点击下方卡片,关注“具身智能之心”公众号
作者丨Jie Wang等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
blog:https://penn-pal-lab.github.io/Pi0-Experiment-in-the-Wild/
这是 GRASP Lab 的一篇在复杂真实场景中(in the wild)评估PI0-FAST-DROID的工作,这样可以更直观的帮助理解 PI0 这类通用 policy 的目前性能和边界,以及探索未来可以解决的方向。
当然现在还有更新一代的 PI0.5 方案(但是还没有开源)。
相关资料:
Droid 数据集:https://droid-dataset.github.io/
引言:
机器人操作领域,一直以来都缺少能够“开箱即用”地处理新物体、新位置和新任务的预训练模型。机器人专家们往往曾经历过令人沮丧的过程:为了获取一个机器人 policy,不得不进行繁琐的工程设计和数据收集,结果却发现,即使环境发生微小的变化,这些 policy 也会失效。
一个很有前景的方向是在大规模数据集上训练通用模型(generalist models),期望它们能够在新的情境下表现出合理的行为,从而减轻终端用户的负担。过去的一年令人振奋,因为第一波这样的模型已经涌现,让我们看到了实现通用机器人这一梦想的可能。
因此,当 Physical Intelligence 公司将其 PI0 模型公之于众时,迫不及待地亲自进行了尝试。其表现给我们留下了深刻的印象,也让我们对这些模型持续改进所带来的可能性感到非常兴奋。
评估方法:
评估使用π₀-FAST-DROID模型进行的,该模型专门针对 DROID 机器人平台进行了微调。DROID 平台包含一台 Franka Panda 机器人,并在其侧方和手腕处各安装了一个摄像头。本体如下图

为这个平台配置策略推理(policy inference)的过程异常简单——完全不需要进行摄像头/控制器的校准,也无需针对特定的工作空间进行任何调整。模型只需要用户输入一段描述任务的文本提示(prompt),并结合来自手腕和侧方摄像头的图像,就能输出相应的动作(如下图所示,直接在未见场景叠报纸)。


机器人的工作空间、测试目标、操作的环境如上图所示
实验是在厨房环境中进行的。厨房里有各种各样的物品、背景和照明条件,非常适合设计各种任务
关键的是,只有当人们能够轻松尝试并亲自验证模型时,主观(vibe-based) 评估才具有可信度。与开源大型语言模型(LLM)一样,Pi0 易于部署,使得任何拥有 DROID 设置的机器人实验室都能进行此类评估。总结了 300 多次试验中的发现
接下来,将探索 PI0-FAST 其能力、特性及其对 robot learning 未来的影响
评估机器人策略是困难的,因为很难选定一组任务,这些任务能涵盖任意用户认为有用的广泛行为范围。
从自然语言处理(NLP)社区汲取灵感,采用了他们的“主观检测(vibe-checking)”方法。vibe-checking 要求用户直接通过聊天来评估大型语言模型(LLMs)本身,话题可以随意,而不依赖于标准基准测试。同样,本文也对 PI0-fast 进行了评估
进行“vibe-checking”,这是由终端用户生成的非结构化现实世界任务。即兴创作任务,调整摄像机角度,重新布置物品,并尝试思考 edge cases ,以对模型进行压力测试。
进行了 300 多次试验在各种操作任务上。需要强调的是,评估是为了满足自己对模型能力的好奇心(例如,模型是如何处理有连接关系的物体或遮挡视线),并且没有对模型的能力进行全面评估。发现总结如下:
对合理行为的强烈先验假设:
它在我们的各种任务中产生了明智的行为,但明智的行为往往不足以完成任务。
提示工程问题:
尽管该系统能够对多种提示和摄像机视角产生合理的动作,但观察到,当措辞或视角发生变化时,其在同一任务上的成功率会有大幅波动。为了实现稳定的性能,请使用规范的提示(动词 + 宾语),并选择能清晰展示目标物体的摄像机角度。
奇怪特性:
它能够从失败中恢复,并处理场景中移动的人体,但在任务中途冻结、避碰和精细操作方面表现不佳。
值得注意的地方:
发现了两个令人印象深刻的点:
(1)具有良好的视觉-语言理解能力
(2)能够在任何场景中模仿连续行为,我们将在本节后续内容中对此进行详细讨论。
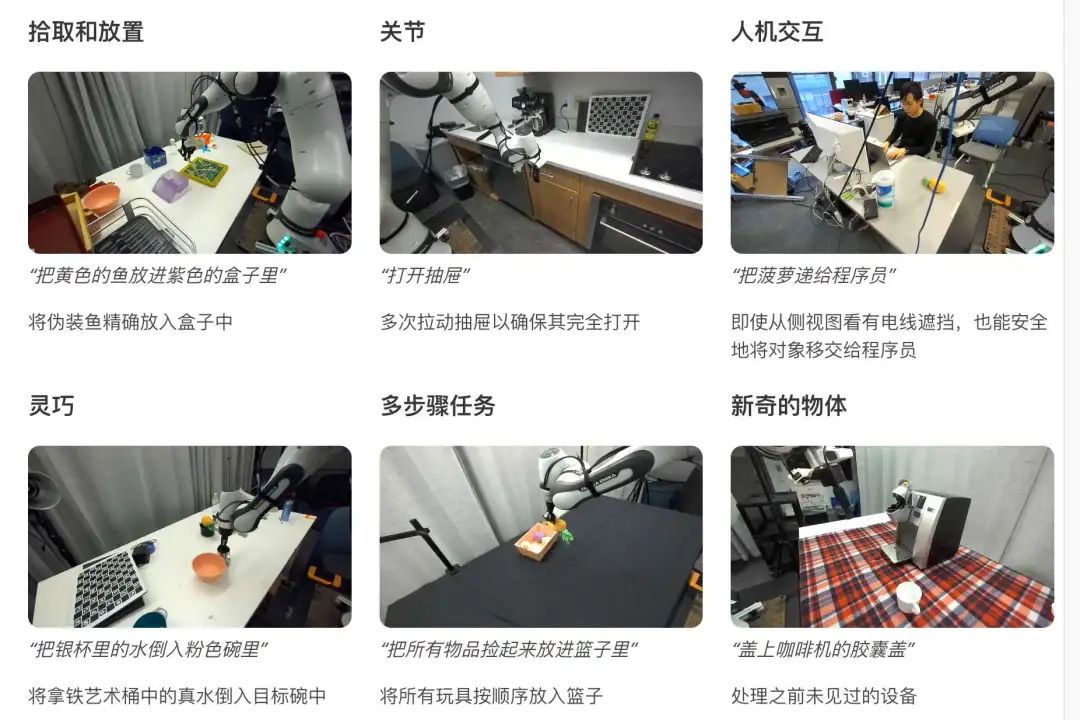
复杂场景下的稳定视觉语言理解
采用 Google DeepMind 的 3B VLM PaliGemma 作为其视觉编码器,展现出强大的场景理解能力和适应性。尽管仅依赖未校准的单目 RGB 输入(压缩后为 224x224 像素),它仍能处理极具挑战性的物体和环境,包括透明或伪装的物品,以及训练期间未曾见过的物品。
它可以抓取透明物体
能够识别和操控透明物体,如下图所示。它以稳定的抓握方式拾起瓶子,将其与小杯对齐,然后精准地将其放入。许多传统的抓握检测技术需要对场景进行精确的二维或三维重建,而透明物体可能会导致重建精度问题。更令人印象深刻的是,该模型仅凭未经校准的单色 RGB 图像就能检测透明物体。

即使物体隐藏在彩色背景中,它也能抓住它
即使放在色彩鲜艳的棋盘游戏上,也能识别出这里的“黄色鱼”。这个物体形状奇特,难以辨认,而且与背景融合得很好,但 检测得足够好,能够掌握它。

它对输入中的人类活动具有鲁棒性
在评估过程中,侧视摄像头多次捕捉到背景中移动的人。然而,可以始终专注于其任务,使机械臂的动作专注于物体操作。
本文认为有两个原因对人体运动的鲁棒性。首先,预训练的 VLM backbone 基于涉及人类的图像进行训练,因此人类处于分布内。接下来,正如遮挡实验所示,该策略似乎在拾取和放置任务期间优先考虑腕部摄像头的图像,因此侧视摄像头中的干扰物似乎对策略的影响微乎其微。
以下是两段涉及人类场景的侧视视频。 更多关于人机交互的实验,请参阅附录 B.6。

计算机视觉和机器人领域的许多现有研究都专注于透明物体的检测和操控。但值得庆幸的是,我们有一个端到端、数据驱动的系统可以实现这一目标,无需任何特殊逻辑或对透明物体的关注。
“处理透明度、混乱和干扰项的能力预示着未来机器人将像人类一样看待世界——通过语义,而不仅仅是像素。”
pi0 可以逐步模仿行为
如果你是人类,你可以轻松模仿上述视频中机器人的行为。这是因为机器人的行为是连续的,每一步都独立于前一步。然而,在机器人技术的发展史上,情况并非如此。传统的行为克隆模型或许能够记住一条精确的路径;但改变场景或从不同的高度开始可能会导致模型失败。这是因为数据的差异可能导致机器人学习到非常糟糕的行为,例如碰撞和失败。通过实验,我们观察到在广泛的操作任务中表现出类似的行为模式。虽然它是一个没有任何记忆或历史的自回归模型,通常会逐步执行任务,例如:
到达 → 抓取 → 转移 → 释放 → 重置 → 空闲
值得注意的是,这种模式并不是硬编码在模型结构中的,而是从数百万个演示数据中自然产生的——这表明学习跨环境的一致任务执行先验。例如,即使当它不熟悉某个物体或任务时,它通常会主动探索附近的可供性丰富的区域,并使用腕部摄像头来决定是否抓取。
在某些试验中,我们还观察到类似重置的行为:如果当机器人感知到任务完成(例如,将物品放入碗中后),它可能会返回到初始位置并停止。虽然这通常表明任务边界结构良好,但也可能导致提前停止/冻结,尤其是在多物体场景中——有关提前停止失败案例的分析,见下节。
虽然这种排序可能表明已经学会了对任务的内部理解,我们提醒不要进行这样的框架化 。这些模式可能反映的是数据分布的属性(例如,马尔可夫模型、短期任务) ,而不是表明 policy 已经获得了明确的任务推理或记忆。

但这并不意味着已经解决了模仿学习的问题。以合理的方式遵循子任务序列,可能更多地是对任务分组而非当前算法的观察——许多测试任务可能具有足够的马尔可夫性,以至于无历史记录的 policy 可以遵循合理的子任务链。将在下一节中进一步讨论。
问题
在不同任务、位置和光照条件下表现出非常出色的鲁棒性。然而,也观察到了一些失败的情况:
失败案例

提前停止问题
一种常见的失败情况是,policy 在执行过程中可能意外停止,导致任务无法完成,直至人工干预。这种行为源于两个相关因素:语义模糊性和自回归动作解码的局限性。
可能的原因如下:
VLM 部分无法理解该指令
与那些具有大量参数的商业聊天机器人不同,基于 PaliGemma(一个非常小的 VLM 模型)构建。因此,它缺乏 LLM 可以用来识别不熟悉物体类别的常识性推理能力。当它无法理解命令时,就会卡住。在一些实验中,我们发现某些物体/指令超出了分布范围 (OOD),导致模型提前停止。为了展示 PaliGemma 模型的糟糕表现,我们在附录 C 中附上了一个视觉问答 (VQA) 示例。
只记得现在,但许多任务需要前后意识
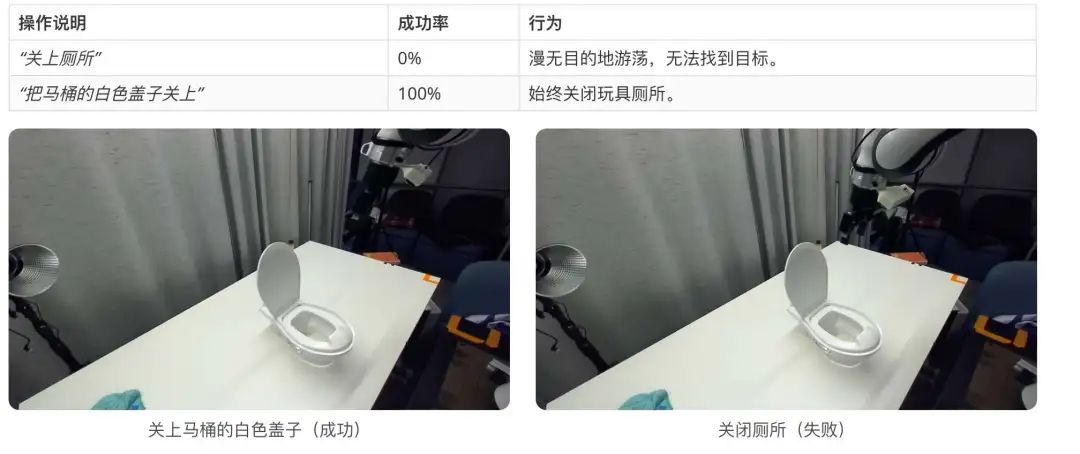
是一种无记忆策略,这意味着它的下一步动作仅取决于当前的摄像头图像,它永远不会“记住”之前做过的事情。这适用于单次、快速的动作(例如拿起一个杯子),但当任务需要多个协调步骤时可能会失效。例如,以下是一个需要多个步骤并在中间停止的铰链物体操作任务:
案例:“打开抽屉”→ 抓住把手后停止。 行为:伸出手,抓住把手......然后僵住了。
原因何在? 在训练数据中,大多数显示机器人握住手柄的帧都是空闲帧——没有任何移动。 它会根据给定的图像选择最常见的动作。所以,当它看到“手扶把手”时,根据它的经验,最安全的做法就是“什么也不做”。
我们该如何解决这个问题? 我们咨询了 Physical Intelligence 团队,答案是:稍微摇晃一下骰子。与其总是选择最有可能的(arg-max)动作,不如允许一些随机性——这被称为"sampling with temperature."。通过让偶尔选择第二个最可能的动作,它可能会开始拉动而不是冻结,并且抽屉最终滑开。
Token Decoding Edge Cases:
在推理过程中,将会抛出这个错误: Error decoding tokens: cannot reshape array of size 79 into shape (8) ,
对应 issue:https://github.com/Physical-Intelligence/openpi/issues/373
Pi0-fast 最初是在不同的机器人数据集上训练的,并且在 Droid 上进行微调时,它可能仍然会输出一些形状不正确的动作标记。这可能会导致 policy 生成格式错误的动作,从而导致机器人间歇性冻结。
但是,由于机器人继续查询策略,因此后续查询中会跳过该错误,从而使机器人恢复正常行为。
PI0 团队具体解释:
在推理(inference)阶段,策略(policy)有时会解码出“形状不正确”的动作(即动作向量的维度或结构不符合预期)。在实现中,遇到这种情况会直接让机器人“无动作”作为默认处理(-fast-droid 模式在遇到这种情况时,会默认执行“无动作”处理。),因为策略通常能很快恢复,重新输出形状正确的动作。
另一种解码策略是在解码出的形状不符合预期时,用零来填充(0-padding)离散余弦变换(DCT)系数数组。
他们之前试过这种做法,99% 的时候效果不错,因为通常较后面的 DCT 系数对整个动作块的总体形状影响较小。
但风险是,有时可能会出现完全错误解码的动作被填充(padding)后仍然在机器人上执行,从而导致不安全的行为。因此最终选择了“保持不动”作为默认策略,因为在实际应用中这是一个可以接受的折中方案。
不精确的空间推理
通常在高度的空间推理方面存在困难。例如,当被要求拾取一个物体并将其放入容器中时,该策略无法将物体提升到足够高的高度以越过容器的高度。这表明基于图像的策略存在一个缺陷:该 policy 缺乏一种精确的度量方法来确定夹持器与周围环境之间的距离。(这个比较典型,在复现 PI0 我也遇到过这个问题,目前的 VLA 并没有比较强的物理测距等能力,深度图也都普遍没用)

如图所示,机器人似乎认为夹持器足够高,因此在尝试将物体放入目标容器时会将其推入。现有的使用单目 RGB 图像的方法能够准确估算物体的大小以及物体高度与碗之间的距离。该模型应该能够理解,如果能够增加物体相对于容器的高度,它就能成功完成任务。
我们还尝试提示将夹持器抬高一点(例如,“将瓶子抬高到足够高/向上 10 厘米以避免碰撞……”),但这没有帮助。
当机器人被要求操作铰接式物体时,它就更难估计与侧视摄像头的距离,从而频繁发生碰撞。这一点在机器人与人类互动时尤其值得注意。
由于机器人没有安全约束,它有时会意外撞到/抓住用户的手,这可能会对用户造成伤害!

更重要的是,当被要求操作一个它在训练过程中没有见过的家用电器时,它会倾向于与设备碰撞或在试验过程中停止。如下所示,它不能使用我们实验室的咖啡机。

一种可能的解决方案是使用体素图和规划约束等技术。使用深度相机获取深度信息也有助于实现防撞。
此外,纯粹基于图像的策略缺乏触觉反馈。在我们的试验中,有时,机器人会对手指等精细物体施加过大的力,而对塑料瓶等较重物体施加的力又太小,无法牢牢抓住。利用触觉传感器或低强度力控制器来补充视觉,或许有助于克服这些问题。
Quirk(怪癖): Some interesting behaviors of PI0
Quirk 1: Prompt Engineering matters
调查了 Prompt 变化如何影响 policy 的行为,并发现的性能很大程度上取决于用户给出的 Prompt,为 Prompt 工程留下了空间。
需要仔细调整 Prompt 来操作机器人
当指令包含拼写错误、语法错误或含糊不清的措辞时,程序会卡住或失败。例如,当我们尝试让操纵铰接物体,我们可能需要尝试多个不同的提示来找到“分布内”指令。
没有语言目标的行为
当没有给出具体的语言指导时,默认与训练数据中最熟悉的对象进行交互:
给出像“dgbfzjkfhjilawhdfkAWHDKLWHADFiQAWFHqawipfjcasklfmdc”这样的无意义的文本,它会拾取记号笔 给定“xxx”,它会反复靠近立方体
在 DROID 数据集中,记号笔占物体的 16.67%,这可能会影响在仅提供视觉引导的情况下,如何拿起笔?默认行为很大程度上受到训练数据分布的影响。克服这种模糊性并拒绝无效指令仍然是一个持续存在的问题。

Quirk 2: How robust is under partial observability?
当视觉输入受到干扰时,它的稳定性如何?进行了几次遮挡摄像头和物体的测试。
相机遮挡实验:
设置:
任务:“拿起粉红色物体并将其放入碗中。” 摄像头:侧视(主)+ 腕戴式(副)。 阻塞场景:一个或两个摄像机被部分/完全遮挡。 测试时间:每个场景 4 次试验,每次试验 300 个步骤。


可以看出来腕部相机非常关键,屏蔽后直接 0% 了

目标遮挡实验:
设置:
任务:“捡起菠萝” 遮挡程度:无(完全可见)、50% 遮挡、100% 遮挡。 测试时间:每个场景 12 次试验,每次试验 300 rollouts。


我们的观察:
对腕式相机的依赖:
在我们的拾取和放置任务中,严重依赖腕部摄像头。即使侧摄像头被遮挡,它仍然可以工作。 腕部摄像头被遮挡,但侧面摄像头没有,效果更差。 视野稳定性:
可以容忍任务期间侧视摄像头位置和方向的变化 如果摄像头被遮挡然后又被解除遮挡,可以恢复。 部分可观测性下的常见故障模式:
腕部摄像头完全遮挡导致机器人冻结。 无记忆,可以自动回归地预测每帧的动作,因此如果有观察可用,它将能够继续执行任务。 效率低下,且仅限于场景的某些区域。这使得主动搜索环境变得困难。
结论:
评估表明 PI0 是一项前景光明的通用 policy:它在未见过的操作场景中展现了智能行为。然而,仍存在许多挑战——说我们“非常印象深刻”确实没错,但前提是要有正确的语境。别忘了,我们已经进行了大约 50 年的机器人研究。到目前为止,你还不能简单地下载别人的控制器,把它装到你自己的机器人上,然后指望它能做哪怕是简单的事情。如果可以做到这一点 ---**即使在简单任务上成功率只有 20-50%**,但这标志着一次重大飞跃。
正如“问题与怪癖” 一节所讨论的,实验表明,性能对 prompt 很敏感,并且该 policy 在指令遵循、细粒度操作和部分视野遮挡方面仍然存在困难。我们并不期望明天就能安装到每个人的家中,但我们希望看到更多进步。让机器人运行起来,让它一步步做合理的事情,虽然不一定每次都能完成任务,但它会朝着正确的方向前进。我们乐观地认为,持续的研究将解决这些问题,并使真正的通用机器人政策更接近实际应用。
附录 A:
硬件:
Franka Research 3 Arm:7-DOF 力敏机器人,有效载荷 3 公斤。
Robotiq 2F-85 gripper:双指夹持器,行程为 5 毫米,可调节力度控制。
相机:
侧视图:用于全局场景理解的 ZED 2 立体相机 腕戴式: ZED Mini,用于近距离物体操控 感知模式:纯 RGB(无深度校准)
计算
GPU 服务器:
GPU: 1x NVIDIA RTX A6000(48GB VRAM) CUDA 版本: 12.3 用法: 模型推理。
工作站
GPU: NVIDIA GeForce RTX 3080(16GB VRAM) CUDA 版本: 12.6 用途: DROID 低级控制。
PI0-FAST-DROID:
视觉语言模型:Paligemma 3B,用于空间和语义理解。 **FAST+**:频率空间动作序列标记器 (FAST),一款通用的机器人动作标记器,已基于 100 万条真实机器人动作轨迹进行训练。它可以用作黑盒标记器,适用于各种机器人动作序列,具有多种动作空间和控制频率。 训练数据:在 π 跨本体机器人数据集和 Open X-Embodiment 上进行预训练,在 DROID 数据集上进行微调。
附录 B: Detailed Results for Each Task
这里用平均完成度来衡量。应该是这些任务一共完成 300+ 次,然后平均的进度是 42%。目前也没有看到任何一个任务是 100%

特定任务表现
将任务分为 7 个类别:拾取和放置、倾倒、铰接物体、织物操作、YCB 基准、人机交互和咖啡机挑战。
对于每项任务,列出了进度分数和成功率。
注意,这里是氛围检查,而不是严格的评估,它仍然显示出一些优点和缺点。
对于每个类别,列出了示例 rollouts 和说明。
如果您想了解更多 policy rollouts,请查看 CoRL 论文:RoboArena:https://robo-arena.github.io/