了机器人学习和部署的成本。
• 跨具体化适应:不同的机器人型号,其内部状态的定义和坐标系可能完全不同。将一个在A机器人上训练好的策略迁移到B机器人上,基于状态的策略需要复杂的调整。而无状态策略只关心视觉输入和相对动作,只要摄像头视角相似,它就能更快地适应新的机器人身体,实现了“一个大脑,多具身体”的潜力。
▍现实测试,从拾笔到折衬衫,机器人的“泛化能力大爆发”
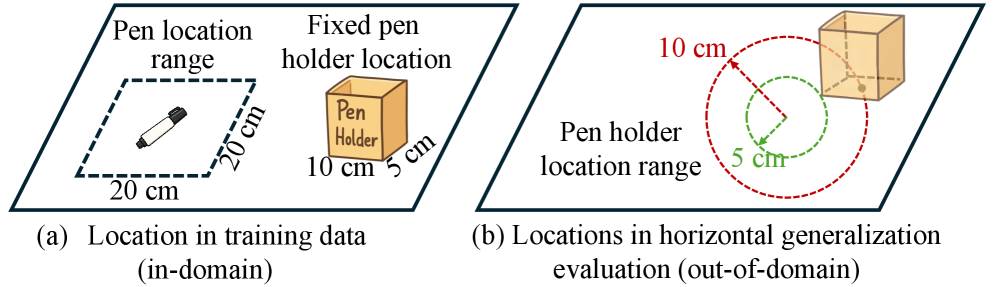
为严谨评估无状态策略的实际效能,研究团队在现实世界中设计并执行了一系列涵盖不同难度的机器人操作任务。测试环境经过严格把控:在训练数据采集时,桌面高度、机器人基座位置、目标物体位置等变量均被固定。这意味着,模型在测试中展现出的任何泛化能力,都纯粹源于其自身架构的优越性,而非训练数据中已有的多样性。
实验结果表明,State-free Policy在空间泛化方面远超传统的State-based策略。
以最基础的“拾笔入筒” 任务为例:
传统State-based策略:在训练的 80 厘米桌子高度下,成功率 100%;可一旦桌子高度发生改变,比如降到72 厘米或升到 90 厘米,成功率直接跌到 0%;当笔筒位置在水平面移动时,State-based策略成功率同样为0%。
State-free Policy无状态策略:不管桌子高度怎么变,成功率都保持在98% 左右;笔筒位置在水平面移动 10 厘米,成功率也有 58%。
更关键的是,这种提升不是个例。在“盖茶杯盖”“取瓶子” 等其他拾取任务中,无状态策略的 “高度泛化平均成功率” 从 0% 提升到了 85%,“水平泛化平均成功率” 从 6% 提升到了 64%
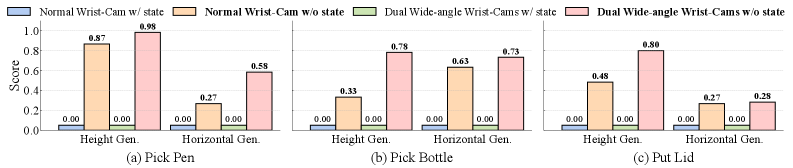
State-free Policy在桌面高度和水平位置变化的泛化测试中表现优异
面对更难的任务,无状态策略的优势更明显。例如“全身机器人取瓶子” 任务:机器人需要先弯腰打开冰箱门,伸手拿瓶子,再关门,涉及躯干、腰部、手臂的协调。传统策略因为依赖身体关节角度的记忆,换个冰箱位置就失败,成功率只有 11.7%;而无状态策略靠视觉判断冰箱门、瓶子的相对位置,成功率提升到 78.4%,几乎能稳定完成整套动作。

在叠衣服与机器人取物等复杂任务中State-free Policy表现同样出色
▍重新思考机器人传感配置:一个反直觉的发现
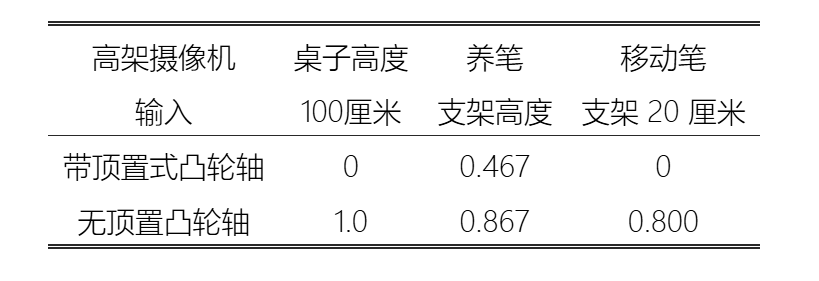
在深入研究过程中,团队还有一个反直觉但却至关重要的发现:对于无状态策略,常用的头顶固定摄像头可能弊大于利。
当物体位置变化很大时,头顶摄像头的视角会发生剧烈改变,导致图像分布与训练时不同,从而干扰策略。而腕部摄像头会随着机械手移动,总能捕捉到与手相关的、视角一致的局部画面。实验表明,仅依靠双广角腕部摄像头,完全移除头顶摄像头,无状态策略在极端泛化场景下表现得更加稳定。这一发现为未来机器人传感器的设计提供了新思路。
▍结语
千寻智能团队提出的无状态策略,是对当前具身智能控制范式的一次深入反思与成功创新。它通过摒弃本体感知状态,并辅以相对动作空间和完备的视觉观察,成功地解决了传统方法在空间泛化、数据效率和跨平台迁移方面的核心痛点。










